Reactzyme: A Benchmark for Enzyme-Reaction Prediction

0
Sign in to get full access
Overview
- The paper introduces Reactzyme, a new benchmark dataset for enzyme-reaction prediction tasks.
- Reactzyme contains information about enzymes, their catalyzed reactions, and associated metadata.
- The dataset aims to enable the development of machine learning models that can predict enzyme-reaction relationships.
Plain English Explanation
The paper discusses a new dataset called Reactzyme that is designed to help researchers develop machine learning models for predicting the relationships between enzymes and the chemical reactions they catalyze. Enzymes are proteins that speed up chemical reactions in living organisms. Being able to accurately predict which enzymes can catalyze which reactions is valuable for applications like enzyme design and reaction prediction.
The Reactzyme dataset contains information about enzymes, the reactions they catalyze, and other related data. By providing a common benchmark dataset, the researchers hope to enable the development of more advanced machine learning models that can accurately predict enzyme-reaction relationships. This could lead to breakthroughs in fields like biochemistry and biotechnology.
Technical Explanation
The paper introduces the Reactzyme dataset, which is designed to serve as a benchmark for developing machine learning models that can predict enzyme-reaction relationships. The dataset contains information about enzymes, including their sequences, structures, and catalytic functions, as well as the chemical reactions they catalyze. Reactzyme was constructed by integrating data from multiple existing databases, such as the Enzyme Commission (EC) classification system and the Kyoto Encyclopedia of Genes and Genomes (KEGG).
The dataset is divided into training, validation, and test sets, and the paper provides baseline results using several machine learning models, including graph neural networks and transformer-based architectures. The authors demonstrate that these models can achieve reasonable performance on the Reactzyme dataset, but there is still significant room for improvement, indicating the challenges of accurately predicting enzyme-reaction relationships.
Critical Analysis
The Reactzyme dataset represents an important step forward in the development of machine learning models for enzyme-reaction prediction. By providing a standardized benchmark, the dataset can help drive progress in this field and enable more meaningful comparisons between different approaches.
However, the paper does acknowledge some limitations of the dataset, such as the potential for biases in the underlying data sources and the relatively small size of the dataset compared to the complexity of the problem. Additionally, the baseline models presented in the paper, while informative, may not fully capture the nuances of enzyme-reaction relationships, and more advanced architectures or techniques may be required to achieve higher performance.
The paper also does not delve deeply into the potential real-world applications and implications of accurate enzyme-reaction prediction, which could be an area for further exploration and discussion.
Conclusion
The Reactzyme dataset introduced in this paper represents a significant contribution to the field of enzyme-reaction prediction. By providing a standardized benchmark, the dataset can enable the development of more advanced machine learning models that can accurately predict the relationships between enzymes and the chemical reactions they catalyze. This could have important implications for fields like biochemistry, biotechnology, and drug discovery, where the ability to understand and manipulate enzymatic processes is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reactzyme: A Benchmark for Enzyme-Reaction Prediction
Chenqing Hua, Bozitao Zhong, Sitao Luan, Liang Hong, Guy Wolf, Doina Precup, Shuangjia Zheng
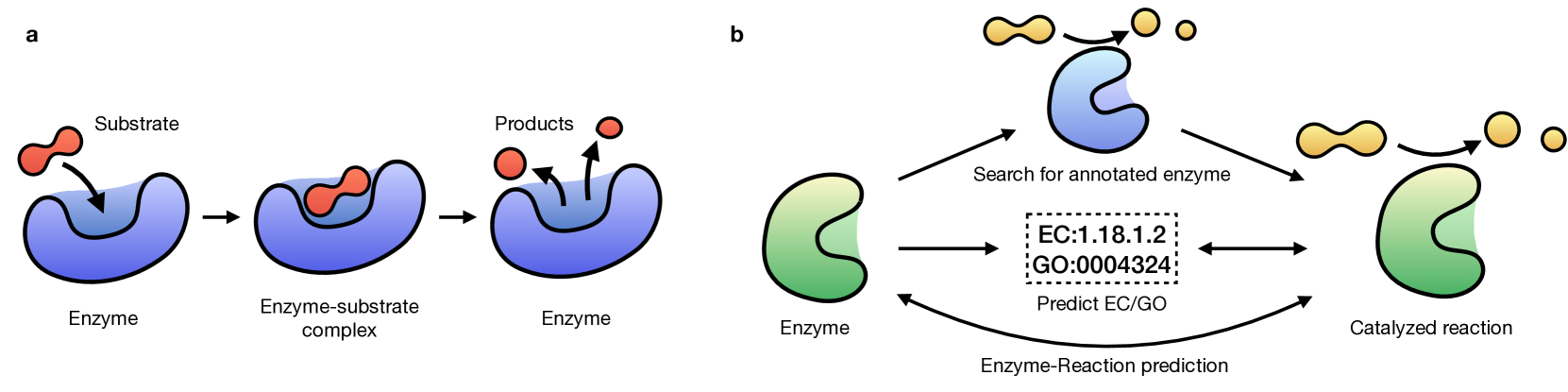
Enzymes, with their specific catalyzed reactions, are necessary for all aspects of life, enabling diverse biological processes and adaptations. Predicting enzyme functions is essential for understanding biological pathways, guiding drug development, enhancing bioproduct yields, and facilitating evolutionary studies. Addressing the inherent complexities, we introduce a new approach to annotating enzymes based on their catalyzed reactions. This method provides detailed insights into specific reactions and is adaptable to newly discovered reactions, diverging from traditional classifications by protein family or expert-derived reaction classes. We employ machine learning algorithms to analyze enzyme reaction datasets, delivering a much more refined view on the functionality of enzymes. Our evaluation leverages the largest enzyme-reaction dataset to date, derived from the SwissProt and Rhea databases with entries up to January 8, 2024. We frame the enzyme-reaction prediction as a retrieval problem, aiming to rank enzymes by their catalytic ability for specific reactions. With our model, we can recruit proteins for novel reactions and predict reactions in novel proteins, facilitating enzyme discovery and function annotation.
Read more8/27/2024

0
Generative Enzyme Design Guided by Functionally Important Sites and Small-Molecule Substrates
Zhenqiao Song, Yunlong Zhao, Wenxian Shi, Wengong Jin, Yang Yang, Lei Li
Enzymes are genetically encoded biocatalysts capable of accelerating chemical reactions. How can we automatically design functional enzymes? In this paper, we propose EnzyGen, an approach to learn a unified model to design enzymes across all functional families. Our key idea is to generate an enzyme's amino acid sequence and their three-dimensional (3D) coordinates based on functionally important sites and substrates corresponding to a desired catalytic function. These sites are automatically mined from enzyme databases. EnzyGen consists of a novel interleaving network of attention and neighborhood equivariant layers, which captures both long-range correlation in an entire protein sequence and local influence from nearest amino acids in 3D space. To learn the generative model, we devise a joint training objective, including a sequence generation loss, a position prediction loss and an enzyme-substrate interaction loss. We further construct EnzyBench, a dataset with 3157 enzyme families, covering all available enzymes within the protein data bank (PDB). Experimental results show that our EnzyGen consistently achieves the best performance across all 323 testing families, surpassing the best baseline by 10.79% in terms of substrate binding affinity. These findings demonstrate EnzyGen's superior capability in designing well-folded and effective enzymes binding to specific substrates with high affinities.
Read more7/18/2024

0
ReactAIvate: A Deep Learning Approach to Predicting Reaction Mechanisms and Unmasking Reactivity Hotspots
Ajnabiul Hoque, Manajit Das, Mayank Baranwal, Raghavan B. Sunoj
A chemical reaction mechanism (CRM) is a sequence of molecular-level events involving bond-breaking/forming processes, generating transient intermediates along the reaction pathway as reactants transform into products. Understanding such mechanisms is crucial for designing and discovering new reactions. One of the currently available methods to probe CRMs is quantum mechanical (QM) computations. The resource-intensive nature of QM methods and the scarcity of mechanism-based datasets motivated us to develop reliable ML models for predicting mechanisms. In this study, we created a comprehensive dataset with seven distinct classes, each representing uniquely characterized elementary steps. Subsequently, we developed an interpretable attention-based GNN that achieved near-unity and 96% accuracy, respectively for reaction step classification and the prediction of reactive atoms in each such step, capturing interactions between the broader reaction context and local active regions. The near-perfect classification enables accurate prediction of both individual events and the entire CRM, mitigating potential drawbacks of Seq2Seq approaches, where a wrongly predicted character leads to incoherent CRM identification. In addition to interpretability, our model adeptly identifies key atom(s) even from out-of-distribution classes. This generalizabilty allows for the inclusion of new reaction types in a modular fashion, thus will be of value to experts for understanding the reactivity of new molecules.
Read more7/16/2024
0
A Self-feedback Knowledge Elicitation Approach for Chemical Reaction Predictions
Pengfei Liu, Jun Tao, Zhixiang Ren
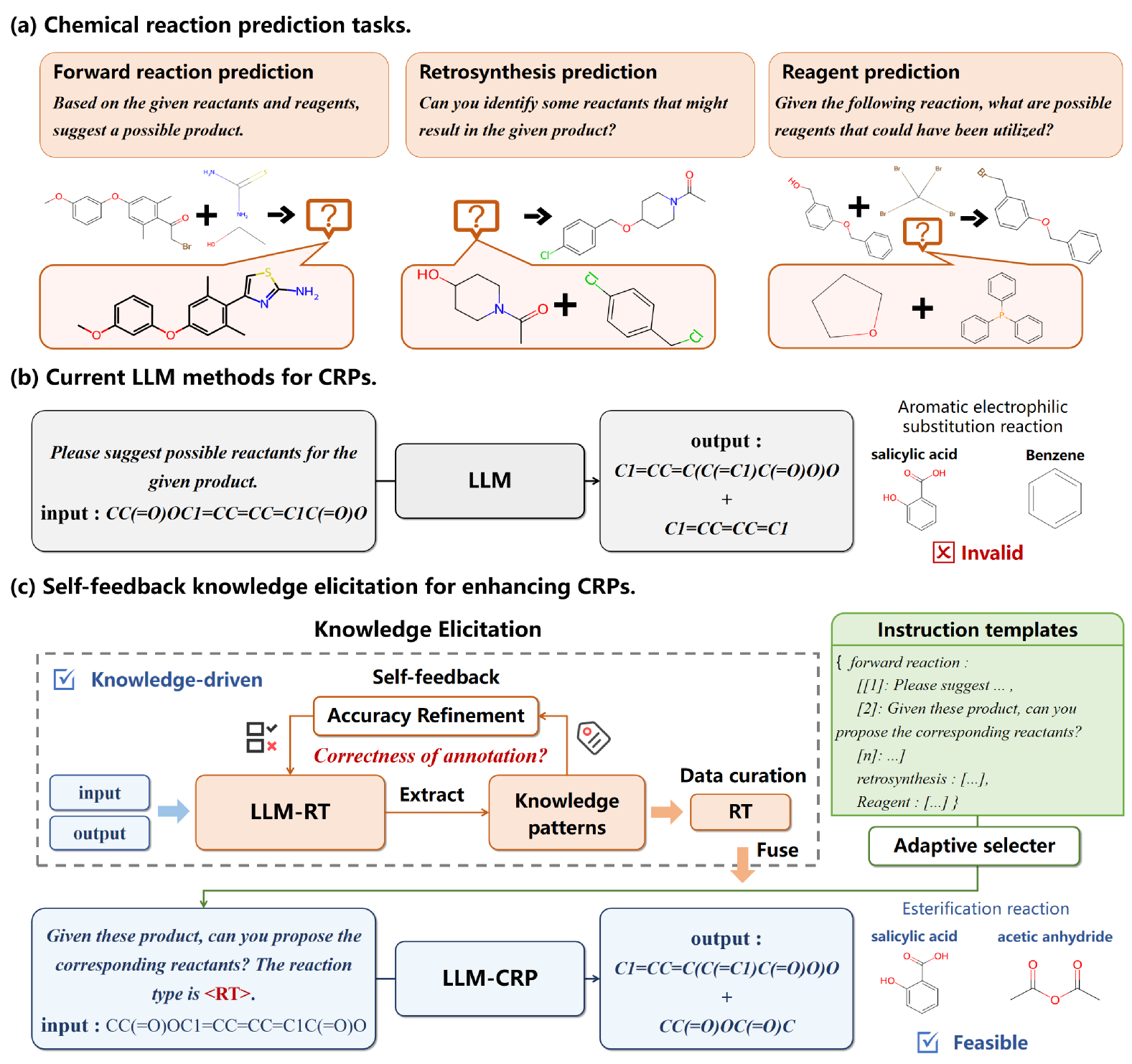
The task of chemical reaction predictions (CRPs) plays a pivotal role in advancing drug discovery and material science. However, its effectiveness is constrained by the vast and uncertain chemical reaction space and challenges in capturing reaction selectivity, particularly due to existing methods' limitations in exploiting the data's inherent knowledge. To address these challenges, we introduce a data-curated self-feedback knowledge elicitation approach. This method starts from iterative optimization of molecular representations and facilitates the extraction of knowledge on chemical reaction types (RTs). Then, we employ adaptive prompt learning to infuse the prior knowledge into the large language model (LLM). As a result, we achieve significant enhancements: a 14.2% increase in retrosynthesis prediction accuracy, a 74.2% rise in reagent prediction accuracy, and an expansion in the model's capability for handling multi-task chemical reactions. This research offers a novel paradigm for knowledge elicitation in scientific research and showcases the untapped potential of LLMs in CRPs.
Read more4/16/2024