Towards Real World Debiasing: A Fine-grained Analysis On Spurious Correlation

0
Sign in to get full access
Overview
- This paper presents a fine-grained analysis on spurious correlations in datasets, which can lead to biases in machine learning models.
- The researchers investigate how different dataset properties, such as label skew and feature correlations, can introduce biases that are difficult to detect and mitigate.
- They propose a new framework for understanding and quantifying these biases, which could help develop more robust and debiased machine learning models.
Plain English Explanation
Machine learning models can sometimes learn patterns in data that are not actually meaningful, but are simply quirks of the specific dataset being used. These "spurious correlations" can lead to biases in the model's predictions, which can be harmful when the model is deployed in the real world.
For example, imagine a model trained to predict a person's income based on their demographic information. If the training data happens to contain a strong correlation between a certain race and high income, the model might learn to associate that race with high income, even though the true causal relationship is more complex. This kind of bias can lead to unfair and discriminatory outcomes when the model is used to make real-world decisions.
The researchers in this paper wanted to take a closer look at how these spurious correlations arise and how they can be measured and mitigated. They explored different properties of datasets, such as how the labels are distributed and how the features are correlated, to understand how these factors contribute to the introduction of biases.
By developing a more nuanced framework for understanding dataset biases, the researchers hope to help machine learning practitioners build models that are more robust and fair, and less susceptible to the pitfalls of spurious correlations. This could have important implications for a wide range of applications, from hiring decisions to credit scoring.
Technical Explanation
The paper presents a fine-grained analysis on bias in datasets, exploring how different dataset properties can introduce spurious correlations that lead to biases in machine learning models.
The researchers first introduce a framework for quantifying these biases, building on previous work on measuring dataset bias. They define two key factors: label skew, which measures the imbalance in the distribution of target labels, and feature correlation, which captures the strength of relationships between input features and the target.
Using this framework, the authors conduct a series of experiments on synthetic and real-world datasets. They systematically vary the label skew and feature correlation, and observe how these dataset properties impact the performance and biases of various machine learning models, including deep neural networks and large language models.
The results reveal that both label skew and feature correlation can significantly contribute to the introduction of biases, and that the interplay between these factors is complex. The researchers also find that debiasing techniques, such as data augmentation and adversarial training, can be effective in mitigating these biases, but their effectiveness depends on the specific dataset characteristics.
Critical Analysis
The paper provides a thorough and thoughtful analysis of the role of dataset properties in the emergence of biases in machine learning models. The proposed framework for quantifying label skew and feature correlation is a useful tool for understanding and diagnosing these issues.
However, the authors acknowledge that their analysis is limited to relatively simple synthetic and real-world datasets, and that the interplay between dataset properties and model biases may be even more complex in larger, more realistic scenarios. Additionally, the effectiveness of debiasing techniques may depend on factors beyond just the dataset properties, such as the model architecture and the specific learning task.
It would be interesting to see the researchers extend their analysis to more diverse and challenging datasets, and explore the broader implications of their findings for the responsible development and deployment of machine learning systems. Addressing the problem of dataset bias is crucial for ensuring that these technologies are equitable and fair, and the insights from this paper represent an important step in that direction.
Conclusion
This paper presents a detailed investigation into the role of dataset properties in the emergence of biases in machine learning models. The researchers propose a framework for quantifying label skew and feature correlation, and use this to systematically study how these factors contribute to the introduction of spurious correlations.
The key findings suggest that both label skew and feature correlation can significantly impact model biases, and that the interplay between these factors is complex. The researchers also demonstrate that while debiasing techniques can be effective, their success depends on the specific dataset characteristics.
These insights have important implications for the development of robust and fair machine learning systems, and could help guide future research and practical applications in this critical area. By taking a fine-grained approach to understanding dataset biases, the paper lays the groundwork for more principled and effective debiasing strategies, which will be crucial as machine learning becomes increasingly pervasive in our society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Real World Debiasing: A Fine-grained Analysis On Spurious Correlation
Zhibo Wang, Peng Kuang, Zhixuan Chu, Jingyi Wang, Kui Ren
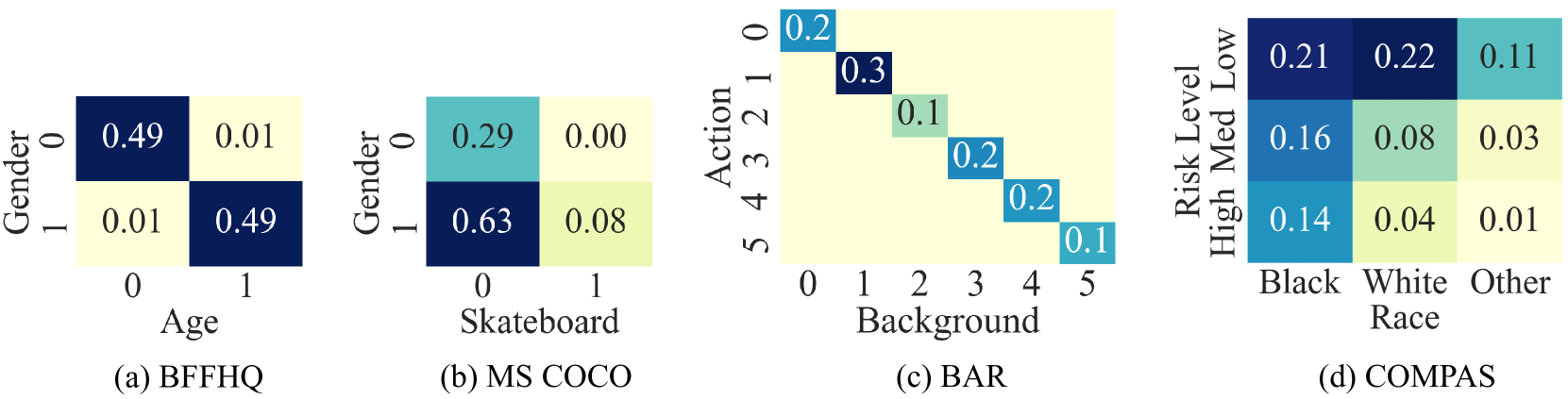
Spurious correlations in training data significantly hinder the generalization capability of machine learning models when faced with distribution shifts in real-world scenarios. To tackle the problem, numerous debias approaches have been proposed and benchmarked on datasets intentionally designed with severe biases. However, it remains to be asked: textit{1. Do existing benchmarks really capture biases in the real world? 2. Can existing debias methods handle biases in the real world?} To answer the questions, we revisit biased distributions in existing benchmarks and real-world datasets, and propose a fine-grained framework for analyzing dataset bias by disentangling it into the magnitude and prevalence of bias. We observe and theoretically demonstrate that existing benchmarks poorly represent real-world biases. We further introduce two novel biased distributions to bridge this gap, forming a nuanced evaluation framework for real-world debiasing. Building upon these results, we evaluate existing debias methods with our evaluation framework. Results show that existing methods are incapable of handling real-world biases. Through in-depth analysis, we propose a simple yet effective approach that can be easily applied to existing debias methods, named Debias in Destruction (DiD). Empirical results demonstrate the superiority of DiD, improving the performance of existing methods on all types of biases within the proposed evaluation framework.
Read more5/31/2024

0
Looking at Model Debiasing through the Lens of Anomaly Detection
Vito Paolo Pastore, Massimiliano Ciranni, Davide Marinelli, Francesca Odone, Vittorio Murino
It is widely recognized that deep neural networks are sensitive to bias in the data. This means that during training these models are likely to learn spurious correlations between data and labels, resulting in limited generalization abilities and low performance. In this context, model debiasing approaches can be devised aiming at reducing the model's dependency on such unwanted correlations, either leveraging the knowledge of bias information or not. In this work, we focus on the latter and more realistic scenario, showing the importance of accurately predicting the bias-conflicting and bias-aligned samples to obtain compelling performance in bias mitigation. On this ground, we propose to conceive the problem of model bias from an out-of-distribution perspective, introducing a new bias identification method based on anomaly detection. We claim that when data is mostly biased, bias-conflicting samples can be regarded as outliers with respect to the bias-aligned distribution in the feature space of a biased model, thus allowing for precisely detecting them with an anomaly detection method. Coupling the proposed bias identification approach with bias-conflicting data upsampling and augmentation in a two-step strategy, we reach state-of-the-art performance on synthetic and real benchmark datasets. Ultimately, our proposed approach shows that the data bias issue does not necessarily require complex debiasing methods, given that an accurate bias identification procedure is defined.
Read more7/26/2024

0
Editable Fairness: Fine-Grained Bias Mitigation in Language Models
Ruizhe Chen, Yichen Li, Jianfei Yang, Joey Tianyi Zhou, Zuozhu Liu
Generating fair and accurate predictions plays a pivotal role in deploying large language models (LLMs) in the real world. However, existing debiasing methods inevitably generate unfair or incorrect predictions as they are designed and evaluated to achieve parity across different social groups but leave aside individual commonsense facts, resulting in modified knowledge that elicits unreasonable or undesired predictions. In this paper, we first establish a new bias mitigation benchmark, BiaScope, which systematically assesses performance by leveraging newly constructed datasets and metrics on knowledge retention and generalization. Then, we propose a novel debiasing approach, Fairness Stamp (FAST), which enables fine-grained calibration of individual social biases. FAST identifies the decisive layer responsible for storing social biases and then calibrates its outputs by integrating a small modular network, considering both bias mitigation and knowledge-preserving demands. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with superior debiasing performance while not compromising the overall model capability for knowledge retention and downstream predictions. This highlights the potential of fine-grained debiasing strategies to achieve fairness in LLMs. Code will be publicly available.
Read more8/23/2024
0
Language-guided Detection and Mitigation of Unknown Dataset Bias
Zaiying Zhao, Soichiro Kumano, Toshihiko Yamasaki
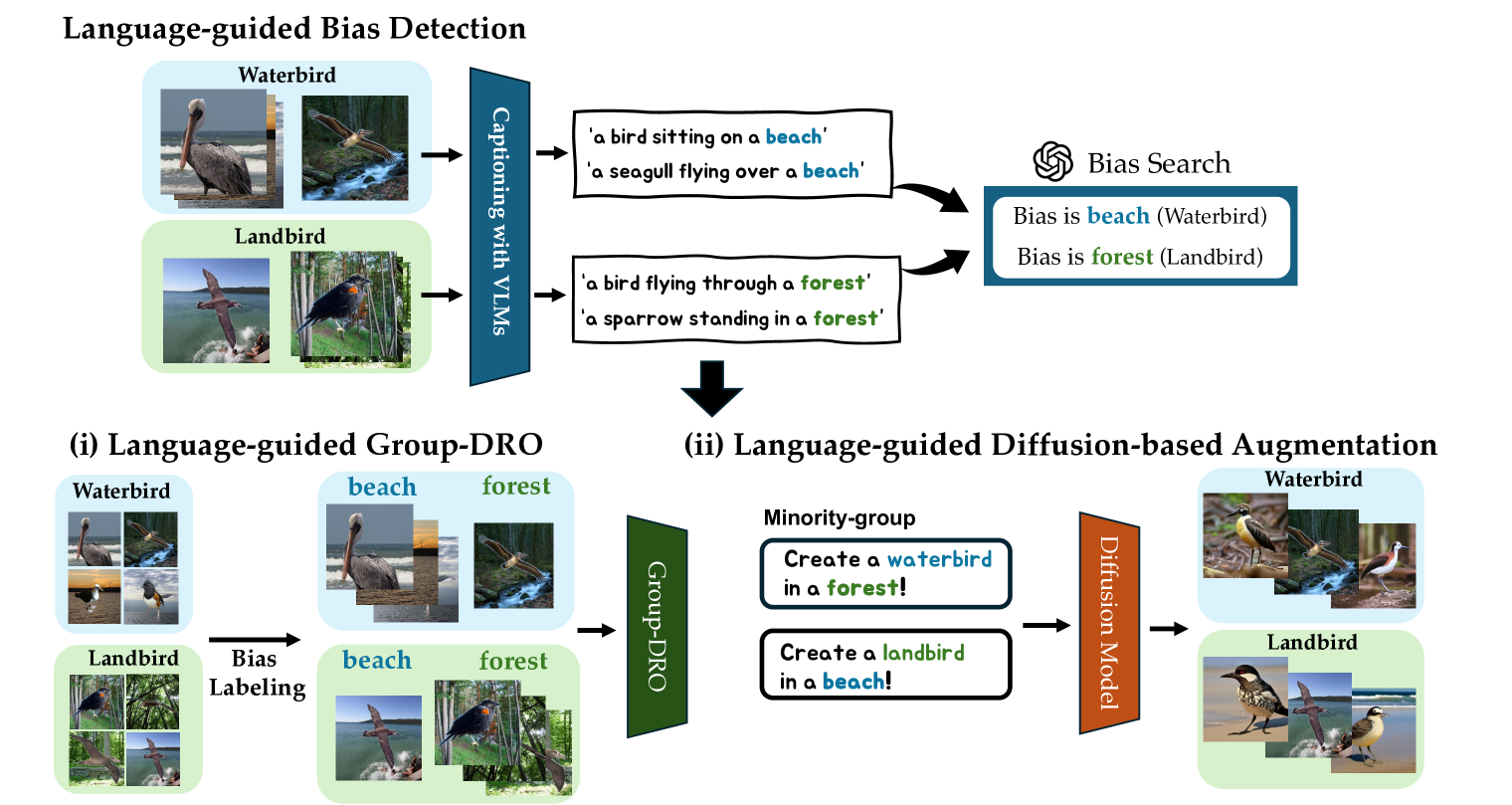
Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
Read more6/6/2024