Rank Reduction Autoencoders -- Enhancing interpolation on nonlinear manifolds

0
➖
Sign in to get full access
Overview
- Classical autoencoders (AEs) have limitations in many practical situations
- When the latent space is reduced, feature extraction becomes possible, but overfitting can lead to "holes" in the interpolation capabilities
- Increasing the latent dimension can improve approximation, but may not lead to dimensionality reduction, making feature extraction problematic
- The proposed Rank Reduction Autoencoder (RRAE) addresses these issues by having an enlarged latent space with a small number of dominant singular values (low-rank)
Plain English Explanation
Autoencoders are a type of machine learning model that can be used for various tasks, such as data compression and feature extraction. However, classical autoencoders have some limitations. When the latent space (the "hidden" representation of the data) is reduced, it becomes easier to extract meaningful features from the data. But this can also lead to a problem called "overfitting," where the model becomes too specialized and has trouble interpolating (or connecting) between different data points.
On the other hand, increasing the size of the latent space can help the model make more accurate predictions, but it may not actually reduce the dimensionality of the data, which is important for feature extraction. This makes it harder to use the autoencoder for interpolation tasks.
The researchers in this paper introduce a new type of autoencoder called the Rank Reduction Autoencoder (RRAE). The RRAE has a larger latent space, but it's designed to have a small number of "dominant" features (or singular values). This allows the RRAE to make accurate predictions while still enabling effective feature extraction, similar to how lightweight variational autoencoders can maintain performance with fewer parameters. The researchers present two different ways to achieve this goal, both of which aim to build a reduced basis that accurately represents the latent space.
Technical Explanation
The researchers propose the Rank Reduction Autoencoder (RRAE), an autoencoder with an enlarged latent space that is constrained to have a small pre-specified number of dominant singular values (i.e., low-rank). This allows the RRAE to make accurate predictions while still enabling effective feature extraction, addressing the limitations of classical autoencoders.
The researchers present two formulations to achieve this goal:
-
Truncated SVD in the latent space: The first formulation consists of a truncated Singular Value Decomposition (SVD) in the latent space, which builds a reduced basis that accurately represents the latent space.
-
Penalty term in the loss function: The second formulation adds a penalty term to the loss function, which encourages the latent space to have a small number of dominant singular values.
The researchers evaluate the efficiency of their RRAE formulations by using them for interpolation tasks and comparing the results to other autoencoders, both on synthetic data and the MNIST dataset.
Critical Analysis
The researchers acknowledge that while the RRAE addresses some of the limitations of classical autoencoders, there are still areas for further research. For example, the paper does not explore the impact of the choice of the target rank or the effect of the penalty term on the latent space representation.
Additionally, the researchers only evaluate the RRAE on relatively simple datasets (synthetic data and MNIST). It would be valuable to see how the RRAE performs on more complex, real-world datasets, where the benefits of its low-rank latent space and feature extraction capabilities may be more pronounced.
Furthermore, the researchers do not provide a detailed analysis of the computational complexity and training time of the RRAE compared to other autoencoder variants. This information would be helpful for researchers and practitioners when deciding which model to use for their specific dimensionality reduction needs.
Overall, the RRAE is a promising approach to address the limitations of classical autoencoders, but further research and evaluation on more diverse datasets would be valuable to fully understand its strengths and weaknesses.
Conclusion
The Rank Reduction Autoencoder (RRAE) introduced in this paper is a novel approach to improving the efficiency of classical autoencoders. By maintaining an enlarged latent space with a small number of dominant singular values, the RRAE can make accurate predictions while still enabling effective feature extraction, addressing the limitations of traditional autoencoders.
The researchers present two formulations to achieve this goal, both of which show promising results on synthetic data and the MNIST dataset. While the paper highlights the potential of the RRAE, further research is needed to fully understand its performance on more complex, real-world datasets and its computational efficiency compared to other autoencoder variants.
Overall, the RRAE is a valuable contribution to the field of machine learning, offering a new way to balance the trade-off between latent space dimensionality, prediction accuracy, and feature extraction in autoencoder models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
Rank Reduction Autoencoders -- Enhancing interpolation on nonlinear manifolds
Jad Mounayer, Sebastian Rodriguez, Chady Ghnatios, Charbel Farhat, Francisco Chinesta
The efficiency of classical Autoencoders (AEs) is limited in many practical situations. When the latent space is reduced through autoencoders, feature extraction becomes possible. However, overfitting is a common issue, leading to ``holes'' in AEs' interpolation capabilities. On the other hand, increasing the latent dimension results in a better approximation with fewer non-linearly coupled features (e.g., Koopman theory or kPCA), but it doesn't necessarily lead to dimensionality reduction, which makes feature extraction problematic. As a result, interpolating using Autoencoders gets harder. In this work, we introduce the Rank Reduction Autoencoder (RRAE), an autoencoder with an enlarged latent space, which is constrained to have a small pre-specified number of dominant singular values (i.e., low-rank). The latent space of RRAEs is large enough to enable accurate predictions while enabling feature extraction. As a result, the proposed autoencoder features a minimal rank linear latent space. To achieve what's proposed, two formulations are presented, a strong and a weak one, that build a reduced basis accurately representing the latent space. The first formulation consists of a truncated SVD in the latent space, while the second one adds a penalty term to the loss function. We show the efficiency of our formulations by using them for interpolation tasks and comparing the results to other autoencoders on both synthetic data and MNIST.
Read more5/24/2024
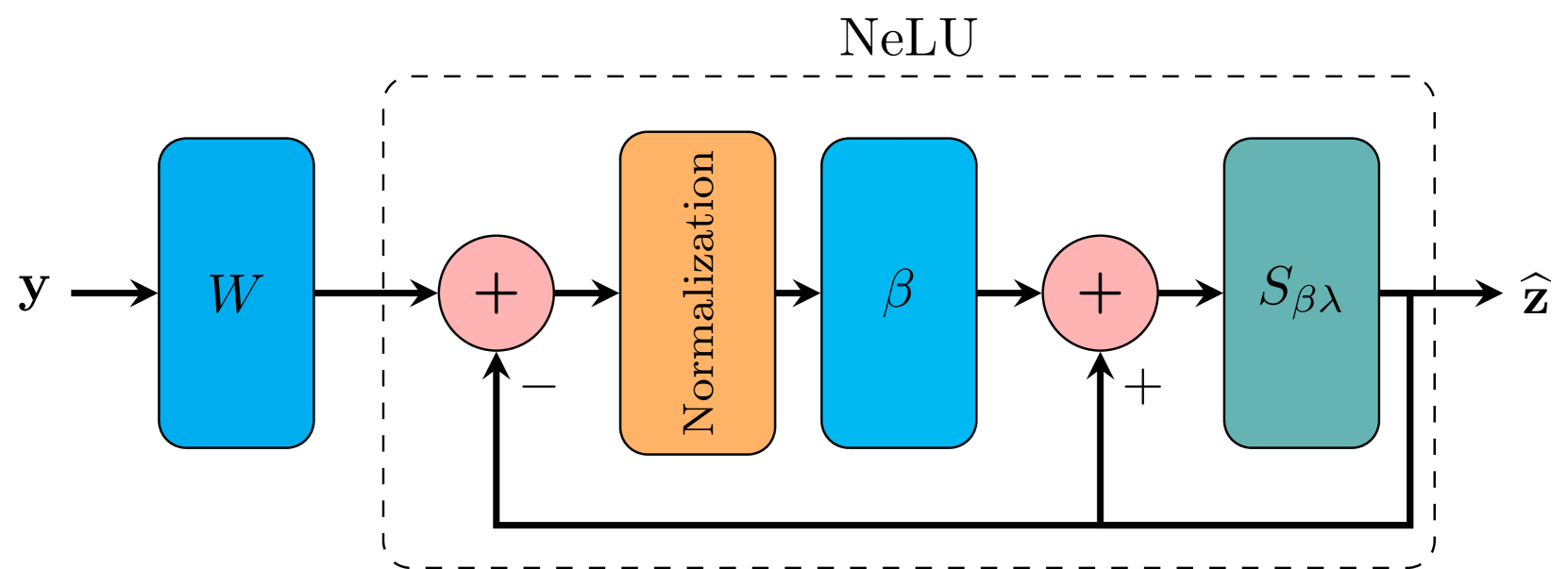
0
Pivotal Auto-Encoder via Self-Normalizing ReLU
Nelson Goldenstein, Jeremias Sulam, Yaniv Romano
Sparse auto-encoders are useful for extracting low-dimensional representations from high-dimensional data. However, their performance degrades sharply when the input noise at test time differs from the noise employed during training. This limitation hinders the applicability of auto-encoders in real-world scenarios where the level of noise in the input is unpredictable. In this paper, we formalize single hidden layer sparse auto-encoders as a transform learning problem. Leveraging the transform modeling interpretation, we propose an optimization problem that leads to a predictive model invariant to the noise level at test time. In other words, the same pre-trained model is able to generalize to different noise levels. The proposed optimization algorithm, derived from the square root lasso, is translated into a new, computationally efficient auto-encoding architecture. After proving that our new method is invariant to the noise level, we evaluate our approach by training networks using the proposed architecture for denoising tasks. Our experimental results demonstrate that the trained models yield a significant improvement in stability against varying types of noise compared to commonly used architectures.
Read more6/26/2024
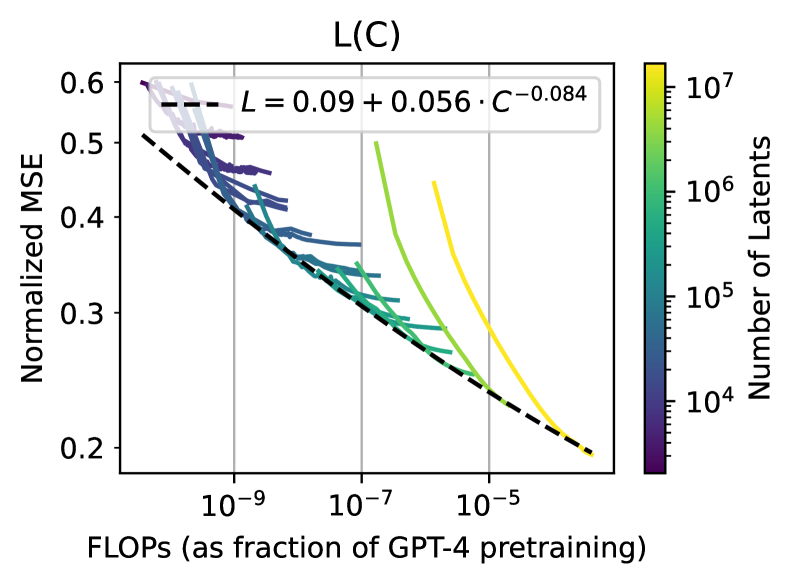
0
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupr'e la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, Jeffrey Wu
Sparse autoencoders provide a promising unsupervised approach for extracting interpretable features from a language model by reconstructing activations from a sparse bottleneck layer. Since language models learn many concepts, autoencoders need to be very large to recover all relevant features. However, studying the properties of autoencoder scaling is difficult due to the need to balance reconstruction and sparsity objectives and the presence of dead latents. We propose using k-sparse autoencoders [Makhzani and Frey, 2013] to directly control sparsity, simplifying tuning and improving the reconstruction-sparsity frontier. Additionally, we find modifications that result in few dead latents, even at the largest scales we tried. Using these techniques, we find clean scaling laws with respect to autoencoder size and sparsity. We also introduce several new metrics for evaluating feature quality based on the recovery of hypothesized features, the explainability of activation patterns, and the sparsity of downstream effects. These metrics all generally improve with autoencoder size. To demonstrate the scalability of our approach, we train a 16 million latent autoencoder on GPT-4 activations for 40 billion tokens. We release training code and autoencoders for open-source models, as well as a visualizer.
Read more6/7/2024
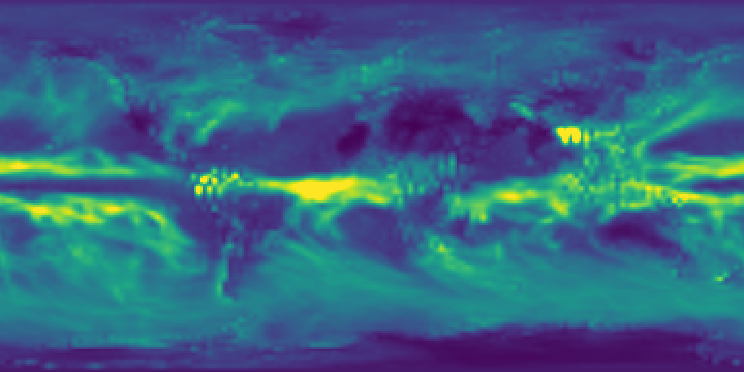
0
Distributional Principal Autoencoders
Xinwei Shen, Nicolai Meinshausen
Dimension reduction techniques usually lose information in the sense that reconstructed data are not identical to the original data. However, we argue that it is possible to have reconstructed data identically distributed as the original data, irrespective of the retained dimension or the specific mapping. This can be achieved by learning a distributional model that matches the conditional distribution of data given its low-dimensional latent variables. Motivated by this, we propose Distributional Principal Autoencoder (DPA) that consists of an encoder that maps high-dimensional data to low-dimensional latent variables and a decoder that maps the latent variables back to the data space. For reducing the dimension, the DPA encoder aims to minimise the unexplained variability of the data with an adaptive choice of the latent dimension. For reconstructing data, the DPA decoder aims to match the conditional distribution of all data that are mapped to a certain latent value, thus ensuring that the reconstructed data retains the original data distribution. Our numerical results on climate data, single-cell data, and image benchmarks demonstrate the practical feasibility and success of the approach in reconstructing the original distribution of the data. DPA embeddings are shown to preserve meaningful structures of data such as the seasonal cycle for precipitations and cell types for gene expression.
Read more4/23/2024