Interpreting End-to-End Deep Learning Models for Speech Source Localization Using Layer-wise Relevance Propagation

0
🤿
Sign in to get full access
Overview
- This paper investigates using eXplainable Artificial Intelligence (XAI) techniques to understand the inner workings of deep learning models for speech source localization.
- The researchers use the Layer-wise Relevance Propagation (LRP) method to analyze two state-of-the-art speech localization models.
- LRP helps determine which parts of the input audio signals are most important for the models' output predictions.
Plain English Explanation
Deep learning models have become widely used in signal processing tasks like speech source localization. However, these models are often treated as "black boxes" - their internal decision-making processes are not well understood.
The researchers in this paper wanted to shed light on how these models work by applying eXplainable AI (XAI) techniques. Specifically, they used a method called Layer-wise Relevance Propagation (LRP) to analyze two state-of-the-art speech localization models.
LRP allows the researchers to determine which parts of the input audio signals are most important for the models' output predictions of the speaker's location. By applying LRP, they found that both models were effectively "denoising" and "dereverberation" the audio signals to extract statistical patterns that allowed more accurate localization.
To further demonstrate this, the researchers compared the time delay estimates obtained from the original microphone signals to those obtained from the "relevant" signals identified by LRP. The LRP-derived signals produced more accurate time delay estimates, confirming that the models were learning to focus on the most important audio cues for localization.
Technical Explanation
The paper evaluates the use of Layer-wise Relevance Propagation (LRP) to analyze the inner workings of two deep learning models for end-to-end speech source localization.
LRP is an XAI technique that aims to determine which parts of the input (in this case, the microphone signals) are most relevant for the model's output predictions (the speaker's 3D coordinates). The researchers apply LRP to two different speech localization models with varying architectural complexity.
By inspecting the relevance scores assigned by LRP to different parts of the input features, the authors discover that both models are effectively performing denoising and dereverberation of the microphone signals. This allows the models to compute more accurate statistical correlations between the microphone signals and the true speaker location.
To further validate this finding, the researchers estimate the Time-Difference of Arrivals (TDoAs) using both the original microphone signals and the "relevant" signals identified by LRP. They show that the TDoA estimates obtained from the LRP-derived signals are more accurate, confirming that the models are indeed learning to focus on the most informative parts of the audio for localization.
Critical Analysis
The paper provides a thorough and insightful analysis of how deep learning models for speech source localization can be better understood using XAI techniques like LRP. The researchers demonstrate the value of opening up these "black box" models to gain a deeper understanding of their inner workings.
One limitation of the study is that it only considers two specific model architectures. While the findings likely generalize to other speech localization models, it would be useful to see the analysis extended to a wider range of model types and training datasets.
Additionally, the paper does not delve into the potential practical implications of this work. Understanding how these models operate could lead to more robust and reliable speech localization systems, but the authors do not explore this aspect in depth.
Overall, this research makes a valuable contribution to the field of explainable AI for audio and speech applications. The use of LRP to unpack the decision-making of deep learning models is an important step towards building more transparent and trustworthy signal processing systems.
Conclusion
This paper demonstrates the application of eXplainable AI (XAI) techniques, specifically Layer-wise Relevance Propagation (LRP), to understand the inner workings of deep learning models for speech source localization.
The key findings show that the analyzed models are effectively performing denoising and dereverberation of the input audio signals to extract the most relevant statistical patterns for accurately localizing the speaker. This insight was validated by comparing time delay estimates obtained from the original microphone signals versus the "relevant" signals identified by LRP.
The use of XAI methods like LRP represents an important step towards making deep learning-based signal processing systems more transparent and trustworthy. By understanding how these models operate, researchers and practitioners can work towards developing more robust and reliable applications in areas like speech processing, sound event localization, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Interpreting End-to-End Deep Learning Models for Speech Source Localization Using Layer-wise Relevance Propagation
Luca Comanducci, Fabio Antonacci, Augusto Sarti
Deep learning models are widely applied in the signal processing community, yet their inner working procedure is often treated as a black box. In this paper, we investigate the use of eXplainable Artificial Intelligence (XAI) techniques to learning-based end-to-end speech source localization models. We consider the Layer-wise Relevance Propagation (LRP) technique, which aims to determine which parts of the input are more important for the output prediction. Using LRP we analyze two state-of-the-art models, of differing architectural complexity that map audio signals acquired by the microphones to the cartesian coordinates of the source. Specifically, we inspect the relevance associated with the input features of the two models and discover that both networks denoise and de-reverberate the microphone signals to compute more accurate statistical correlations between them and consequently localize the sources. To further demonstrate this fact, we estimate the Time-Difference of Arrivals (TDoAs) via the Generalized Cross Correlation with Phase Transform (GCC-PHAT) using both microphone signals and relevance signals extracted from the two networks and show that through the latter we obtain more accurate time-delay estimation results.
Read more4/29/2024

0
AttnLRP: Attention-Aware Layer-Wise Relevance Propagation for Transformers
Reduan Achtibat, Sayed Mohammad Vakilzadeh Hatefi, Maximilian Dreyer, Aakriti Jain, Thomas Wiegand, Sebastian Lapuschkin, Wojciech Samek
Large Language Models are prone to biased predictions and hallucinations, underlining the paramount importance of understanding their model-internal reasoning process. However, achieving faithful attributions for the entirety of a black-box transformer model and maintaining computational efficiency is an unsolved challenge. By extending the Layer-wise Relevance Propagation attribution method to handle attention layers, we address these challenges effectively. While partial solutions exist, our method is the first to faithfully and holistically attribute not only input but also latent representations of transformer models with the computational efficiency similar to a single backward pass. Through extensive evaluations against existing methods on LLaMa 2, Mixtral 8x7b, Flan-T5 and vision transformer architectures, we demonstrate that our proposed approach surpasses alternative methods in terms of faithfulness and enables the understanding of latent representations, opening up the door for concept-based explanations. We provide an LRP library at https://github.com/rachtibat/LRP-eXplains-Transformers.
Read more6/11/2024
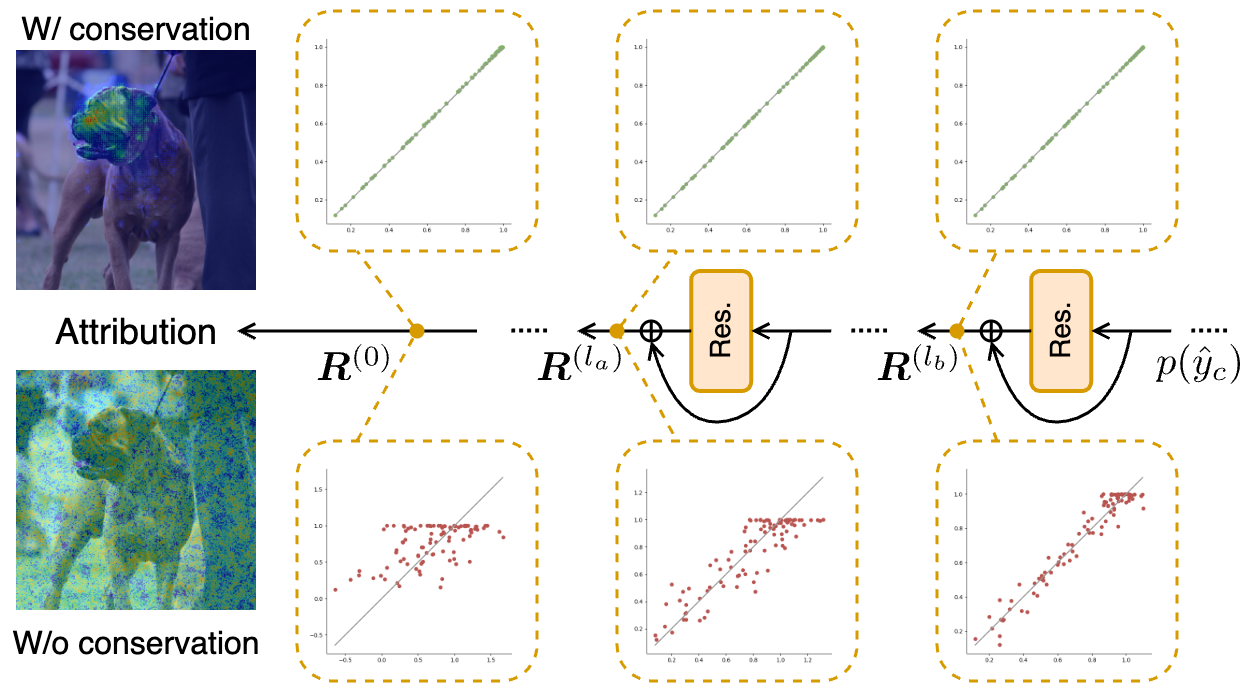
0
Layer-Wise Relevance Propagation with Conservation Property for ResNet
Seitaro Otsuki, Tsumugi Iida, F'elix Doublet, Tsubasa Hirakawa, Takayoshi Yamashita, Hironobu Fujiyoshi, Komei Sugiura
The transparent formulation of explanation methods is essential for elucidating the predictions of neural networks, which are typically black-box models. Layer-wise Relevance Propagation (LRP) is a well-established method that transparently traces the flow of a model's prediction backward through its architecture by backpropagating relevance scores. However, the conventional LRP does not fully consider the existence of skip connections, and thus its application to the widely used ResNet architecture has not been thoroughly explored. In this study, we extend LRP to ResNet models by introducing Relevance Splitting at points where the output from a skip connection converges with that from a residual block. Our formulation guarantees the conservation property throughout the process, thereby preserving the integrity of the generated explanations. To evaluate the effectiveness of our approach, we conduct experiments on ImageNet and the Caltech-UCSD Birds-200-2011 dataset. Our method achieves superior performance to that of baseline methods on standard evaluation metrics such as the Insertion-Deletion score while maintaining its conservation property. We will release our code for further research at https://5ei74r0.github.io/lrp-for-resnet.page/
Read more7/15/2024

0
Sparse Explanations of Neural Networks Using Pruned Layer-Wise Relevance Propagation
Paulo Yanez Sarmiento, Simon Witzke, Nadja Klein, Bernhard Y. Renard
Explainability is a key component in many applications involving deep neural networks (DNNs). However, current explanation methods for DNNs commonly leave it to the human observer to distinguish relevant explanations from spurious noise. This is not feasible anymore when going from easily human-accessible data such as images to more complex data such as genome sequences. To facilitate the accessibility of DNN outputs from such complex data and to increase explainability, we present a modification of the widely used explanation method layer-wise relevance propagation. Our approach enforces sparsity directly by pruning the relevance propagation for the different layers. Thereby, we achieve sparser relevance attributions for the input features as well as for the intermediate layers. As the relevance propagation is input-specific, we aim to prune the relevance propagation rather than the underlying model architecture. This allows to prune different neurons for different inputs and hence, might be more appropriate to the local nature of explanation methods. To demonstrate the efficacy of our method, we evaluate it on two types of data, images and genomic sequences. We show that our modification indeed leads to noise reduction and concentrates relevance on the most important features compared to the baseline.
Read more4/23/2024