On the Recoverability of Causal Relations from Temporally Aggregated I.I.D. Data

0
Sign in to get full access
Overview
- This paper investigates the ability to recover causal relationships from temporally aggregated data that is independent and identically distributed (i.i.d.).
- The authors examine the conditions under which causal effects can be identified from such data, and propose new methods for causal discovery.
- The paper makes several theoretical contributions and introduces new algorithms for causal discovery.
Plain English Explanation
Understanding the underlying causal relationships in data is a fundamental problem in many fields, from economics to machine learning. However, this can be challenging when the data is aggregated over time, as the temporal information is lost.
This paper explores the question of whether causal relationships can still be recovered from such temporally aggregated, i.i.d. data. The authors provide theoretical analysis and new algorithms to address this problem. They show that under certain conditions, it is indeed possible to infer causal effects from this type of data, which could have important implications for causal discovery and time series analysis.
For example, imagine a scenario where you have data on the daily sales of a product and the weather conditions. Even though the data is collected daily, it may be aggregated and reported weekly or monthly. The authors' work suggests that it is possible to uncover the causal relationship between the weather and sales, despite this temporal aggregation, which could inform business decisions and causal modelling.
Technical Explanation
The paper formally analyzes the problem of causal discovery from temporally aggregated i.i.d. data. The authors establish theoretical conditions under which causal effects can be identified from such data, and propose new algorithms to recover these causal relationships.
Specifically, the paper makes the following key contributions:
- Characterization of the causal identifiability conditions for temporally aggregated i.i.d. data. The authors derive necessary and sufficient conditions for the recoverability of causal effects from this type of data.
- Development of new causal discovery algorithms. The authors introduce novel techniques for inferring causal structure from temporally aggregated data, building on existing causal discovery methods.
- Empirical evaluation of the proposed approaches. The authors demonstrate the effectiveness of their methods through experiments on both synthetic and real-world datasets.
The paper provides a rigorous theoretical foundation for understanding the limitations and possibilities of causal discovery from temporally aggregated i.i.d. data. The new algorithms introduced in this work could have significant practical implications for a wide range of applications where such data is commonly encountered.
Critical Analysis
The paper makes important theoretical contributions to the field of causal discovery and provides new algorithmic tools for working with temporally aggregated data. However, the authors acknowledge several caveats and limitations of their work.
One key assumption is that the underlying data is i.i.d., which may not always hold in real-world scenarios. The authors suggest exploring extensions to non-i.i.d. settings as an area for future research.
Additionally, the paper focuses on the recoverability of causal effects, but does not address the issue of statistical efficiency. It may be the case that even when causal effects are identifiable, the finite-sample performance of the proposed algorithms could be suboptimal. Investigating methods to improve the statistical efficiency of causal discovery from aggregated data is another potential direction for further study.
Finally, while the theoretical results provide important insights, the practical applicability of the proposed techniques may depend on the specific characteristics of the data and the causal structures involved. Careful consideration of the assumptions and limitations is crucial when applying these methods to real-world problems.
Conclusion
This paper makes significant theoretical and algorithmic contributions to the field of causal discovery, by investigating the recoverability of causal relations from temporally aggregated i.i.d. data. The authors provide a rigorous analysis of the identifiability conditions and introduce new techniques for inferring causal structure from this type of data.
The findings of this work could have important implications for a wide range of applications, from economics and social science to machine learning and time series analysis, where temporally aggregated data is commonly encountered. The new algorithms and theoretical insights introduced in this paper represent an important step forward in addressing the challenges of causal discovery under data aggregation.
While the paper acknowledges several caveats and limitations, it opens up new avenues for future research, such as extending the analysis to non-i.i.d. settings and improving the statistical efficiency of causal discovery from aggregated data. Overall, this work contributes significantly to our understanding of the fundamental limits and possibilities of causal inference in the context of temporally aggregated information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Recoverability of Causal Relations from Temporally Aggregated I.I.D. Data
Shunxing Fan, Mingming Gong, Kun Zhang
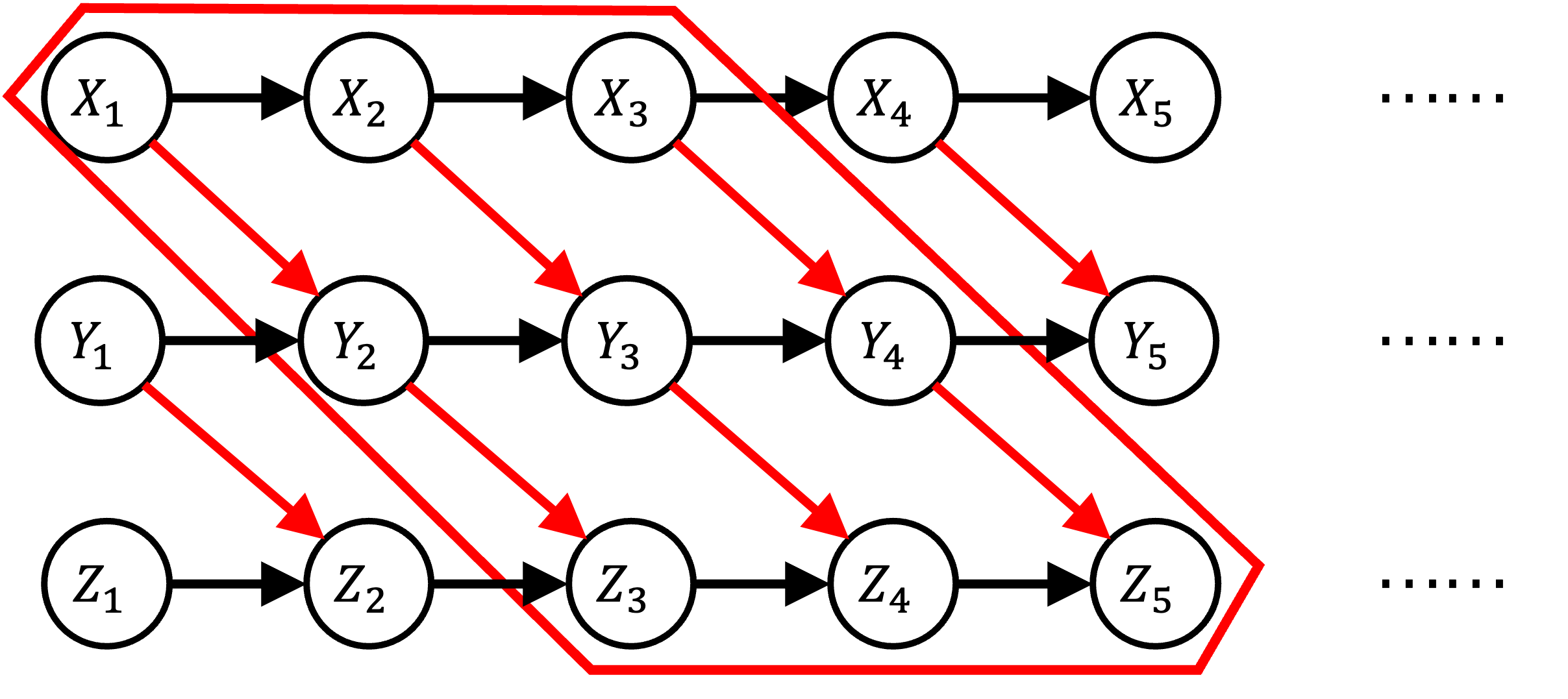
We consider the effect of temporal aggregation on instantaneous (non-temporal) causal discovery in general setting. This is motivated by the observation that the true causal time lag is often considerably shorter than the observational interval. This discrepancy leads to high aggregation, causing time-delay causality to vanish and instantaneous dependence to manifest. Although we expect such instantaneous dependence has consistency with the true causal relation in certain sense to make the discovery results meaningful, it remains unclear what type of consistency we need and when will such consistency be satisfied. We proposed functional consistency and conditional independence consistency in formal way correspond functional causal model-based methods and conditional independence-based methods respectively and provide the conditions under which these consistencies will hold. We show theoretically and experimentally that causal discovery results may be seriously distorted by aggregation especially in complete nonlinear case and we also find causal relationship still recoverable from aggregated data if we have partial linearity or appropriate prior. Our findings suggest community should take a cautious and meticulous approach when interpreting causal discovery results from such data and show why and when aggregation will distort the performance of causal discovery methods.
Read more9/11/2024

0
On the Identification of Temporally Causal Representation with Instantaneous Dependence
Zijian Li, Yifan Shen, Kaitao Zheng, Ruichu Cai, Xiangchen Song, Mingming Gong, Zhengmao Zhu, Guangyi Chen, Kun Zhang
Temporally causal representation learning aims to identify the latent causal process from time series observations, but most methods require the assumption that the latent causal processes do not have instantaneous relations. Although some recent methods achieve identifiability in the instantaneous causality case, they require either interventions on the latent variables or grouping of the observations, which are in general difficult to obtain in real-world scenarios. To fill this gap, we propose an textbf{ID}entification framework for instantanetextbf{O}us textbf{L}atent dynamics (textbf{IDOL}) by imposing a sparse influence constraint that the latent causal processes have sparse time-delayed and instantaneous relations. Specifically, we establish identifiability results of the latent causal process based on sufficient variability and the sparse influence constraint by employing contextual information of time series data. Based on these theories, we incorporate a temporally variational inference architecture to estimate the latent variables and a gradient-based sparsity regularization to identify the latent causal process. Experimental results on simulation datasets illustrate that our method can identify the latent causal process. Furthermore, evaluations on multiple human motion forecasting benchmarks with instantaneous dependencies indicate the effectiveness of our method in real-world settings.
Read more6/10/2024
📶
0
Identifiability of total effects from abstractions of time series causal graphs
Charles K. Assaad, Emilie Devijver, Eric Gaussier, Gregor Gossler, Anouar Meynaoui
We study the problem of identifiability of the total effect of an intervention from observational time series in the situation, common in practice, where one only has access to abstractions of the true causal graph. We consider here two abstractions: the extended summary causal graph, which conflates all lagged causal relations but distinguishes between lagged and instantaneous relations, and the summary causal graph which does not give any indication about the lag between causal relations. We show that the total effect is always identifiable in extended summary causal graphs and provide sufficient conditions for identifiability in summary causal graphs. We furthermore provide adjustment sets allowing to estimate the total effect whenever it is identifiable.
Read more5/21/2024
🔮
0
Temporally Disentangled Representation Learning under Unknown Nonstationarity
Xiangchen Song, Weiran Yao, Yewen Fan, Xinshuai Dong, Guangyi Chen, Juan Carlos Niebles, Eric Xing, Kun Zhang
In unsupervised causal representation learning for sequential data with time-delayed latent causal influences, strong identifiability results for the disentanglement of causally-related latent variables have been established in stationary settings by leveraging temporal structure. However, in nonstationary setting, existing work only partially addressed the problem by either utilizing observed auxiliary variables (e.g., class labels and/or domain indexes) as side information or assuming simplified latent causal dynamics. Both constrain the method to a limited range of scenarios. In this study, we further explored the Markov Assumption under time-delayed causally related process in nonstationary setting and showed that under mild conditions, the independent latent components can be recovered from their nonlinear mixture up to a permutation and a component-wise transformation, without the observation of auxiliary variables. We then introduce NCTRL, a principled estimation framework, to reconstruct time-delayed latent causal variables and identify their relations from measured sequential data only. Empirical evaluations demonstrated the reliable identification of time-delayed latent causal influences, with our methodology substantially outperforming existing baselines that fail to exploit the nonstationarity adequately and then, consequently, cannot distinguish distribution shifts.
Read more8/2/2024