R4: Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models

0
Sign in to get full access
Overview
- Introduces a new model called "R4" (Reinforced Retriever-Reorder-Responder) for retrieval-augmented large language models
- Aims to improve the performance of large language models by incorporating a retrieval mechanism and reinforcement learning
- Focuses on tasks like question answering, where retrieving relevant information can boost model capabilities
Plain English Explanation
The paper presents a new approach called "R4" (Reinforced Retriever-Reorder-Responder) that aims to enhance the performance of large language models. Large language models are powerful AI systems that can generate human-like text, but they can sometimes struggle with tasks that require retrieving and integrating external information, such as answering specific questions.
The R4 model addresses this by incorporating a retrieval mechanism, which allows the model to search for and retrieve relevant information from a external database or knowledge base. This retrieved information is then used to supplement the language model's internal knowledge and improve its ability to generate accurate and informative responses.
Additionally, the R4 model uses reinforcement learning, a type of machine learning where the model is trained to learn optimal behaviors by receiving rewards or punishments for its actions. In this case, the model is trained to learn how to effectively retrieve, reorder, and respond to information in a way that maximizes the quality of the final output.
By combining these elements - retrieval, reordering, and reinforcement learning - the R4 model aims to outperform traditional large language models, especially on tasks that require accessing and integrating external information, such as question answering.
Technical Explanation
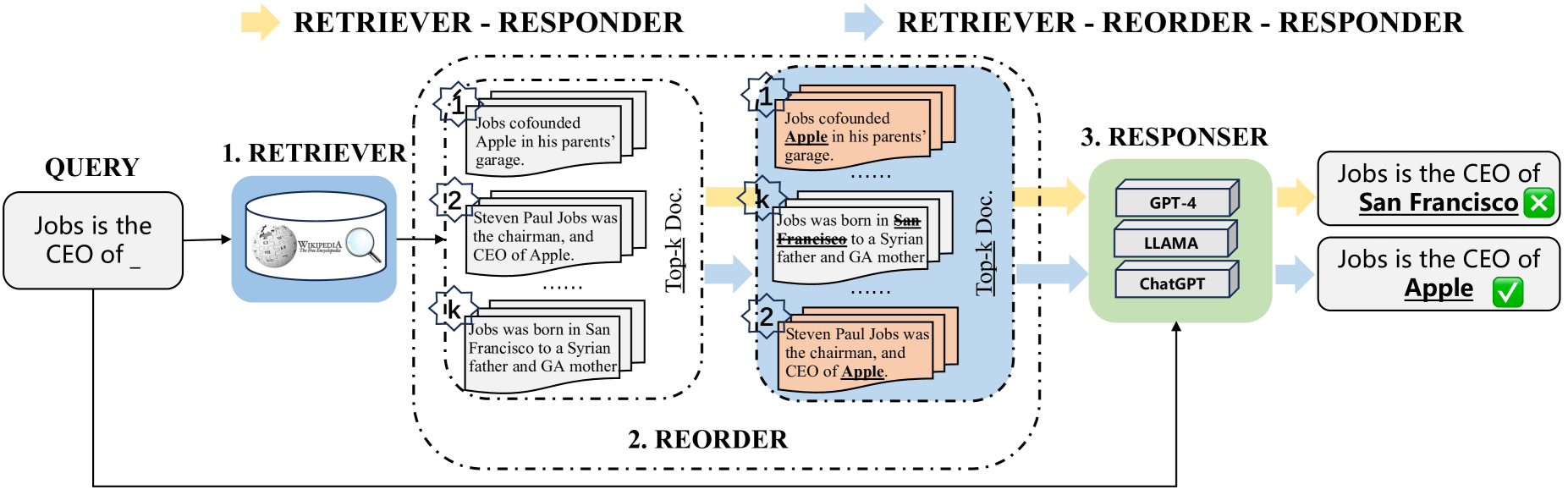
The R4 model consists of three main components:
-
Retriever: This component is responsible for finding and retrieving relevant information from an external knowledge base or database in response to a given input.
-
Reorderer: The reorderer takes the retrieved information and rearranges it into a coherent sequence that can be effectively used by the language model.
-
Responder: The responder is the language model itself, which generates the final output based on the input and the retrieved/reordered information.
The key innovation of the R4 model is the use of reinforcement learning to train the retriever and reorderer components. The model is trained to learn the optimal behaviors for retrieving and reordering information in a way that maximizes the quality of the final response, as measured by a reward signal.
This reinforcement learning approach allows the R4 model to adapt and improve its retrieval and reordering strategies over time, leading to better performance on tasks like question answering and information retrieval.
The paper also explores ways to personalize the R4 model by fine-tuning it on specific domains or user preferences, further enhancing its capabilities.
Critical Analysis
The R4 model represents a promising approach to improving the performance of large language models, particularly on tasks that require accessing and integrating external information. By incorporating a retrieval mechanism and using reinforcement learning, the model can learn to more effectively navigate and utilize relevant information, leading to better overall results.
However, the paper does not provide a detailed evaluation of the model's performance compared to other state-of-the-art approaches, such as the Retrieval-Augmented Generation (RAG) model. Additionally, the paper does not address potential limitations or drawbacks of the R4 approach, such as the computational overhead of the retrieval and reordering components or the challenges of scaling the model to larger knowledge bases.
Further research and evaluation would be needed to fully assess the strengths and weaknesses of the R4 model and its potential impact on the field of large language models and retrieval-augmented AI systems.
Conclusion
The R4 (Reinforced Retriever-Reorder-Responder) model presented in this paper represents a novel approach to enhancing the performance of large language models by incorporating a retrieval mechanism and reinforcement learning. By learning to effectively retrieve, reorder, and respond to relevant information, the R4 model has the potential to outperform traditional language models, especially on tasks that require accessing and integrating external knowledge, such as question answering and information retrieval.
While the paper provides a compelling proof-of-concept, further research and evaluation would be needed to fully assess the strengths, limitations, and potential impact of the R4 approach. Nonetheless, this work represents an important step forward in the ongoing efforts to improve the capabilities of large language models and personalize them to individual users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
R4: Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models
Taolin Zhang, Dongyang Li, Qizhou Chen, Chengyu Wang, Longtao Huang, Hui Xue, Xiaofeng He, Jun Huang
Retrieval-augmented large language models (LLMs) leverage relevant content retrieved by information retrieval systems to generate correct responses, aiming to alleviate the hallucination problem. However, existing retriever-responder methods typically append relevant documents to the prompt of LLMs to perform text generation tasks without considering the interaction of fine-grained structural semantics between the retrieved documents and the LLMs. This issue is particularly important for accurate response generation as LLMs tend to ``lose in the middle'' when dealing with input prompts augmented with lengthy documents. In this work, we propose a new pipeline named ``Reinforced Retriever-Reorder-Responder'' (R$^4$) to learn document orderings for retrieval-augmented LLMs, thereby further enhancing their generation abilities while the large numbers of parameters of LLMs remain frozen. The reordering learning process is divided into two steps according to the quality of the generated responses: document order adjustment and document representation enhancement. Specifically, document order adjustment aims to organize retrieved document orderings into beginning, middle, and end positions based on graph attention learning, which maximizes the reinforced reward of response quality. Document representation enhancement further refines the representations of retrieved documents for responses of poor quality via document-level gradient adversarial learning. Extensive experiments demonstrate that our proposed pipeline achieves better factual question-answering performance on knowledge-intensive tasks compared to strong baselines across various public datasets. The source codes and trained models will be released upon paper acceptance.
Read more5/7/2024

0
Retrieval-Pretrained Transformer: Long-range Language Modeling with Self-retrieval
Ohad Rubin, Jonathan Berant
Retrieval-augmented language models (LMs) have received much attention recently. However, typically the retriever is not trained jointly as a native component of the LM, but added post-hoc to an already-pretrained LM, which limits the ability of the LM and the retriever to adapt to one another. In this work, we propose the Retrieval-Pretrained Transformer (RPT), an architecture and training procedure for jointly training a retrieval-augmented LM from scratch and apply it to the task of modeling long texts. Given a recently generated text chunk in a long document, the LM computes query representations, which are then used to retrieve earlier chunks in the document, located potentially tens of thousands of tokens before. Information from retrieved chunks is fused into the LM representations to predict the next target chunk. We train the retriever component with a semantic objective, where the goal is to retrieve chunks that increase the probability of the next chunk, according to a reference LM. We evaluate RPT on four long-range language modeling tasks, spanning books, code, and mathematical writing, and demonstrate that RPT improves retrieval quality and subsequently perplexity across the board compared to strong baselines.
Read more7/23/2024
💬
0
ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
Jianghao Lin, Rong Shan, Chenxu Zhu, Kounianhua Du, Bo Chen, Shigang Quan, Ruiming Tang, Yong Yu, Weinan Zhang
With large language models (LLMs) achieving remarkable breakthroughs in natural language processing (NLP) domains, LLM-enhanced recommender systems have received much attention and have been actively explored currently. In this paper, we focus on adapting and empowering a pure large language model for zero-shot and few-shot recommendation tasks. First and foremost, we identify and formulate the lifelong sequential behavior incomprehension problem for LLMs in recommendation domains, i.e., LLMs fail to extract useful information from a textual context of long user behavior sequence, even if the length of context is far from reaching the context limitation of LLMs. To address such an issue and improve the recommendation performance of LLMs, we propose a novel framework, namely Retrieval-enhanced Large Language models (ReLLa) for recommendation tasks in both zero-shot and few-shot settings. For zero-shot recommendation, we perform semantic user behavior retrieval (SUBR) to improve the data quality of testing samples, which greatly reduces the difficulty for LLMs to extract the essential knowledge from user behavior sequences. As for few-shot recommendation, we further design retrieval-enhanced instruction tuning (ReiT) by adopting SUBR as a data augmentation technique for training samples. Specifically, we develop a mixed training dataset consisting of both the original data samples and their retrieval-enhanced counterparts. We conduct extensive experiments on three real-world public datasets to demonstrate the superiority of ReLLa compared with existing baseline models, as well as its capability for lifelong sequential behavior comprehension. To be highlighted, with only less than 10% training samples, few-shot ReLLa can outperform traditional CTR models that are trained on the entire training set (e.g., DCNv2, DIN, SIM). The code is available url{https://github.com/LaVieEnRose365/ReLLa}.
Read more6/26/2024

0
DSLR: Document Refinement with Sentence-Level Re-ranking and Reconstruction to Enhance Retrieval-Augmented Generation
Taeho Hwang, Soyeong Jeong, Sukmin Cho, SeungYoon Han, Jong C. Park
Recent advancements in Large Language Models (LLMs) have significantly improved their performance across various Natural Language Processing (NLP) tasks. However, LLMs still struggle with generating non-factual responses due to limitations in their parametric memory. Retrieval-Augmented Generation (RAG) systems address this issue by incorporating external knowledge with a retrieval module. Despite their successes, however, current RAG systems face challenges with retrieval failures and the limited ability of LLMs to filter out irrelevant information. Therefore, in this work, we propose DSLR (Document Refinement with Sentence-Level Re-ranking and Reconstruction), an unsupervised framework that decomposes retrieved documents into sentences, filters out irrelevant sentences, and reconstructs them again into coherent passages. We experimentally validate DSLR on multiple open-domain QA datasets and the results demonstrate that DSLR significantly enhances the RAG performance over conventional fixed-size passage. Furthermore, our DSLR enhances performance in specific, yet realistic scenarios without the need for additional training, providing an effective and efficient solution for refining retrieved documents in RAG systems.
Read more9/10/2024