R2C2-Coder: Enhancing and Benchmarking Real-world Repository-level Code Completion Abilities of Code Large Language Models

0

Sign in to get full access
Overview
- This paper introduces R2C2-Coder, a system that aims to enhance and benchmark the real-world repository-level code completion abilities of large language models (LLMs) used for programming tasks.
- The researchers address limitations of existing code completion models, which often struggle with long-range dependencies and repository-level context, by developing techniques to better leverage repository-level information.
- Key contributions include a new dataset and benchmarking framework for evaluating repository-level code completion, as well as novel methods for enhancing LLM performance on this task.
Plain English Explanation
The paper focuses on improving the ability of large language models (LLMs) to assist programmers by suggesting relevant code completions. Existing code completion models can sometimes fail to understand the broader context of a codebase, leading to less relevant or appropriate suggestions.
To address this, the researchers created R2C2-Coder, a system that leverages information from the full software repository, rather than just the immediate code context. This allows the model to better understand the programmer's intent and provide more useful code completion suggestions.
The key innovation is the development of techniques to effectively incorporate repository-level information into the LLM's code completion process. The researchers also created a new dataset and benchmarking framework to evaluate how well these models perform on real-world, repository-level code completion tasks.
By enhancing LLMs to better handle the full context of a codebase, the R2C2-Coder system aims to make code completion tools more powerful and helpful for programmers working on complex software projects.
Technical Explanation
The paper introduces the R2C2-Coder system, which builds on large language models (LLMs) to provide more effective repository-level code completion abilities. Existing code completion models often struggle with long-range dependencies and lack of broader context, which can lead to less relevant suggestions.
To address these limitations, the researchers developed several novel techniques to better leverage repository-level information. This includes methods for Dataflow-Guided Retrieval Augmentation and Class-Level Code Generation from Natural Language, which allow the LLM to understand the overall codebase structure and programmer intent.
The researchers also created a new benchmark dataset and evaluation framework, CodeEditorBench, to assess repository-level code completion performance. Additionally, they explored a Transformer-based Approach for Smart Invocation and Automatic Code Recommendation to further enhance the LLM's code completion capabilities.
Experiments show that the R2C2-Coder system significantly outperforms baseline models on the repository-level code completion task, demonstrating the value of the researchers' novel techniques for leveraging broader context.
Critical Analysis
The paper presents a well-designed and thorough approach to improving large language models' code completion abilities. The researchers have identified a clear limitation in existing models and have developed innovative techniques to address it.
One potential area for further research is the scalability of the R2C2-Coder system. The paper focuses on repository-level code completion, but it would be interesting to explore how the techniques scale to even larger codebases or multi-project environments. Additionally, the evaluation dataset, while comprehensive, may not fully capture the diversity of real-world programming tasks.
The paper also does not extensively discuss potential biases or limitations of the LLMs themselves, which could impact the performance and reliability of the R2C2-Coder system. Exploring ways to mitigate these biases would be a valuable avenue for future work.
Overall, the R2C2-Coder system represents a significant advancement in the field of code completion, and the techniques developed in this paper could have broader implications for leveraging contextual changes in multi-round code editing and other programming language tasks.
Conclusion
The R2C2-Coder paper introduces a novel approach to enhancing the real-world, repository-level code completion abilities of large language models. By developing techniques to effectively leverage broader context from the codebase, the researchers have demonstrated significant improvements in the performance of code completion systems.
This work has important implications for the development of more intelligent and useful programming assistants, which can better understand programmer intent and provide more relevant and helpful code suggestions. As large language models continue to advance, the R2C2-Coder system and its underlying principles could serve as a valuable foundation for further innovations in this space.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
R2C2-Coder: Enhancing and Benchmarking Real-world Repository-level Code Completion Abilities of Code Large Language Models
Ken Deng, Jiaheng Liu, He Zhu, Congnan Liu, Jingxin Li, Jiakai Wang, Peng Zhao, Chenchen Zhang, Yanan Wu, Xueqiao Yin, Yuanxing Zhang, Wenbo Su, Bangyu Xiang, Tiezheng Ge, Bo Zheng
Code completion models have made significant progress in recent years. Recently, repository-level code completion has drawn more attention in modern software development, and several baseline methods and benchmarks have been proposed. However, existing repository-level code completion methods often fall short of fully using the extensive context of a project repository, such as the intricacies of relevant files and class hierarchies. Besides, the existing benchmarks usually focus on limited code completion scenarios, which cannot reflect the repository-level code completion abilities well of existing methods. To address these limitations, we propose the R2C2-Coder to enhance and benchmark the real-world repository-level code completion abilities of code Large Language Models, where the R2C2-Coder includes a code prompt construction method R2C2-Enhance and a well-designed benchmark R2C2-Bench. Specifically, first, in R2C2-Enhance, we first construct the candidate retrieval pool and then assemble the completion prompt by retrieving from the retrieval pool for each completion cursor position. Second, based on R2C2 -Enhance, we can construct a more challenging and diverse R2C2-Bench with training, validation and test splits, where a context perturbation strategy is proposed to simulate the real-world repository-level code completion well. Extensive results on multiple benchmarks demonstrate the effectiveness of our R2C2-Coder.
Read more6/5/2024

0
Hierarchical Context Pruning: Optimizing Real-World Code Completion with Repository-Level Pretrained Code LLMs
Lei Zhang, Yunshui Li, Jiaming Li, Xiaobo Xia, Jiaxi Yang, Run Luo, Minzheng Wang, Longze Chen, Junhao Liu, Min Yang
Some recently developed code large language models (Code LLMs) have been pre-trained on repository-level code data (Repo-Code LLMs), enabling these models to recognize repository structures and utilize cross-file information for code completion. However, in real-world development scenarios, simply concatenating the entire code repository often exceeds the context window limits of these Repo-Code LLMs, leading to significant performance degradation. In this study, we conducted extensive preliminary experiments and analyses on six Repo-Code LLMs. The results indicate that maintaining the topological dependencies of files and increasing the code file content in the completion prompts can improve completion accuracy; pruning the specific implementations of functions in all dependent files does not significantly reduce the accuracy of completions. Based on these findings, we proposed a strategy named Hierarchical Context Pruning (HCP) to construct completion prompts with high informational code content. The HCP models the code repository at the function level, maintaining the topological dependencies between code files while removing a large amount of irrelevant code content, significantly reduces the input length for repository-level code completion. We applied the HCP strategy in experiments with six Repo-Code LLMs, and the results demonstrate that our proposed method can significantly enhance completion accuracy while substantially reducing the length of input. Our code and data are available at https://github.com/Hambaobao/HCP-Coder.
Read more6/28/2024

0
Enhancing Repository-Level Code Generation with Integrated Contextual Information
Zhiyuan Pan, Xing Hu, Xin Xia, Xiaohu Yang
Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, repository-level code generation presents unique challenges, particularly due to the need to utilize information spread across multiple files within a repository. Existing retrieval-based approaches sometimes fall short as they are limited in obtaining a broader and deeper repository context. In this paper, we present CatCoder, a novel code generation framework designed for statically typed programming languages. CatCoder enhances repository-level code generation by integrating relevant code and type context. Specifically, it leverages static analyzers to extract type dependencies and merges this information with retrieved code to create comprehensive prompts for LLMs. To evaluate the effectiveness of CatCoder, we adapt and construct benchmarks that include 199 Java tasks and 90 Rust tasks. The results show that CatCoder outperforms the RepoCoder baseline by up to 17.35%, in terms of pass@k score. Furthermore, the generalizability of CatCoder is assessed using various LLMs, including both code-specialized models and general-purpose models. Our findings indicate consistent performance improvements across all models, which underlines the practicality of CatCoder.
Read more6/6/2024
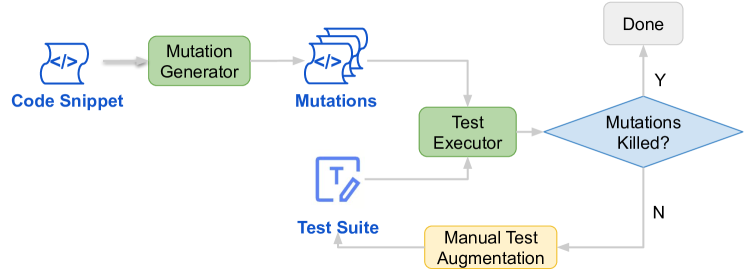
0
RepoMasterEval: Evaluating Code Completion via Real-World Repositories
Qinyun Wu, Chao Peng, Pengfei Gao, Ruida Hu, Haoyu Gan, Bo Jiang, Jinhe Tang, Zhiwen Deng, Zhanming Guan, Cuiyun Gao, Xia Liu, Ping Yang
With the growing reliance on automated code completion tools in software development, the need for robust evaluation benchmarks has become critical. However, existing benchmarks focus more on code generation tasks in function and class level and provide rich text description to prompt the model. By contrast, such descriptive prompt is commonly unavailable in real development and code completion can occur in wider range of situations such as in the middle of a function or a code block. These limitations makes the evaluation poorly align with the practical scenarios of code completion tools. In this paper, we propose RepoMasterEval, a novel benchmark for evaluating code completion models constructed from real-world Python and TypeScript repositories. Each benchmark datum is generated by masking a code snippet (ground truth) from one source code file with existing test suites. To improve test accuracy of model generated code, we employ mutation testing to measure the effectiveness of the test cases and we manually crafted new test cases for those test suites with low mutation score. Our empirical evaluation on 6 state-of-the-art models shows that test argumentation is critical in improving the accuracy of the benchmark and RepoMasterEval is able to report difference in model performance in real-world scenarios. The deployment of RepoMasterEval in a collaborated company for one month also revealed that the benchmark is useful to give accurate feedback during model training and the score is in high correlation with the model's performance in practice. Based on our findings, we call for the software engineering community to build more LLM benchmarks tailored for code generation tools taking the practical and complex development environment into consideration.
Read more8/9/2024