Reassessing the Validity of Spurious Correlations Benchmarks

0
👀
Sign in to get full access
Overview
- This paper examines the validity of commonly used machine learning benchmarks and their susceptibility to spurious correlations.
- The authors conduct experiments to assess the robustness of models to such correlations and propose strategies to mitigate them.
- The findings have important implications for the development of reliable and unbiased AI systems.
Plain English Explanation
Machine learning models are often trained on datasets that contain shortcuts or "spurious correlations" - patterns in the data that are not actually meaningful but can still be used by the model to achieve high performance. This can lead to models that perform well on the test set but fail to generalize to real-world scenarios.
The authors of this paper investigate the extent of this problem by conducting experiments on several popular machine learning benchmarks. They find that many of these benchmarks are indeed vulnerable to spurious correlations, with models often relying on superficial cues rather than learning the underlying task.
To address this issue, the researchers propose strategies for making models more robust to such correlations, such as fine-grained analysis of model behavior and techniques for explicitly reducing the model's reliance on spurious features. These approaches can help ensure that AI systems are not simply memorizing patterns in the data, but are truly learning the underlying concepts.
Technical Explanation
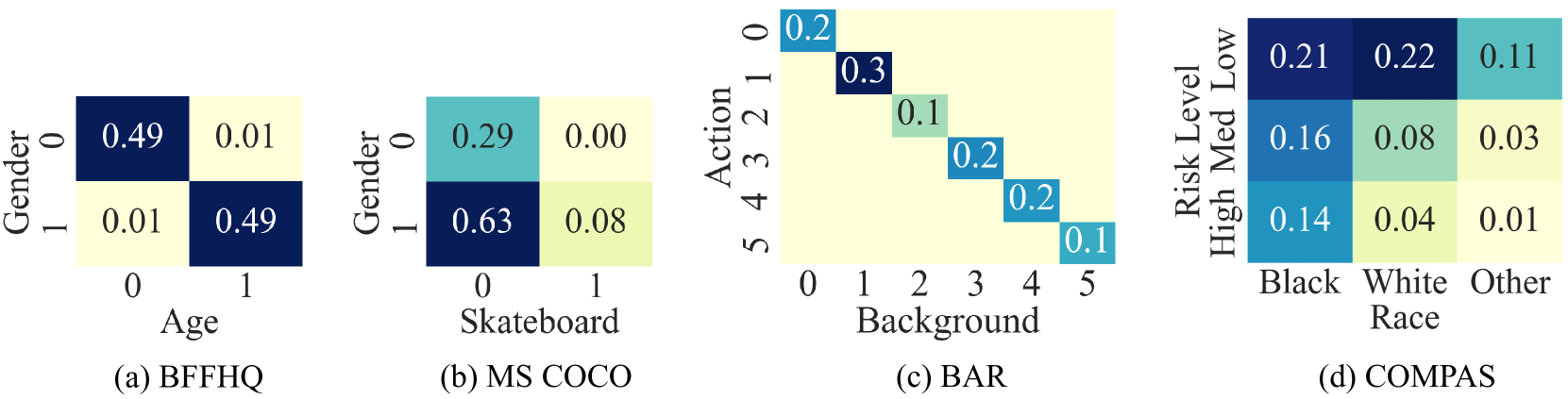
The paper begins by reassessing the validity of commonly used machine learning benchmarks. The authors conduct experiments on popular datasets like COCO, CIFAR, and ImageNet, and find that many of these benchmarks contain "spurious correlations" - patterns in the data that are not actually relevant to the task, but can still be used by models to achieve high performance.
To explore this issue further, the researchers survey the landscape of spurious correlations in machine learning. They identify several common sources of such correlations, such as dataset biases, shortcut learning by models, and the use of "easy" features that don't generalize well.
The paper then presents strategies for improving the robustness of models to spurious correlations. This includes techniques like fine-grained analysis of model behavior to identify the specific features that models are relying on, as well as methods for explicitly reducing the model's reliance on spurious features.
Critical Analysis
The paper provides a comprehensive and insightful analysis of the problem of spurious correlations in machine learning benchmarks. The experimental findings clearly demonstrate the extent to which many popular datasets and models are vulnerable to this issue.
However, the paper does not address the underlying causes of these spurious correlations in great detail. While the authors identify several common sources, a deeper exploration of the factors that lead to the emergence of these patterns in datasets could provide valuable insights for the research community.
Additionally, while the proposed strategies for improving model robustness are promising, their effectiveness may be limited by the inherent complexity of the problem. Spurious correlations can be subtle and context-dependent, making them challenging to detect and mitigate reliably.
Further research is needed to develop more sophisticated techniques for identifying and addressing the root causes of spurious correlations, as well as to explore the broader implications of this issue for the development of reliable and unbiased AI systems.
Conclusion
This paper makes a significant contribution to the understanding of the validity of machine learning benchmarks and the problem of spurious correlations. By conducting extensive experiments and proposing strategies for improving model robustness, the authors highlight the importance of this issue for the field of AI.
The findings have wide-ranging implications for the development of AI systems, as they underscore the need for greater rigor and scrutiny in the evaluation of machine learning models. Addressing the problem of spurious correlations is crucial for ensuring that AI systems are truly learning the underlying concepts and can generalize effectively to real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Reassessing the Validity of Spurious Correlations Benchmarks
Samuel J. Bell, Diane Bouchacourt, Levent Sagun
Neural networks can fail when the data contains spurious correlations. To understand this phenomenon, researchers have proposed numerous spurious correlations benchmarks upon which to evaluate mitigation methods. However, we observe that these benchmarks exhibit substantial disagreement, with the best methods on one benchmark performing poorly on another. We explore this disagreement, and examine benchmark validity by defining three desiderata that a benchmark should satisfy in order to meaningfully evaluate methods. Our results have implications for both benchmarks and mitigations: we find that certain benchmarks are not meaningful measures of method performance, and that several methods are not sufficiently robust for widespread use. We present a simple recipe for practitioners to choose methods using the most similar benchmark to their given problem.
Read more9/9/2024

0
Spurious Correlations in Machine Learning: A Survey
Wenqian Ye, Guangtao Zheng, Xu Cao, Yunsheng Ma, Aidong Zhang
Machine learning systems are known to be sensitive to spurious correlations between non-essential features of the inputs (e.g., background, texture, and secondary objects) and the corresponding labels. These features and their correlations with the labels are known as spurious because they tend to change with shifts in real-world data distributions, which can negatively impact the model's generalization and robustness. In this paper, we provide a review of this issue, along with a taxonomy of current state-of-the-art methods for addressing spurious correlations in machine learning models. Additionally, we summarize existing datasets, benchmarks, and metrics to aid future research. The paper concludes with a discussion of the recent advancements and future challenges in this field, aiming to provide valuable insights for researchers in the related domains.
Read more5/20/2024

0
Exploring Cross-model Neuronal Correlations in the Context of Predicting Model Performance and Generalizability
Haniyeh Ehsani Oskouie, Lionel Levine, Majid Sarrafzadeh
As Artificial Intelligence (AI) models are increasingly integrated into critical systems, the need for a robust framework to establish the trustworthiness of AI is increasingly paramount. While collaborative efforts have established conceptual foundations for such a framework, there remains a significant gap in developing concrete, technically robust methods for assessing AI model quality and performance. A critical drawback in the traditional methods for assessing the validity and generalizability of models is their dependence on internal developer datasets, rendering it challenging to independently assess and verify their performance claims. This paper introduces a novel approach for assessing a newly trained model's performance based on another known model by calculating correlation between neural networks. The proposed method evaluates correlations by determining if, for each neuron in one network, there exists a neuron in the other network that produces similar output. This approach has implications for memory efficiency, allowing for the use of smaller networks when high correlation exists between networks of different sizes. Additionally, the method provides insights into robustness, suggesting that if two highly correlated networks are compared and one demonstrates robustness when operating in production environments, the other is likely to exhibit similar robustness. This contribution advances the technical toolkit for responsible AI, supporting more comprehensive and nuanced evaluations of AI models to ensure their safe and effective deployment. Code is available at https://github.com/aheldis/Cross-model-correlation.git.
Read more9/12/2024
0
Towards Real World Debiasing: A Fine-grained Analysis On Spurious Correlation
Zhibo Wang, Peng Kuang, Zhixuan Chu, Jingyi Wang, Kui Ren
Spurious correlations in training data significantly hinder the generalization capability of machine learning models when faced with distribution shifts in real-world scenarios. To tackle the problem, numerous debias approaches have been proposed and benchmarked on datasets intentionally designed with severe biases. However, it remains to be asked: textit{1. Do existing benchmarks really capture biases in the real world? 2. Can existing debias methods handle biases in the real world?} To answer the questions, we revisit biased distributions in existing benchmarks and real-world datasets, and propose a fine-grained framework for analyzing dataset bias by disentangling it into the magnitude and prevalence of bias. We observe and theoretically demonstrate that existing benchmarks poorly represent real-world biases. We further introduce two novel biased distributions to bridge this gap, forming a nuanced evaluation framework for real-world debiasing. Building upon these results, we evaluate existing debias methods with our evaluation framework. Results show that existing methods are incapable of handling real-world biases. Through in-depth analysis, we propose a simple yet effective approach that can be easily applied to existing debias methods, named Debias in Destruction (DiD). Empirical results demonstrate the superiority of DiD, improving the performance of existing methods on all types of biases within the proposed evaluation framework.
Read more5/31/2024