Retrieval-Pretrained Transformer: Long-range Language Modeling with Self-retrieval

0

Sign in to get full access
Overview
- The paper explores a new approach to language modeling that involves self-retrieval.
- Retrieval-augmented language models have gained attention, but typically the retriever is not trained jointly as a native component of the language model.
- The authors propose a novel architecture that integrates the retriever as a core component, allowing the language model and retriever to be trained together.
Plain English Explanation
The paper describes a new way of building language models, which are AI systems that can generate human-like text. Typically, language models work by predicting the next word in a sequence based on the previous words.
However, the authors argue that this approach has limitations, especially when it comes to generating longer, more coherent text. To address this, they have developed a retrieval-augmented language model that can retrieve and incorporate relevant information from a database as part of the text generation process.
The key innovation is that the retriever component is trained jointly with the language model, rather than being added on afterwards. This allows the two components to work together seamlessly, with the retriever providing the language model with relevant information to improve the quality and coherence of the generated text.
Technical Explanation
The authors propose a novel retrieval-augmented language model architecture that integrates the retriever as a core component, allowing the language model and retriever to be trained together.
The model consists of three main components:
- Retriever: This module is responsible for retrieving relevant information from a database to assist the language model in generating text.
- Language Model: This is the primary text generation component, which predicts the next word in a sequence based on the previous words and the retrieved information.
- Interactor: This module coordinates the interaction between the retriever and language model, allowing them to work together effectively.
The key innovation is that the retriever is trained jointly with the language model, rather than being a separate, added-on component. This allows the two components to be optimized together, leading to better performance on long-range language modeling tasks.
The authors evaluate their model on several benchmark datasets and find that it outperforms traditional language models, particularly in terms of the coherence and quality of the generated text.
Critical Analysis
The paper presents a promising approach to improving language modeling by integrating the retriever as a core component. However, there are a few potential limitations and areas for further research:
- Scalability: The authors use a relatively small database for their experiments. It's unclear how the model would scale to larger databases or real-world knowledge bases.
- Interpretability: The integration of the retriever and language model may make it more difficult to understand the reasoning behind the generated text, as the retrieval process is not fully transparent.
- Task Generalization: The paper focuses on long-range language modeling tasks. It's unclear how well the approach would generalize to other language-related tasks, such as question answering or summarization.
Overall, the paper presents an innovative approach to language modeling that could lead to significant improvements in text generation. However, further research is needed to address the potential limitations and explore the broader applicability of the technique.
Conclusion
The paper introduces a novel retrieval-augmented language model that integrates the retriever as a core component, allowing the language model and retriever to be trained jointly. This approach has been shown to improve the coherence and quality of generated text, particularly in long-range language modeling tasks.
While the paper presents a promising approach, there are still some potential limitations and areas for further research, such as scalability, interpretability, and task generalization. Overall, the work contributes to the ongoing efforts to enhance the capabilities of language models and improve their ability to generate coherent and contextually relevant text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Retrieval-Pretrained Transformer: Long-range Language Modeling with Self-retrieval
Ohad Rubin, Jonathan Berant
Retrieval-augmented language models (LMs) have received much attention recently. However, typically the retriever is not trained jointly as a native component of the LM, but added post-hoc to an already-pretrained LM, which limits the ability of the LM and the retriever to adapt to one another. In this work, we propose the Retrieval-Pretrained Transformer (RPT), an architecture and training procedure for jointly training a retrieval-augmented LM from scratch and apply it to the task of modeling long texts. Given a recently generated text chunk in a long document, the LM computes query representations, which are then used to retrieve earlier chunks in the document, located potentially tens of thousands of tokens before. Information from retrieved chunks is fused into the LM representations to predict the next target chunk. We train the retriever component with a semantic objective, where the goal is to retrieve chunks that increase the probability of the next chunk, according to a reference LM. We evaluate RPT on four long-range language modeling tasks, spanning books, code, and mathematical writing, and demonstrate that RPT improves retrieval quality and subsequently perplexity across the board compared to strong baselines.
Read more7/23/2024

0
Retrieval-augmented code completion for local projects using large language models
Marko Hostnik, Marko Robnik-v{S}ikonja
The use of large language models (LLMs) is becoming increasingly widespread among software developers. However, privacy and computational requirements are problematic with commercial solutions and the use of LLMs. In this work, we focus on using LLMs with around 160 million parameters that are suitable for local execution and augmentation with retrieval from local projects. We train two models based on the transformer architecture, the generative model GPT-2 and the retrieval-adapted RETRO model, on open-source Python files, and empirically evaluate and compare them, confirming the benefits of vector embedding based retrieval. Further, we improve our models' performance with In-context retrieval-augmented generation, which retrieves code snippets based on the Jaccard similarity of tokens. We evaluate In-context retrieval-augmented generation on larger models and conclude that, despite its simplicity, the approach is more suitable than using the RETRO architecture. We highlight the key role of proper tokenization in achieving the full potential of LLMs in code completion.
Read more8/12/2024
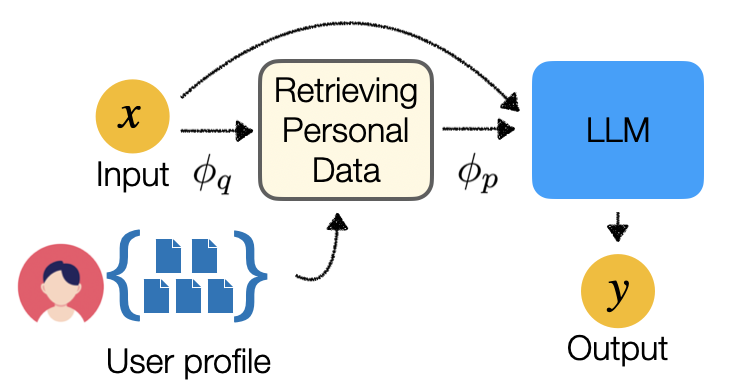
0
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation
Alireza Salemi, Surya Kallumadi, Hamed Zamani
This paper studies retrieval-augmented approaches for personalizing large language models (LLMs), which potentially have a substantial impact on various applications and domains. We propose the first attempt to optimize the retrieval models that deliver a limited number of personal documents to large language models for the purpose of personalized generation. We develop two optimization algorithms that solicit feedback from the downstream personalized generation tasks for retrieval optimization--one based on reinforcement learning whose reward function is defined using any arbitrary metric for personalized generation and another based on knowledge distillation from the downstream LLM to the retrieval model. This paper also introduces a pre- and post-generation retriever selection model that decides what retriever to choose for each LLM input. Extensive experiments on diverse tasks from the language model personalization (LaMP) benchmark reveal statistically significant improvements in six out of seven datasets.
Read more4/10/2024

155
Improving Retrieval Augmented Language Model with Self-Reasoning
Yuan Xia, Jingbo Zhou, Zhenhui Shi, Jun Chen, Haifeng Huang
The Retrieval-Augmented Language Model (RALM) has shown remarkable performance on knowledge-intensive tasks by incorporating external knowledge during inference, which mitigates the factual hallucinations inherited in large language models (LLMs). Despite these advancements, challenges persist in the implementation of RALMs, particularly concerning their reliability and traceability. To be specific, the irrelevant document retrieval may result in unhelpful response generation or even deteriorate the performance of LLMs, while the lack of proper citations in generated outputs complicates efforts to verify the trustworthiness of the models. To this end, we propose a novel self-reasoning framework aimed at improving the reliability and traceability of RALMs, whose core idea is to leverage reasoning trajectories generated by the LLM itself. The framework involves constructing self-reason trajectories with three processes: a relevance-aware process, an evidence-aware selective process, and a trajectory analysis process. We have evaluated our framework across four public datasets (two short-form QA datasets, one long-form QA dataset, and one fact verification dataset) to demonstrate the superiority of our method, which can outperform existing state-of-art models and can achieve comparable performance with GPT-4, while only using 2,000 training samples.
Read more8/6/2024