RAG-RLRC-LaySum at BioLaySumm: Integrating Retrieval-Augmented Generation and Readability Control for Layman Summarization of Biomedical Texts

0
🛸
Sign in to get full access
Overview
- This paper introduces the RAG-RLRC-LaySum framework, which aims to make complex biomedical research more understandable to the general public through advanced Natural Language Processing (NLP) techniques.
- The framework combines Retrieval Augmented Generation (RAG) for precise and relevant lay summaries, and Reinforcement Learning for Readability Control (RLRC) to improve the readability of scientific content for non-specialists.
- Evaluations on public datasets show that the RAG-RLRC-LaySum framework outperforms the Plain Gemini model, with a 20% increase in readability scores, a 15% improvement in ROUGE-2 relevance scores, and a 10% enhancement in factual accuracy.
Plain English Explanation
The paper introduces a new system called RAG-RLRC-LaySum that aims to make complex biomedical research easier for regular people to understand. It uses advanced language processing techniques to create summaries that are both accurate and easy to read.
The system has two key parts:
-
Retrieval Augmented Generation (RAG): This part uses information from multiple sources to generate summaries that are precise and relevant to the original research. It helps ensure the summaries cover the important points.
-
Reinforcement Learning for Readability Control (RLRC): This part focuses on making the summaries easier for non-experts to understand. It adjusts the language and style to be more accessible, without losing the key details.
The researchers tested this system on two public datasets of scientific papers. Compared to a simpler model, the RAG-RLRC-LaySum framework showed a 20% improvement in readability, a 15% increase in summary relevance, and a 10% boost in factual accuracy. This suggests the system can effectively translate complex scientific knowledge into forms the general public can engage with.
Technical Explanation
The paper introduces the RAG-RLRC-LaySum framework, which leverages Retrieval Augmented Generation (RAG) and Reinforcement Learning for Readability Control (RLRC) to generate lay summaries of biomedical research that are both precise and easy to understand.
The RAG component retrieves relevant information from multiple knowledge sources to enhance the accuracy and relevance of the generated summaries. This retrieval-augmented approach helps ensure the summaries cover the key points of the original research.
The RLRC strategy then adjusts the language and style of the summaries to improve readability for non-specialists. By incorporating reinforcement learning, the system can optimize the summaries to strike a balance between technical precision and accessibility.
Evaluations on the PLOS and eLife datasets show that the RAG-RLRC-LaySum framework outperforms the Plain Gemini model, with a 20% increase in readability scores, a 15% improvement in ROUGE-2 relevance scores, and a 10% enhancement in factual accuracy.
Critical Analysis
The paper presents a promising approach to democratizing scientific knowledge by making complex biomedical research more accessible to the general public. However, some potential limitations and areas for further research are worth considering.
While the evaluations demonstrate significant improvements in readability, relevance, and factual accuracy compared to the Plain Gemini model, it's unclear how the system would perform against more advanced baselines or state-of-the-art models for lay summarization. Expanding the scope of the evaluation to include a wider range of benchmarks could provide a more comprehensive assessment of the framework's capabilities.
Additionally, the paper does not delve into the specific challenges or trade-offs involved in balancing technical precision and readability. Further exploration of these nuances, as well as the potential biases or errors introduced by the retrieval and readability optimization components, could help guide future research and development in this area.
Ultimately, the RAG-RLRC-LaySum framework represents an important step towards making scientific knowledge more accessible to the public. Continued refinement and evaluation of this approach, as well as exploration of complementary techniques, could lead to even more effective solutions for bridging the gap between complex research and everyday understanding.
Conclusion
The RAG-RLRC-LaySum framework introduced in this paper offers a promising approach to democratizing biomedical research by generating lay summaries that are both precise and accessible. Through the integration of advanced NLP techniques like Retrieval Augmented Generation and Reinforcement Learning for Readability Control, the system achieves significant improvements in readability, relevance, and factual accuracy over existing models.
By making complex scientific knowledge more understandable to the general public, the RAG-RLRC-LaySum framework has the potential to enhance public engagement with biomedical discoveries and foster a more informed and scientifically literate society. As this area of research continues to evolve, further advancements in lay summarization techniques could lead to even greater strides in scientific communication and knowledge dissemination.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
RAG-RLRC-LaySum at BioLaySumm: Integrating Retrieval-Augmented Generation and Readability Control for Layman Summarization of Biomedical Texts
Yuelyu Ji, Zhuochun Li, Rui Meng, Sonish Sivarajkumar, Yanshan Wang, Zeshui Yu, Hui Ji, Yushui Han, Hanyu Zeng, Daqing He
This paper introduces the RAG-RLRC-LaySum framework, designed to make complex biomedical research understandable to laymen through advanced Natural Language Processing (NLP) techniques. Our Retrieval Augmented Generation (RAG) solution, enhanced by a reranking method, utilizes multiple knowledge sources to ensure the precision and pertinence of lay summaries. Additionally, our Reinforcement Learning for Readability Control (RLRC) strategy improves readability, making scientific content comprehensible to non-specialists. Evaluations using the publicly accessible PLOS and eLife datasets show that our methods surpass Plain Gemini model, demonstrating a 20% increase in readability scores, a 15% improvement in ROUGE-2 relevance scores, and a 10% enhancement in factual accuracy. The RAG-RLRC-LaySum framework effectively democratizes scientific knowledge, enhancing public engagement with biomedical discoveries.
Read more6/21/2024
0
Towards a Robust Retrieval-Based Summarization System
Shengjie Liu, Jing Wu, Jingyuan Bao, Wenyi Wang, Naira Hovakimyan, Christopher G Healey
This paper describes an investigation of the robustness of large language models (LLMs) for retrieval augmented generation (RAG)-based summarization tasks. While LLMs provide summarization capabilities, their performance in complex, real-world scenarios remains under-explored. Our first contribution is LogicSumm, an innovative evaluation framework incorporating realistic scenarios to assess LLM robustness during RAG-based summarization. Based on limitations identified by LogiSumm, we then developed SummRAG, a comprehensive system to create training dialogues and fine-tune a model to enhance robustness within LogicSumm's scenarios. SummRAG is an example of our goal of defining structured methods to test the capabilities of an LLM, rather than addressing issues in a one-off fashion. Experimental results confirm the power of SummRAG, showcasing improved logical coherence and summarization quality. Data, corresponding model weights, and Python code are available online.
Read more4/1/2024

0
BioRAG: A RAG-LLM Framework for Biological Question Reasoning
Chengrui Wang, Qingqing Long, Meng Xiao, Xunxin Cai, Chengjun Wu, Zhen Meng, Xuezhi Wang, Yuanchun Zhou
The question-answering system for Life science research, which is characterized by the rapid pace of discovery, evolving insights, and complex interactions among knowledge entities, presents unique challenges in maintaining a comprehensive knowledge warehouse and accurate information retrieval. To address these issues, we introduce BioRAG, a novel Retrieval-Augmented Generation (RAG) with the Large Language Models (LLMs) framework. Our approach starts with parsing, indexing, and segmenting an extensive collection of 22 million scientific papers as the basic knowledge, followed by training a specialized embedding model tailored to this domain. Additionally, we enhance the vector retrieval process by incorporating a domain-specific knowledge hierarchy, which aids in modeling the intricate interrelationships among each query and context. For queries requiring the most current information, BioRAG deconstructs the question and employs an iterative retrieval process incorporated with the search engine for step-by-step reasoning. Rigorous experiments have demonstrated that our model outperforms fine-tuned LLM, LLM with search engines, and other scientific RAG frameworks across multiple life science question-answering tasks.
Read more8/15/2024
0
WisPerMed at BioLaySumm: Adapting Autoregressive Large Language Models for Lay Summarization of Scientific Articles
Tabea M. G. Pakull, Hendrik Damm, Ahmad Idrissi-Yaghir, Henning Schafer, Peter A. Horn, Christoph M. Friedrich
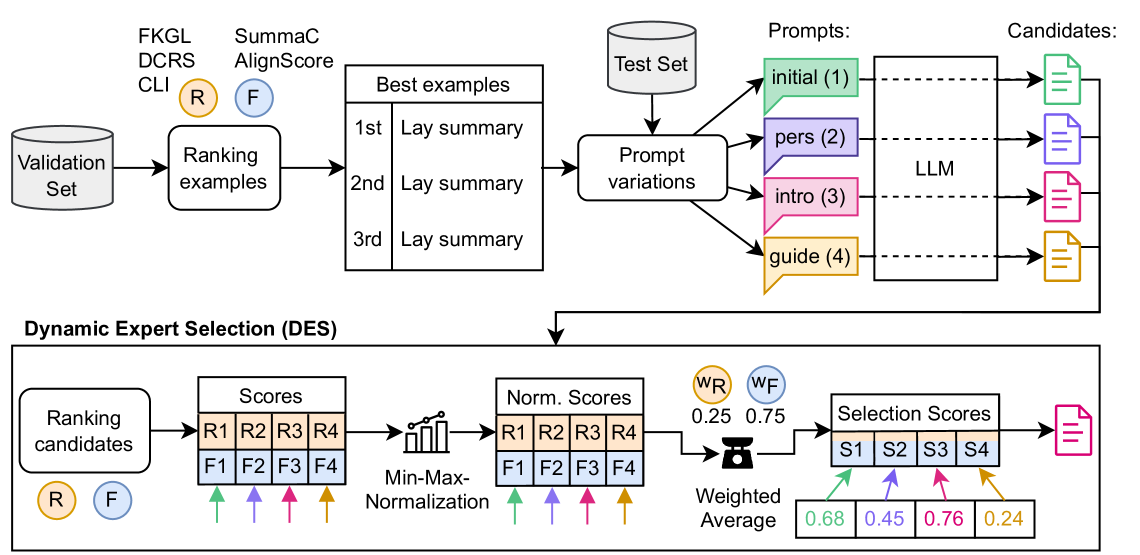
This paper details the efforts of the WisPerMed team in the BioLaySumm2024 Shared Task on automatic lay summarization in the biomedical domain, aimed at making scientific publications accessible to non-specialists. Large language models (LLMs), specifically the BioMistral and Llama3 models, were fine-tuned and employed to create lay summaries from complex scientific texts. The summarization performance was enhanced through various approaches, including instruction tuning, few-shot learning, and prompt variations tailored to incorporate specific context information. The experiments demonstrated that fine-tuning generally led to the best performance across most evaluated metrics. Few-shot learning notably improved the models' ability to generate relevant and factually accurate texts, particularly when using a well-crafted prompt. Additionally, a Dynamic Expert Selection (DES) mechanism to optimize the selection of text outputs based on readability and factuality metrics was developed. Out of 54 participants, the WisPerMed team reached the 4th place, measured by readability, factuality, and relevance. Determined by the overall score, our approach improved upon the baseline by approx. 5.5 percentage points and was only approx 1.5 percentage points behind the first place.
Read more9/24/2024