Radial Networks: Dynamic Layer Routing for High-Performance Large Language Models

0
Sign in to get full access
Overview
- This paper presents a novel neural network architecture called "Radial Networks" that enables dynamic routing of information through different layers of a large language model.
- The key idea is to introduce "radial layers" that can selectively activate or deactivate based on the input, allowing the model to adaptively allocate computational resources.
- This dynamic routing approach is aimed at improving the performance and efficiency of large language models, which are becoming increasingly complex and resource-intensive.
Plain English Explanation
The researchers have developed a new type of neural network called a "Radial Network" that can dynamically route information through different layers of a large language model. Large language models are powerful AI systems that can understand and generate human-like text, but they require a lot of computational resources to run.
The core innovation of Radial Networks is the introduction of "radial layers" that can selectively activate or deactivate based on the input data. This allows the model to adaptively allocate its computational resources, using more layers for complex inputs and fewer layers for simpler ones.
This dynamic routing approach is designed to improve the performance and efficiency of large language models. By only using the necessary computational resources for each input, Radial Networks can run faster and more cost-effectively than traditional large language models, which often waste resources on unnecessary computations.
The researchers hope that this technology will help make large language models more practical and accessible, as they become increasingly important for a wide range of applications in natural language processing and generation.
Technical Explanation
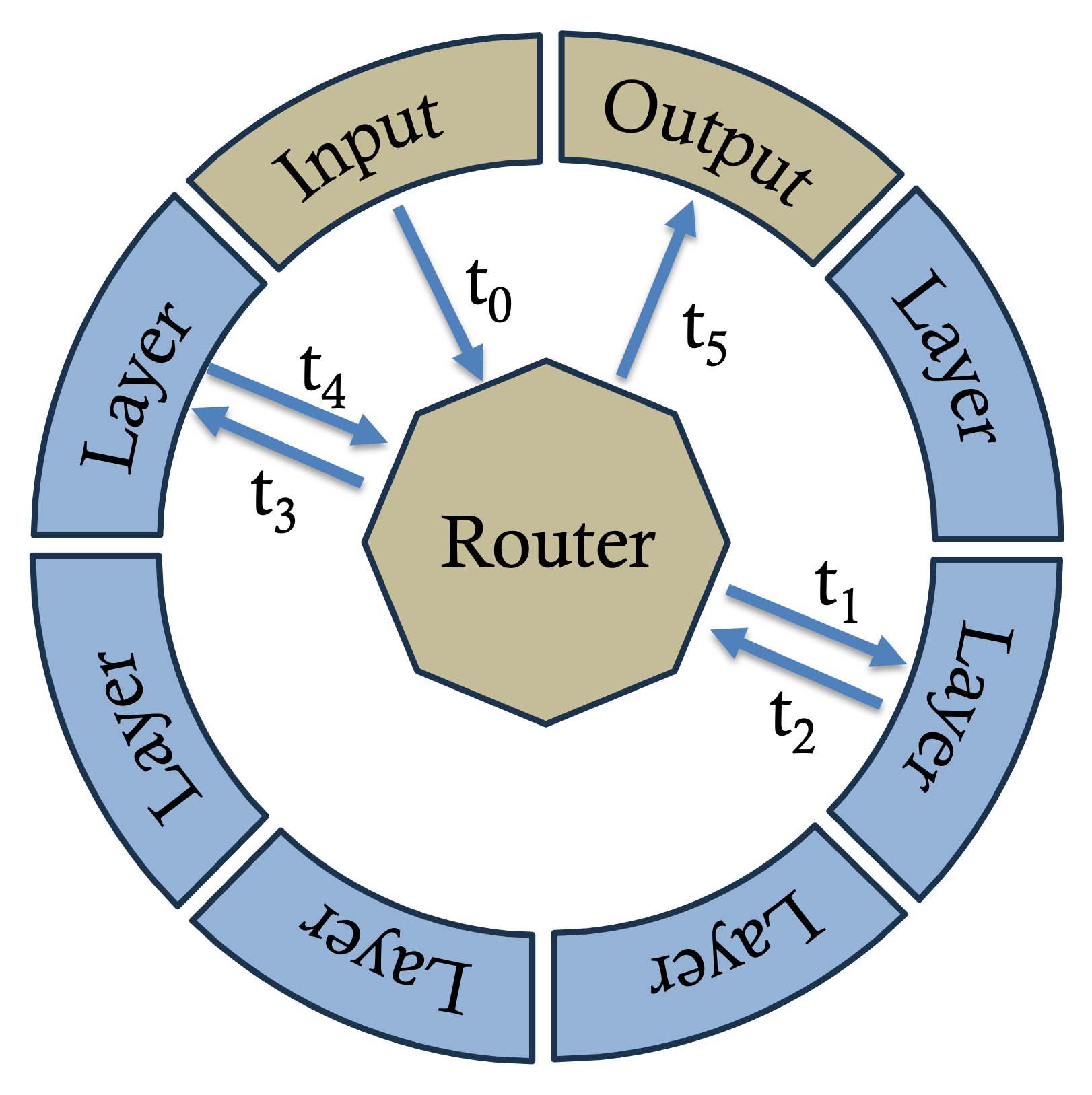
The key component of Radial Networks is the "radial layer", which is a novel type of neural network layer that can dynamically activate or deactivate based on the input data. These radial layers are integrated into a larger neural network architecture, allowing the model to selectively route information through different subsets of layers depending on the complexity of the input.
The researchers describe two main variants of Radial Networks:
- Radial Transformer: This architecture integrates radial layers into a standard Transformer model, enabling dynamic depth-wise routing.
- Radial Mixture-of-Experts: This architecture uses a mixture-of-experts approach, where each radial layer represents a different "expert" that can be selectively activated.
The paper presents extensive experiments on large language modeling benchmarks, demonstrating that Radial Networks can achieve superior performance compared to baseline models while using significantly fewer computational resources. The dynamic routing capability allows Radial Networks to adapt the model depth to the complexity of the input, resulting in more efficient inference.
The authors also provide insights into the behavior of Radial Networks, showing that the dynamic routing mechanism learns to activate different subsets of layers based on input characteristics, effectively implementing a form of "neural architecture search" within the model.
Critical Analysis
The Radial Network architecture proposed in this paper represents a promising approach to improving the efficiency and performance of large language models. By introducing dynamic routing capabilities, the model can adaptively allocate computational resources based on input complexity, which is a significant advance over traditional "one-size-fits-all" neural network architectures.
However, the paper does not address several important aspects that could be explored further. For example, the authors do not provide a comprehensive analysis of the types of inputs that trigger the activation or deactivation of different radial layers. Understanding these patterns could lead to valuable insights about the model's internal representations and decision-making processes.
Additionally, the paper does not explore the implications of the Radial Network approach for interpretability and explainability of large language models. The dynamic routing mechanism could potentially make the models more difficult to understand, unless accompanied by appropriate visualization and analysis tools.
Furthermore, the paper does not discuss the potential limitations or caveats of the Radial Network approach. For example, it is unclear how the dynamic routing mechanism would scale to even larger language models or how it would perform on more diverse or challenging language tasks.
Overall, the Radial Network architecture presented in this paper is a compelling and innovative approach to improving the efficiency of large language models. However, further research is needed to fully understand the implications and limitations of this technology, as well as its broader impact on the field of natural language processing.
Conclusion
The Radial Network architecture introduced in this paper represents a significant advancement in the field of large language models. By incorporating dynamic routing capabilities through "radial layers", the model can adaptively allocate computational resources based on the complexity of the input, leading to improved performance and efficiency.
The experiments presented in the paper demonstrate the potential of this approach, showing that Radial Networks can outperform traditional large language models while using fewer computational resources. This has important implications for the development of practical and accessible large language models, which are becoming increasingly important for a wide range of natural language processing applications.
While the Radial Network approach shows promise, further research is needed to fully understand its limitations and potential impact on the interpretability and explainability of large language models. Nonetheless, this paper represents an exciting step forward in the pursuit of more efficient and effective AI systems for natural language understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Radial Networks: Dynamic Layer Routing for High-Performance Large Language Models
Jordan Dotzel, Yash Akhauri, Ahmed S. AbouElhamayed, Carly Jiang, Mohamed Abdelfattah, Zhiru Zhang
Large language models (LLMs) often struggle with strict memory, latency, and power demands. To meet these demands, various forms of dynamic sparsity have been proposed that reduce compute on an input-by-input basis. These methods improve over static methods by exploiting the variance across individual inputs, which has steadily grown with the exponential increase in training data. Yet, the increasing depth within modern models, currently with hundreds of layers, has opened opportunities for dynamic layer sparsity, which skips the computation for entire layers. In this work, we explore the practicality of layer sparsity by profiling residual connections and establish the relationship between model depth and layer sparsity. For example, the residual blocks in the OPT-66B model have a median contribution of 5% to its output. We then take advantage of this dynamic sparsity and propose Radial Networks, which perform token-level routing between layers guided by a trained router module. These networks can be used in a post-training distillation from sequential networks or trained from scratch to co-learn the router and layer weights. They enable scaling to larger model sizes by decoupling the number of layers from the dynamic depth of the network, and their design allows for layer reuse. By varying the compute token by token, they reduce the overall resources needed for generating entire sequences. Overall, this leads to larger capacity networks with significantly lower compute and serving costs for large language models.
Read more4/9/2024
🌐
1
Rail-only: A Low-Cost High-Performance Network for Training LLMs with Trillion Parameters
Weiyang Wang, Manya Ghobadi, Kayvon Shakeri, Ying Zhang, Naader Hasani
This paper presents a low-cost network architecture for training large language models (LLMs) at hyperscale. We study the optimal parallelization strategy of LLMs and propose a novel datacenter network design tailored to LLM's unique communication pattern. We show that LLM training generates sparse communication patterns in the network and, therefore, does not require any-to-any full-bisection network to complete efficiently. As a result, our design eliminates the spine layer in traditional GPU clusters. We name this design a Rail-only network and demonstrate that it achieves the same training performance while reducing the network cost by 38% to 77% and network power consumption by 37% to 75% compared to a conventional GPU datacenter. Our architecture also supports Mixture-of-Expert (MoE) models with all-to-all communication through forwarding, with only 8.2% to 11.2% completion time overhead for all-to-all traffic. We study the failure robustness of Rail-only networks and provide insights into the performance impact of different network and training parameters.
Read more9/17/2024

0
LoRA-Switch: Boosting the Efficiency of Dynamic LLM Adapters via System-Algorithm Co-design
Rui Kong, Qiyang Li, Xinyu Fang, Qingtian Feng, Qingfeng He, Yazhu Dong, Weijun Wang, Yuanchun Li, Linghe Kong, Yunxin Liu
Recent literature has found that an effective method to customize or further improve large language models (LLMs) is to add dynamic adapters, such as low-rank adapters (LoRA) with Mixture-of-Experts (MoE) structures. Though such dynamic adapters incur modest computational complexity, they surprisingly lead to huge inference latency overhead, slowing down the decoding speed by 2.5+ times. In this paper, we analyze the fine-grained costs of the dynamic adapters and find that the fragmented CUDA kernel calls are the root cause. Therefore, we propose LoRA-Switch, a system-algorithm co-designed architecture for efficient dynamic adapters. Unlike most existing dynamic structures that adopt layer-wise or block-wise dynamic routing, LoRA-Switch introduces a token-wise routing mechanism. It switches the LoRA adapters and weights for each token and merges them into the backbone for inference. For efficiency, this switching is implemented with an optimized CUDA kernel, which fuses the merging operations for all LoRA adapters at once. Based on experiments with popular open-source LLMs on common benchmarks, our approach has demonstrated similar accuracy improvement as existing dynamic adapters, while reducing the decoding latency by more than 2.4 times.
Read more5/29/2024

0
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, Ion Stoica
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance. Our evaluation on widely-recognized benchmarks shows that our approach significantly reduces costs-by over 2 times in certain cases-without compromising the quality of responses. Interestingly, our router models also demonstrate significant transfer learning capabilities, maintaining their performance even when the strong and weak models are changed at test time. This highlights the potential of these routers to provide a cost-effective yet high-performance solution for deploying LLMs.
Read more7/23/2024