Read Between the Layers: Leveraging Intra-Layer Representations for Rehearsal-Free Continual Learning with Pre-Trained Models

0

Sign in to get full access
Overview
• The paper explores a novel approach called "Read Between the Layers" (RBL) for continual learning with pre-trained models. • Continual learning is the ability of an AI system to learn new tasks sequentially without forgetting previous knowledge. • RBL leverages representations from intermediate layers of pre-trained models to enable rehearsal-free continual learning. • This means the model can learn new tasks without the need to store or replay old data, making it more practical for real-world applications.
Plain English Explanation
Continual learning is an important capability for AI systems, allowing them to acquire new knowledge and skills over time without forgetting what they've learned before. This paper presents a new technique called "Read Between the Layers" (RBL) that can enable this type of continual learning using pre-trained models.
Pre-trained models are AI systems that have been trained on large datasets to develop general knowledge and capabilities. RBL taps into the internal representations within these pre-trained models to allow the system to learn new tasks without having to explicitly store or replay old data. This "rehearsal-free" approach makes continual learning more practical for real-world applications, where storing and replaying large datasets may not be feasible.
The key insight behind RBL is that the intermediate layers of pre-trained models encode rich representations that can be leveraged to learn new skills. By carefully selecting and adapting these intra-layer representations, the model can acquire new knowledge while preserving what it has learned before. This contrasts with other continual learning methods that often require storing or replaying old data, which can be memory-intensive and computationally expensive.
Technical Explanation
The paper proposes a novel continual learning method called "Read Between the Layers" (RBL) that leverages the intra-layer representations of pre-trained models to enable rehearsal-free learning of new tasks. Unlike traditional continual learning approaches that often require storing or replaying old data, RBL can adapt the pre-trained model's internal representations to acquire new skills without forgetting previous knowledge.
The key idea behind RBL is to selectively extract and modify the representations from intermediate layers of the pre-trained model, rather than updating the entire model or only the final layer. By carefully selecting and adapting these intra-layer representations, RBL can learn new tasks while preserving the model's general knowledge and capabilities.
The paper evaluates RBL on a range of continual learning benchmarks, including image classification and language modeling tasks. The results demonstrate that RBL outperforms other rehearsal-free continual learning methods in terms of performance and efficiency, while also exhibiting strong transfer learning capabilities. RBL is shown to be scalable and applicable to large language models as well.
Critical Analysis
The paper presents a promising approach for continual learning with pre-trained models, but there are a few potential limitations and areas for further exploration:
-
The paper focuses on specific types of tasks, such as image classification and language modeling. It would be valuable to see how RBL performs on a broader range of tasks and domains to assess its generalizability.
-
The paper does not provide a deep analysis of the intra-layer representations that RBL leverages. A more comprehensive understanding of the underlying mechanisms and the key factors that contribute to RBL's effectiveness could lead to further improvements.
-
While RBL is designed to be rehearsal-free, the paper does not explore the potential trade-offs between performance and memory usage. It would be interesting to investigate how RBL scales in terms of computational and memory requirements as the number of tasks increases.
-
The paper could benefit from a more detailed comparison with other continual learning approaches to better contextualize the contributions and limitations of RBL.
Overall, the "Read Between the Layers" approach represents an important step forward in enabling practical continual learning with pre-trained models. Further research to address the identified limitations and explore its broader applicability could lead to significant advancements in the field of continual learning.
Conclusion
The paper introduces a novel continual learning method called "Read Between the Layers" (RBL) that leverages the intra-layer representations of pre-trained models to enable rehearsal-free learning of new tasks. By selectively adapting the intermediate-level representations, RBL can acquire new skills without forgetting previous knowledge, making it a promising approach for practical continual learning applications.
The key innovation of RBL is its ability to effectively leverage the rich representations within pre-trained models, without the need for storing or replaying old data. This rehearsal-free capability is a significant advantage over traditional continual learning methods that often require extensive resource management and data storage.
The results presented in the paper demonstrate the strong performance and efficiency of RBL on a range of continual learning benchmarks, highlighting its potential for scalability and applicability to large language models. Further research to address the identified limitations and explore RBL's broader implications could lead to important advancements in the field of continual learning, with significant implications for the development of more adaptable and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Read Between the Layers: Leveraging Intra-Layer Representations for Rehearsal-Free Continual Learning with Pre-Trained Models
Kyra Ahrens, Hans Hergen Lehmann, Jae Hee Lee, Stefan Wermter
We address the Continual Learning (CL) problem, wherein a model must learn a sequence of tasks from non-stationary distributions while preserving prior knowledge upon encountering new experiences. With the advancement of foundation models, CL research has pivoted from the initial learning-from-scratch paradigm towards utilizing generic features from large-scale pre-training. However, existing approaches to CL with pre-trained models primarily focus on separating class-specific features from the final representation layer and neglect the potential of intermediate representations to capture low- and mid-level features, which are more invariant to domain shifts. In this work, we propose LayUP, a new prototype-based approach to CL that leverages second-order feature statistics from multiple intermediate layers of a pre-trained network. Our method is conceptually simple, does not require access to prior data, and works out of the box with any foundation model. LayUP surpasses the state of the art in four of the seven class-incremental learning benchmarks, all three domain-incremental learning benchmarks and in six of the seven online continual learning benchmarks, while significantly reducing memory and computational requirements compared to existing baselines. Our results demonstrate that fully exhausting the representational capacities of pre-trained models in CL goes well beyond their final embeddings.
Read more7/8/2024
✅
0
Do Pre-trained Models Benefit Equally in Continual Learning?
Kuan-Ying Lee, Yuanyi Zhong, Yu-Xiong Wang
Existing work on continual learning (CL) is primarily devoted to developing algorithms for models trained from scratch. Despite their encouraging performance on contrived benchmarks, these algorithms show dramatic performance drops in real-world scenarios. Therefore, this paper advocates the systematic introduction of pre-training to CL, which is a general recipe for transferring knowledge to downstream tasks but is substantially missing in the CL community. Our investigation reveals the multifaceted complexity of exploiting pre-trained models for CL, along three different axes, pre-trained models, CL algorithms, and CL scenarios. Perhaps most intriguingly, improvements in CL algorithms from pre-training are very inconsistent an underperforming algorithm could become competitive and even state-of-the-art when all algorithms start from a pre-trained model. This indicates that the current paradigm, where all CL methods are compared in from-scratch training, is not well reflective of the true CL objective and desired progress. In addition, we make several other important observations, including that CL algorithms that exert less regularization benefit more from a pre-trained model; and that a stronger pre-trained model such as CLIP does not guarantee a better improvement. Based on these findings, we introduce a simple yet effective baseline that employs minimum regularization and leverages the more beneficial pre-trained model, coupled with a two-stage training pipeline. We recommend including this strong baseline in the future development of CL algorithms, due to its demonstrated state-of-the-art performance.
Read more7/8/2024
🧠
0
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
Read more4/24/2024
0
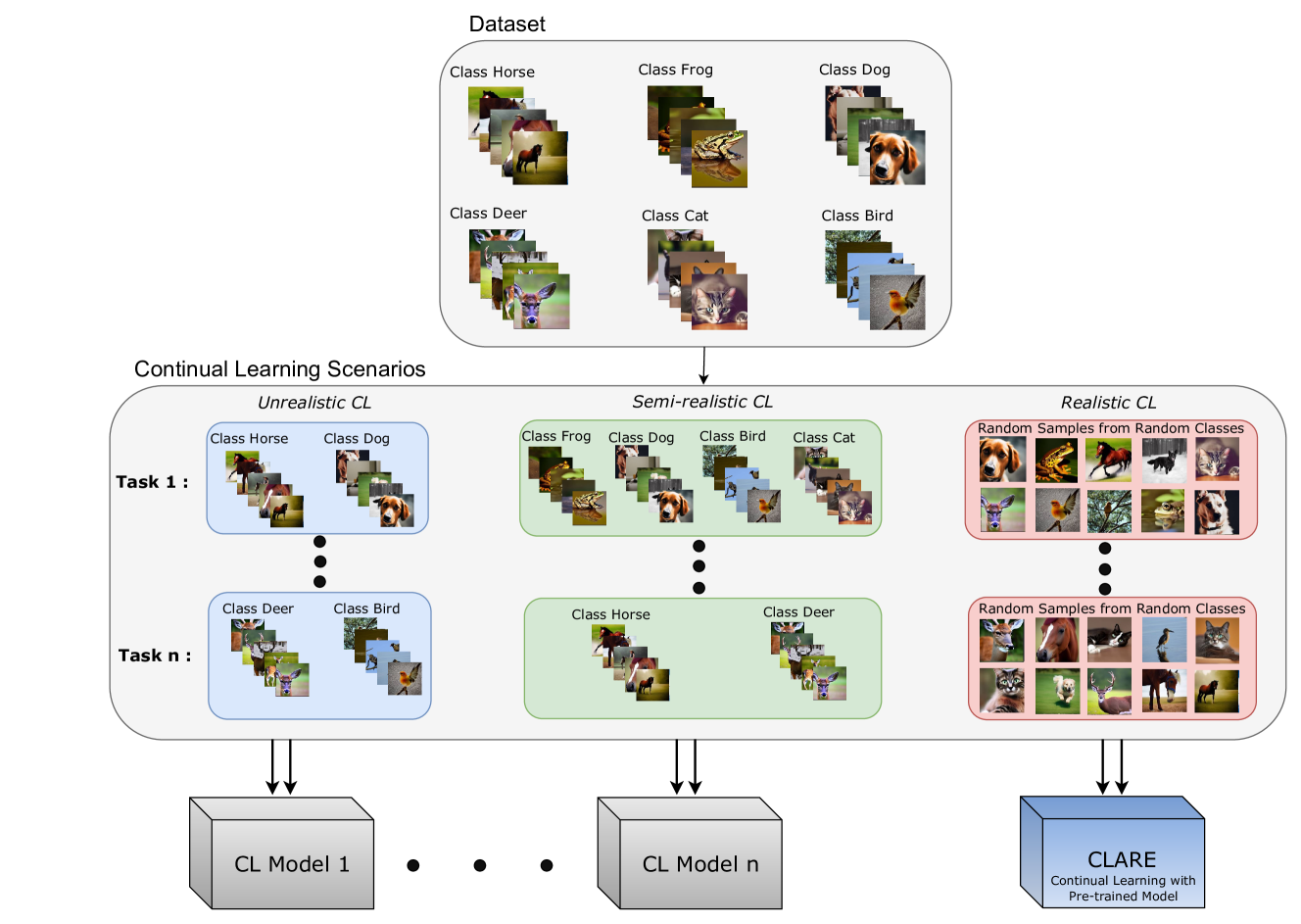
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Read more4/12/2024