Recent Advances in Attack and Defense Approaches of Large Language Models

0
💬
Sign in to get full access
Overview
- Provides a plain English summary of a technical paper on recent advances in attack and defense approaches for large language models (LLMs).
- Covers the key ideas, experiment design, and insights from the paper.
- Discusses the caveats, limitations, and areas for further research.
- Encourages critical thinking about the research and its implications.
Plain English Explanation
This paper examines the growing vulnerabilities and defense strategies for large language models, which are powerful AI systems that can generate human-like text. As these models become more advanced and widely used, they are increasingly targets for cyber attacks.
The researchers review the latest techniques that can fool or manipulate LLMs, such as adversarial attacks that slightly modify the input to get the model to produce unintended outputs. They also cover defense strategies that can make LLMs more robust and secure.
The key takeaway is that as LLMs become more powerful and ubiquitous, there is a growing need to understand and mitigate their vulnerabilities to ensure they are used safely and responsibly.
Technical Explanation
The paper provides a comprehensive review of the latest advances in attack and defense approaches for large language models (LLMs). The researchers examine a wide range of attack techniques, including adversarial attacks, model inversion attacks, and membership inference attacks, which aim to fool or manipulate LLMs to produce unintended outputs.
To assess the effectiveness of these attacks, the researchers conduct experiments on several popular LLM architectures, such as GPT-3 and BERT. They find that even small, imperceptible perturbations to the input can lead to significant changes in the model's behavior, highlighting the fragility of these systems.
The paper also reviews various defense strategies that can be used to enhance the robustness and security of LLMs, such as adversarial training, input sanitization, and model hardening. The researchers evaluate the effectiveness of these defenses and discuss their trade-offs, such as the potential impact on model performance.
Critical Analysis
The paper provides a thorough and well-researched overview of the vulnerabilities and defense approaches for large language models, which is an important and timely topic. The researchers have done an admirable job of surveying the latest advancements in this rapidly evolving field.
However, the paper does not delve deeply into the long-term implications of these security issues, such as the potential for malicious actors to misuse LLMs for harmful purposes. Additionally, the paper could benefit from a more critical examination of the limitations and potential unintended consequences of the proposed defense strategies, as well as a discussion of alternative approaches or future research directions.
Conclusion
This paper offers a comprehensive look at the growing vulnerabilities and defense strategies for large language models, which are becoming increasingly important and influential in various applications. As these powerful AI systems continue to advance, it is crucial to understand their potential weaknesses and develop robust security measures to ensure they are used responsibly and safely. This research provides a valuable contribution to the ongoing efforts to address the challenges and opportunities presented by large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Recent Advances in Attack and Defense Approaches of Large Language Models
Jing Cui, Yishi Xu, Zhewei Huang, Shuchang Zhou, Jianbin Jiao, Junge Zhang
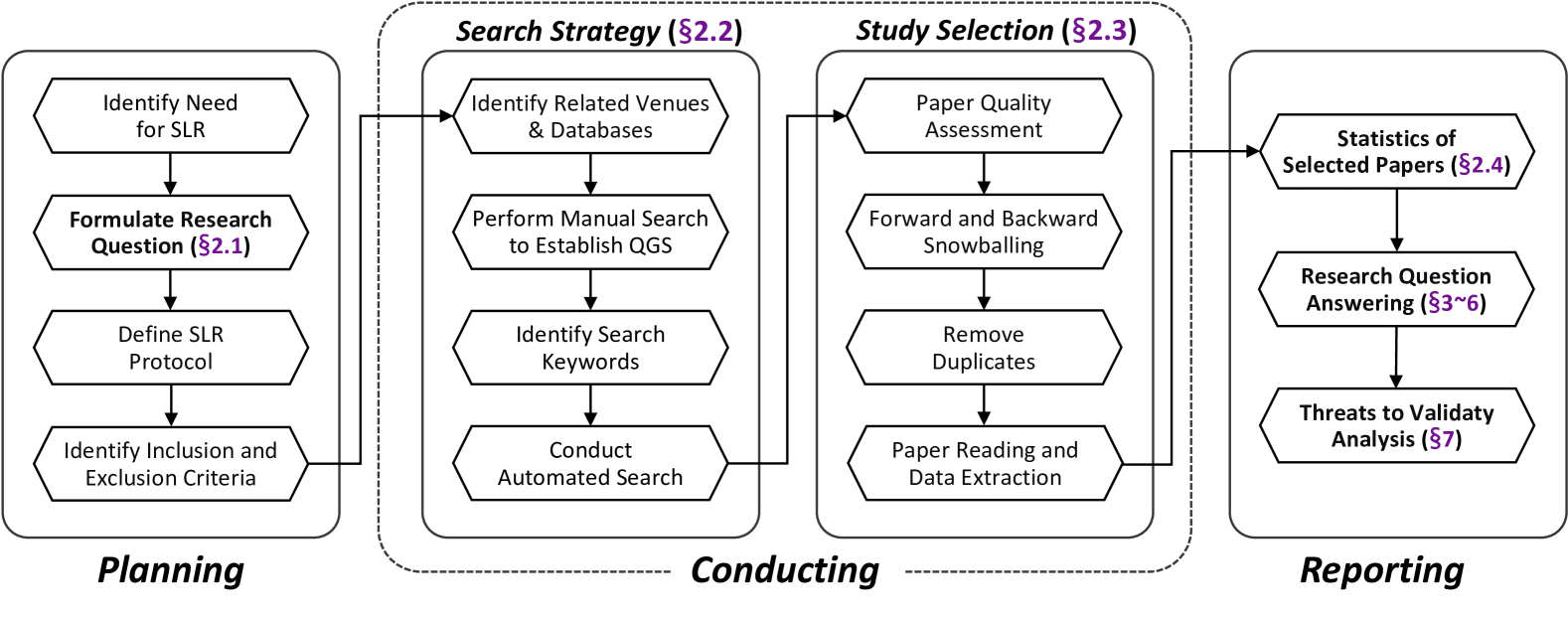
Large Language Models (LLMs) have revolutionized artificial intelligence and machine learning through their advanced text processing and generating capabilities. However, their widespread deployment has raised significant safety and reliability concerns. Established vulnerabilities in deep neural networks, coupled with emerging threat models, may compromise security evaluations and create a false sense of security. Given the extensive research in the field of LLM security, we believe that summarizing the current state of affairs will help the research community better understand the present landscape and inform future developments. This paper reviews current research on LLM vulnerabilities and threats, and evaluates the effectiveness of contemporary defense mechanisms. We analyze recent studies on attack vectors and model weaknesses, providing insights into attack mechanisms and the evolving threat landscape. We also examine current defense strategies, highlighting their strengths and limitations. By contrasting advancements in attack and defense methodologies, we identify research gaps and propose future directions to enhance LLM security. Our goal is to advance the understanding of LLM safety challenges and guide the development of more robust security measures.
Read more9/9/2024
0
Large Language Models for Cyber Security: A Systematic Literature Review
Hanxiang Xu, Shenao Wang, Ningke Li, Kailong Wang, Yanjie Zhao, Kai Chen, Ting Yu, Yang Liu, Haoyu Wang
The rapid advancement of Large Language Models (LLMs) has opened up new opportunities for leveraging artificial intelligence in various domains, including cybersecurity. As the volume and sophistication of cyber threats continue to grow, there is an increasing need for intelligent systems that can automatically detect vulnerabilities, analyze malware, and respond to attacks. In this survey, we conduct a comprehensive review of the literature on the application of LLMs in cybersecurity (LLM4Security). By comprehensively collecting over 30K relevant papers and systematically analyzing 127 papers from top security and software engineering venues, we aim to provide a holistic view of how LLMs are being used to solve diverse problems across the cybersecurity domain. Through our analysis, we identify several key findings. First, we observe that LLMs are being applied to a wide range of cybersecurity tasks, including vulnerability detection, malware analysis, network intrusion detection, and phishing detection. Second, we find that the datasets used for training and evaluating LLMs in these tasks are often limited in size and diversity, highlighting the need for more comprehensive and representative datasets. Third, we identify several promising techniques for adapting LLMs to specific cybersecurity domains, such as fine-tuning, transfer learning, and domain-specific pre-training. Finally, we discuss the main challenges and opportunities for future research in LLM4Security, including the need for more interpretable and explainable models, the importance of addressing data privacy and security concerns, and the potential for leveraging LLMs for proactive defense and threat hunting. Overall, our survey provides a comprehensive overview of the current state-of-the-art in LLM4Security and identifies several promising directions for future research.
Read more7/30/2024
0
Exploring Vulnerabilities and Protections in Large Language Models: A Survey
Frank Weizhen Liu, Chenhui Hu
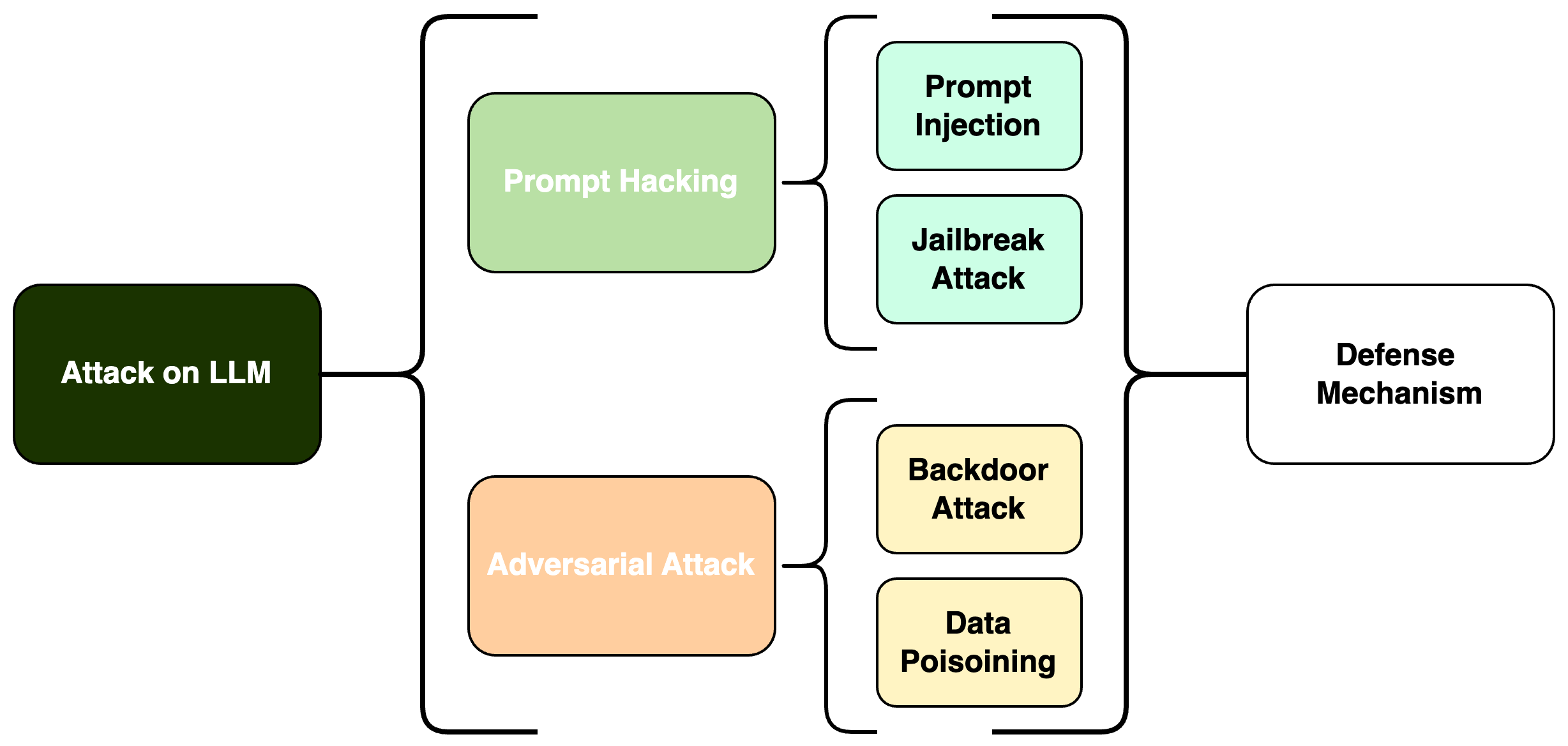
As Large Language Models (LLMs) increasingly become key components in various AI applications, understanding their security vulnerabilities and the effectiveness of defense mechanisms is crucial. This survey examines the security challenges of LLMs, focusing on two main areas: Prompt Hacking and Adversarial Attacks, each with specific types of threats. Under Prompt Hacking, we explore Prompt Injection and Jailbreaking Attacks, discussing how they work, their potential impacts, and ways to mitigate them. Similarly, we analyze Adversarial Attacks, breaking them down into Data Poisoning Attacks and Backdoor Attacks. This structured examination helps us understand the relationships between these vulnerabilities and the defense strategies that can be implemented. The survey highlights these security challenges and discusses robust defensive frameworks to protect LLMs against these threats. By detailing these security issues, the survey contributes to the broader discussion on creating resilient AI systems that can resist sophisticated attacks.
Read more6/4/2024

0
Can LLMs be Fooled? Investigating Vulnerabilities in LLMs
Sara Abdali, Jia He, CJ Barberan, Richard Anarfi
The advent of Large Language Models (LLMs) has garnered significant popularity and wielded immense power across various domains within Natural Language Processing (NLP). While their capabilities are undeniably impressive, it is crucial to identify and scrutinize their vulnerabilities especially when those vulnerabilities can have costly consequences. One such LLM, trained to provide a concise summarization from medical documents could unequivocally leak personal patient data when prompted surreptitiously. This is just one of many unfortunate examples that have been unveiled and further research is necessary to comprehend the underlying reasons behind such vulnerabilities. In this study, we delve into multiple sections of vulnerabilities which are model-based, training-time, inference-time vulnerabilities, and discuss mitigation strategies including Model Editing which aims at modifying LLMs behavior, and Chroma Teaming which incorporates synergy of multiple teaming strategies to enhance LLMs' resilience. This paper will synthesize the findings from each vulnerability section and propose new directions of research and development. By understanding the focal points of current vulnerabilities, we can better anticipate and mitigate future risks, paving the road for more robust and secure LLMs.
Read more7/31/2024