RAGE Against the Machine: Retrieval-Augmented LLM Explanations

0
🤖
Sign in to get full access
Overview
- This paper presents RAGE, an interactive tool for explaining Large Language Models (LLMs) that can query external sources and incorporate relevant information into their inputs.
- The explanations provided by RAGE are "counterfactual," meaning they identify parts of the input context that, when removed, change the model's answer to a given question.
- RAGE includes pruning methods to navigate the vast space of possible explanations, allowing users to understand the provenance of the model's answers.
Plain English Explanation
RAGE is a tool that helps explain how Large Language Models (LLMs) work. LLMs are advanced AI systems that can understand and generate human-like text. But they can be complex and difficult to understand.
RAGE is designed to make LLMs more transparent. It shows how LLMs come up with their answers to questions. For example, if an LLM is asked a question, RAGE can identify parts of the information the LLM used that, if removed, would change the answer. This helps users understand the reasoning behind the LLM's response.
RAGE also includes methods to efficiently explore the many possible explanations for an LLM's answer. This allows users to see where the LLM is pulling information from and how it is using that information to formulate its response.
Overall, RAGE aims to make LLMs more transparent and interpretable, which is important as these models become more widely used in areas like medical consultations and information retrieval.
Technical Explanation
RAGE is an interactive tool designed to explain the inner workings of Large Language Models (LLMs) that have been augmented with retrieval capabilities. These LLMs can access and incorporate relevant information from external sources into their input context when generating responses to questions or prompts.
The key innovation of RAGE is its use of "counterfactual" explanations. These explanations identify specific parts of the input context that, when removed, cause the LLM to change its answer. By analyzing these counterfactual inputs, RAGE allows users to understand the reasoning behind the model's responses and the information it is relying on.
To navigate the vast space of possible explanations, RAGE employs pruning methods that efficiently explore different variations of the input context. This enables users to quickly view the provenance of the LLM's produced answers and understand how the model is leveraging external information.
The design and evaluation of RAGE demonstrate its effectiveness in improving the robustness and interpretability of retrieval-augmented language models.
Critical Analysis
The paper provides a compelling approach to explaining the inner workings of retrieval-augmented language models. By focusing on counterfactual explanations, RAGE offers a novel way to analyze how these models integrate external information to generate their responses.
One potential limitation is the scalability of the pruning methods used to explore the space of possible explanations. As the complexity of the input context increases, the computational burden of generating and evaluating counterfactual explanations may become a challenge.
Additionally, the paper does not address the potential biases or errors that may be introduced when the LLM incorporates external information. It would be valuable to understand how RAGE could help users identify and mitigate such issues, especially in sensitive domains like medical consultations.
Overall, RAGE represents an important step towards making retrieval-augmented language models more transparent and interpretable. Further research on scaling the approach and addressing potential risks could strengthen its applicability in real-world scenarios.
Conclusion
This paper presents RAGE, an innovative tool for explaining the inner workings of retrieval-augmented language models. By using counterfactual explanations, RAGE allows users to understand how these models integrate external information to generate their responses.
The pruning methods used in RAGE enable efficient exploration of the vast space of possible explanations, helping users understand the provenance of the model's answers. This increased transparency and interpretability is crucial as these advanced language models become more widely used in domains such as medical consultations and information retrieval.
While the paper identifies some potential limitations, the RAGE approach represents a significant step forward in making retrieval-augmented language models more robust and trustworthy. Continued research in this area could lead to further advancements in the explainability and reliability of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
RAGE Against the Machine: Retrieval-Augmented LLM Explanations
Joel Rorseth, Parke Godfrey, Lukasz Golab, Divesh Srivastava, Jaroslaw Szlichta
This paper demonstrates RAGE, an interactive tool for explaining Large Language Models (LLMs) augmented with retrieval capabilities; i.e., able to query external sources and pull relevant information into their input context. Our explanations are counterfactual in the sense that they identify parts of the input context that, when removed, change the answer to the question posed to the LLM. RAGE includes pruning methods to navigate the vast space of possible explanations, allowing users to view the provenance of the produced answers.
Read more5/24/2024
💬
0
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
Read more6/18/2024
0
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Harsh Thakkar, Alyssa Lee, Eden Chung, Natan Vidra
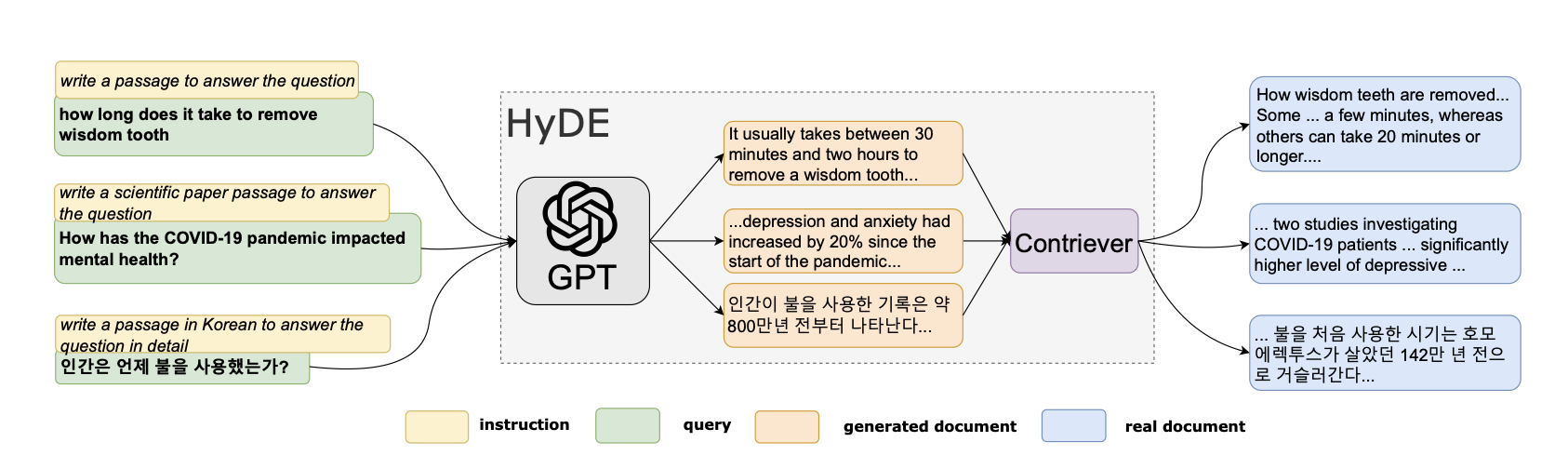
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
Read more8/2/2024
0
StackRAG Agent: Improving Developer Answers with Retrieval-Augmented Generation
Davit Abrahamyan, Fatemeh H. Fard
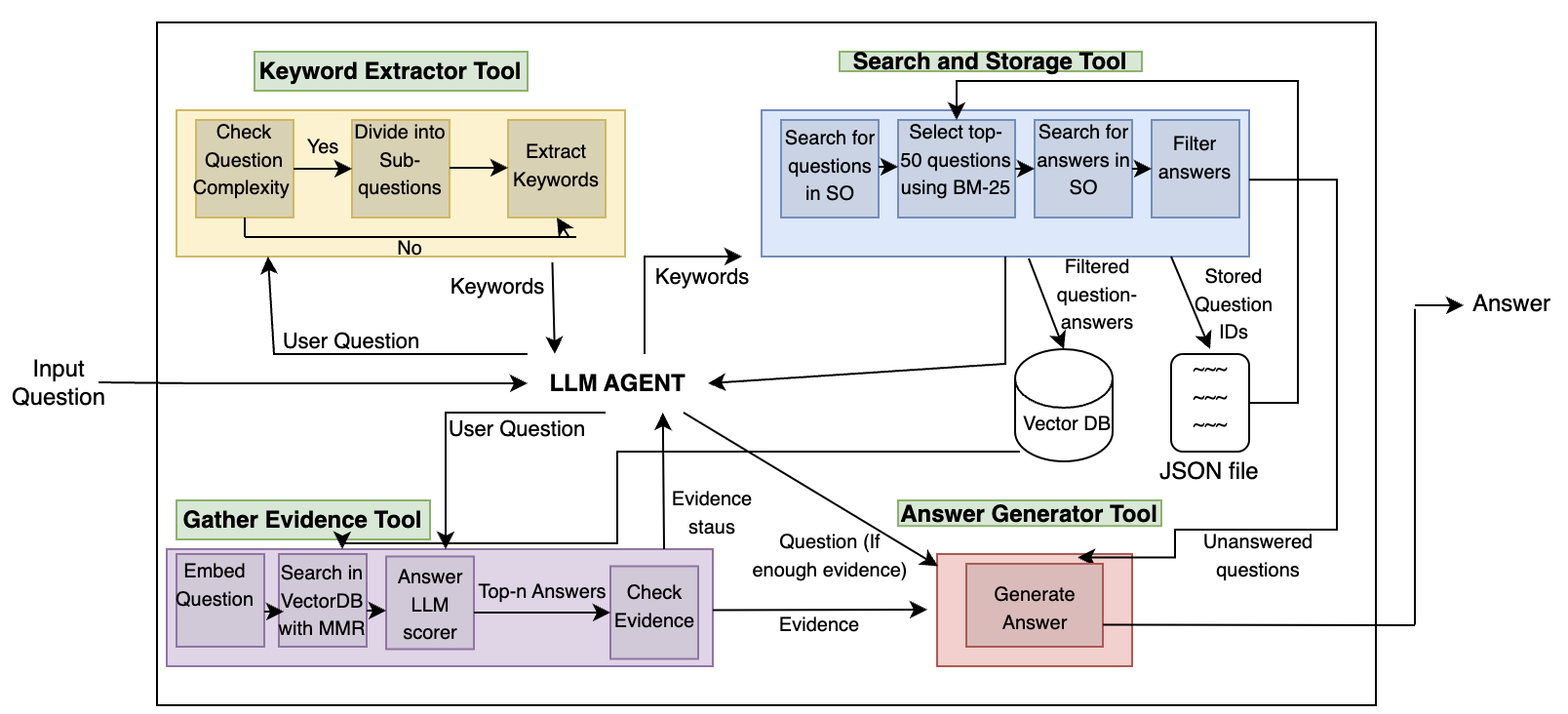
Developers spend much time finding information that is relevant to their questions. Stack Overflow has been the leading resource, and with the advent of Large Language Models (LLMs), generative models such as ChatGPT are used frequently. However, there is a catch in using each one separately. Searching for answers is time-consuming and tedious, as shown by the many tools developed by researchers to address this issue. On the other, using LLMs is not reliable, as they might produce irrelevant or unreliable answers (i.e., hallucination). In this work, we present StackRAG, a retrieval-augmented Multiagent generation tool based on LLMs that combines the two worlds: aggregating the knowledge from SO to enhance the reliability of the generated answers. Initial evaluations show that the generated answers are correct, accurate, relevant, and useful.
Read more6/21/2024