Reflection-Reinforced Self-Training for Language Agents

0

Sign in to get full access
Overview
- This paper introduces a novel approach called Reflection-Reinforced Self-Training (Re-ReST) for training language agents.
- Re-ReST aims to improve the performance and robustness of language agents by incorporating a reflection mechanism that allows the agent to assess its own capabilities and biases.
- The key idea is to have the agent engage in self-reflection and use that reflection to guide its own learning and decision-making processes, leading to more reliable and trustworthy language models.
Plain English Explanation
The paper presents a new way to train language models, called Reflection-Reinforced Self-Training (Re-ReST). The main idea is to have the language model constantly evaluate its own performance and decision-making, and use that self-reflection to improve itself over time.
Imagine you're trying to learn a new language. A traditional approach would be to just study vocabulary and grammar rules. But with Re-ReST, the language model would also think about how well it's understanding the language, what it's still struggling with, and what strategies it could use to get better. This self-awareness and self-improvement process is what makes Re-ReST unique.
By incorporating this reflection mechanism, the language model can become more reliable and less prone to making mistakes or exhibiting biases. It can identify its own weaknesses and work to address them, leading to better overall performance.
This is an important development, as language models are increasingly being used for high-stakes applications like customer service, medical diagnosis, and financial advising. Having models that can critically evaluate themselves and learn from their mistakes is key to ensuring they are safe and trustworthy.
Technical Explanation
The core of the Re-ReST approach is a reflection module that sits alongside the main language model. This reflection module continuously monitors the model's outputs, compares them to its own internal understanding of the task, and provides feedback to the model on how it can improve.
This feedback is then used to guide the model's self-training process. Rather than just passively absorbing more data, the model actively reflects on its own performance and uses that self-reflection to identify areas for improvement. It can then focus its learning on those weaker areas, leading to more balanced and robust capabilities.
The paper evaluates Re-ReST on a range of language understanding and generation tasks, and finds that it consistently outperforms standard self-training approaches. The reflected-upon models demonstrate better calibration, less biased outputs, and improved overall performance.
Importantly, the authors also show that Re-ReST can help language models learn appropriate self-restraint, allowing them to better identify when they lack the necessary knowledge or capabilities to provide a reliable response. This self-awareness is a critical component of making language models more trustworthy and aligned with human values.
Critical Analysis
The Re-ReST approach represents an important step forward in making language models more reflective and self-aware. By giving the models the ability to critically evaluate their own outputs and decision-making processes, the authors have developed a mechanism to improve model robustness and reliability.
That said, the paper does not address some key limitations of this approach. For example, the reflection module itself could potentially exhibit biases or blind spots, which could then be propagated back into the main model. Additionally, the computational overhead of the reflection process may limit the scalability of Re-ReST to larger, more complex language models.
Further research is also needed to fully understand the long-term effects of this self-reflection process. While the authors demonstrate immediate benefits, it's unclear how the models' self-awareness and self-improvement capabilities may evolve over extended training or deployment.
Overall, the Re-ReST approach is a promising direction for making language models more reliable and trustworthy. However, continued work is needed to address its potential limitations and ensure that the reflection process itself is well-calibrated and free of unintended consequences.
Conclusion
The Reflection-Reinforced Self-Training (Re-ReST) approach introduced in this paper represents an important advancement in the field of language model development. By giving language models the ability to critically reflect on their own outputs and decision-making, the authors have created a mechanism to improve model robustness, reliability, and self-awareness.
This is a crucial step forward, as language models are increasingly being deployed in high-stakes applications where their trustworthiness and alignment with human values is paramount. The self-reflection and self-improvement capabilities of Re-ReST hold the potential to make these models more reliable, less biased, and better able to identify the limits of their own knowledge and capabilities.
While the paper highlights the immediate benefits of this approach, further research is needed to fully explore its long-term implications and address potential limitations. Nonetheless, the Re-ReST framework represents an important milestone in the ongoing effort to develop AI systems that are not only capable, but also transparent, accountable, and aligned with human interests.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reflection-Reinforced Self-Training for Language Agents
Zi-Yi Dou, Cheng-Fu Yang, Xueqing Wu, Kai-Wei Chang, Nanyun Peng
Finetuning language agents with reasoning-action trajectories is effective, but obtaining these trajectories from human annotations or stronger models is costly and sometimes impractical. In this paper, we investigate the use of self-training in language agents, which can generate supervision from the agent itself, offering a promising alternative without relying on human or stronger model demonstrations. Self-training, however, requires high-quality model-generated samples, which are hard to obtain for challenging language agent tasks. To address this, we present Reflection-Reinforced Self-Training (Re-ReST), which uses a textit{reflector} to refine low-quality generated samples during self-training. The reflector takes the agent's output and feedback from an external environment (e.g., unit test results in code generation) to produce improved samples. This technique enhances the quality of inferior samples and efficiently enriches the self-training dataset with higher-quality samples. We conduct extensive experiments on open-source language agents across tasks, including multi-hop question answering, sequential decision-making, code generation, visual question answering, and text-to-image generation. The results demonstrate the effectiveness of self-training and Re-ReST in language agent tasks, with self-training improving baselines by 7.6% on HotpotQA and 28.4% on AlfWorld, and Re-ReST further boosting performance by 2.0% and 14.1%, respectively. Our studies also confirm the efficiency of using a reflector to generate high-quality samples for self-training. Moreover, we demonstrate a method to employ reflection during inference without ground-truth feedback, addressing the limitation of previous reflection work. Our code is released at https://github.com/PlusLabNLP/Re-ReST.
Read more7/9/2024
💬
0
METAREFLECTION: Learning Instructions for Language Agents using Past Reflections
Priyanshu Gupta, Shashank Kirtania, Ananya Singha, Sumit Gulwani, Arjun Radhakrishna, Sherry Shi, Gustavo Soares
Despite the popularity of Large Language Models (LLMs), crafting specific prompts for LLMs to perform particular tasks remains challenging. Users often engage in multiple conversational turns with an LLM-based agent to accomplish their intended task. Recent studies have demonstrated that linguistic feedback, in the form of self-reflections generated by the model, can work as reinforcement during these conversations, thus enabling quicker convergence to the desired outcome. Motivated by these findings, we introduce METAREFLECTION, a novel technique that learns general prompt instructions for a specific domain from individual self-reflections gathered during a training phase. We evaluate our technique in two domains: Infrastructure as Code (IAC) vulnerability detection and question-answering (QA) using REACT and COT. Our results demonstrate a notable improvement, with METARELECTION outperforming GPT-4 by 16.82% (IAC), 31.33% (COT), and 15.42% (REACT), underscoring the potential of METAREFLECTION as a viable method for enhancing the efficiency of LLMs.
Read more5/24/2024

0
Learn Beyond The Answer: Training Language Models with Reflection for Mathematical Reasoning
Zhihan Zhang, Zhenwen Liang, Wenhao Yu, Dian Yu, Mengzhao Jia, Dong Yu, Meng Jiang
Supervised fine-tuning enhances the problem-solving abilities of language models across various mathematical reasoning tasks. To maximize such benefits, existing research focuses on broadening the training set with various data augmentation techniques, which is effective for standard single-round question-answering settings. Our work introduces a novel technique aimed at cultivating a deeper understanding of the training problems at hand, enhancing performance not only in standard settings but also in more complex scenarios that require reflective thinking. Specifically, we propose reflective augmentation, a method that embeds problem reflection into each training instance. It trains the model to consider alternative perspectives and engage with abstractions and analogies, thereby fostering a thorough comprehension through reflective reasoning. Extensive experiments validate the achievement of our aim, underscoring the unique advantages of our method and its complementary nature relative to existing augmentation techniques.
Read more6/19/2024
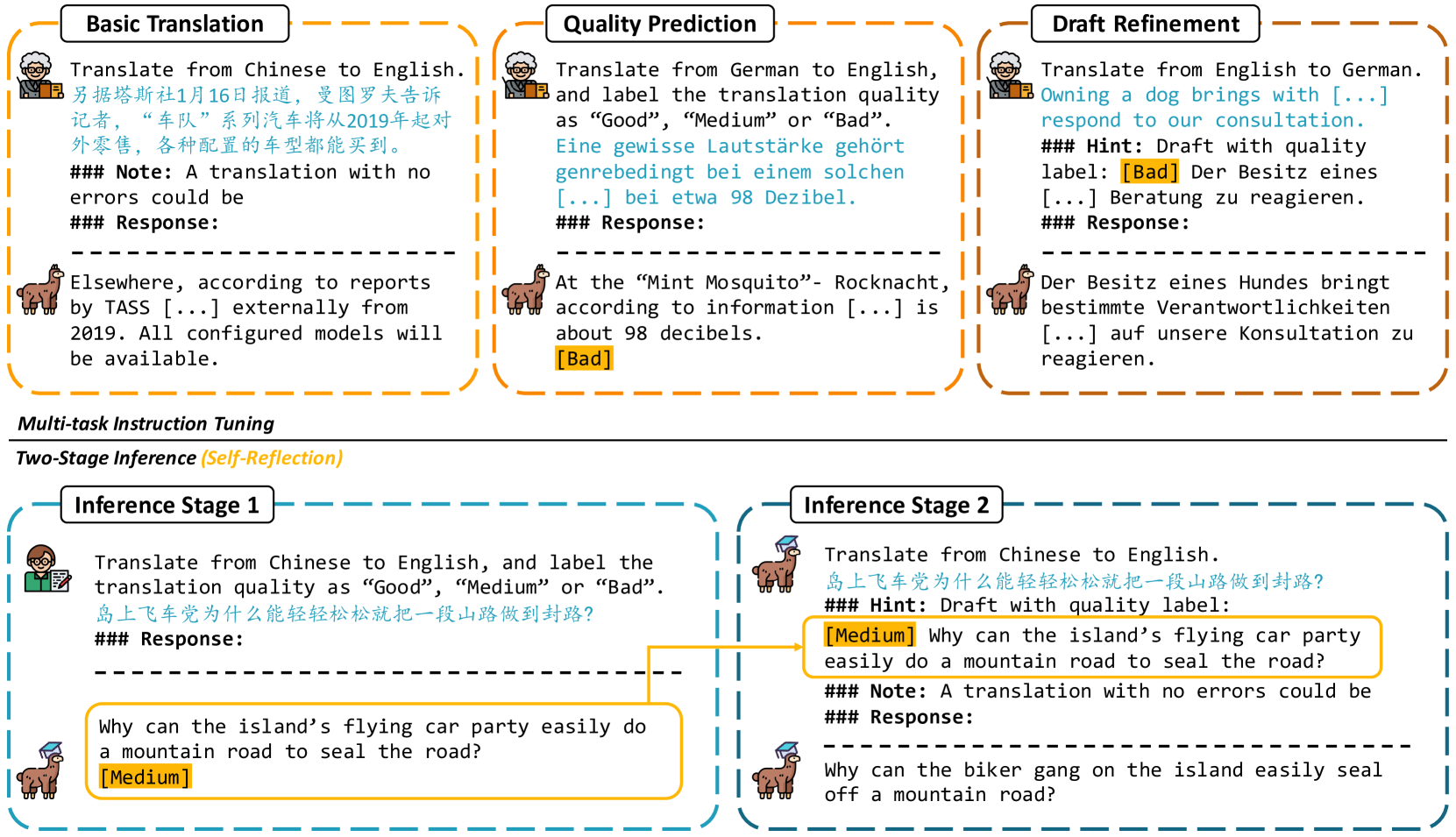
0
TasTe: Teaching Large Language Models to Translate through Self-Reflection
Yutong Wang, Jiali Zeng, Xuebo Liu, Fandong Meng, Jie Zhou, Min Zhang
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
Read more6/13/2024