Red-Teaming for Generative AI: Silver Bullet or Security Theater?

0
🔄
Sign in to get full access
Overview
- Concerns around the safety, security, and trustworthiness of Generative AI (GenAI) models have led to increased focus on AI red-teaming as a mitigation strategy.
- However, there are significant questions about what AI red-teaming entails, its role in regulation, and how it differs from conventional red-teaming in cybersecurity.
- This paper aims to characterize the scope, structure, and criteria for AI red-teaming practices by surveying recent industry cases and relevant research literature.
Plain English Explanation
As Generative AI models become more powerful and widespread, there are growing concerns about their safety, security, and trustworthiness. In response, practitioners and regulators have pointed to "AI red-teaming" as a key strategy for identifying and addressing these risks.
Red-teaming is a security practice where a team (the "red team") tries to uncover vulnerabilities by attacking a system from the perspective of a real-world adversary. However, when it comes to AI systems, it's not entirely clear what "AI red-teaming" means or how it relates to traditional red-teaming methods.
This paper takes a closer look at how AI red-teaming is being applied in industry and academia. The authors survey recent real-world cases and existing research to understand the scope, structure, and goals of these red-teaming activities. They find that there is a lot of variation in how AI red-teaming is actually carried out, with differences in the purpose, the artifacts being evaluated, the settings, and the resulting decisions.
While the authors see value in the broader idea of "red-teaming" as a way to characterize GenAI harm mitigation, they caution that industry's use of red-teaming may amount to little more than "security theater" - giving the impression of rigorous testing without substantive improvements. To move towards more robust evaluations of Generative AI systems, the authors synthesize a set of guiding questions to help structure future AI red-teaming efforts.
Technical Explanation
The paper begins by noting the growing prominence of AI red-teaming in policy discussions and corporate messaging around Generative AI (GenAI) safety and security. However, the authors observe that there are significant open questions about what precisely AI red-teaming entails, what role it can play in regulation, and how it relates to conventional red-teaming practices from the field of cybersecurity.
To address these questions, the authors conduct an extensive survey of relevant research literature and identify recent cases of red-teaming activities in the AI industry. Through this analysis, they characterize the scope, structure, and criteria for AI red-teaming practices along several key dimensions:
-
Purpose: The underlying motivation for the red-teaming activity is often vague or unclear, ranging from general "harm mitigation" to more specific goals like evaluating model robustness or testing for adversarial examples.
-
Artifact: The target of the red-teaming effort can vary, from individual AI/ML models to larger AI systems or even the entire AI development lifecycle.
-
Setting: Red-teaming activities take place in diverse settings, involving different actors (e.g., internal teams, external "red teams"), resources, and methodologies.
-
Decisions: The outcomes of red-teaming activities may inform a variety of decisions, such as reporting, disclosure, and mitigation strategies, but the linkages are often unclear.
The authors argue that while red-teaming may be a valuable high-level concept for characterizing GenAI harm mitigation strategies, the current state of industry practice often amounts to little more than "security theater" - giving the appearance of rigor without substantive improvements. To move towards more robust evaluations of Generative AI systems, the authors synthesize a set of guiding questions intended to help structure future AI red-teaming efforts.
Critical Analysis
The authors raise several important caveats and limitations in their analysis of AI red-teaming practices:
-
Lack of Clarity: The authors find that the purpose, scope, and criteria for AI red-teaming are often vague or inconsistent, making it difficult to assess the effectiveness of these efforts.
-
Divergence from Cybersecurity: While drawing parallels to traditional red-teaming in cybersecurity, the authors note that AI red-teaming diverges in significant ways, raising questions about the applicability of those established methods.
-
Industry Opacity: Much of the red-teaming activity appears to be happening behind closed doors in industry, limiting the ability to scrutinize and learn from these practices.
-
Potential for Misuse: The authors caution that the rhetoric around AI red-teaming could be used to create a false sense of security, without meaningful improvements to AI safety and robustness.
These limitations highlight the need for greater transparency, rigor, and standardization in AI red-teaming practices. The authors' recommendations for a guiding question bank represent a positive step, but further research and collaboration between industry, academia, and regulators will be crucial to develop a more robust toolbox for evaluating Generative AI systems.
Conclusion
This paper provides a much-needed critical examination of the emerging practice of AI red-teaming, which has become a central component of industry and policy discussions around Generative AI safety and security. By surveying recent cases and relevant research, the authors reveal significant variation and lack of clarity in how red-teaming is being applied to AI systems.
While the authors see value in the broader concept of red-teaming as a framework for characterizing GenAI harm mitigation strategies, they caution that industry's current use of red-teaming often amounts to little more than "security theater." To move towards more robust evaluations of Generative AI, the authors synthesize a set of guiding questions to help structure future AI red-teaming efforts.
Ultimately, this paper highlights the need for greater transparency, collaboration, and standardization in the emerging field of AI red-teaming. As Generative AI systems become increasingly powerful and ubiquitous, developing rigorous and reliable methods for assessing their safety and security will be crucial for building public trust and safeguarding against potential harms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Red-Teaming for Generative AI: Silver Bullet or Security Theater?
Michael Feffer, Anusha Sinha, Wesley Hanwen Deng, Zachary C. Lipton, Hoda Heidari
In response to rising concerns surrounding the safety, security, and trustworthiness of Generative AI (GenAI) models, practitioners and regulators alike have pointed to AI red-teaming as a key component of their strategies for identifying and mitigating these risks. However, despite AI red-teaming's central role in policy discussions and corporate messaging, significant questions remain about what precisely it means, what role it can play in regulation, and how it relates to conventional red-teaming practices as originally conceived in the field of cybersecurity. In this work, we identify recent cases of red-teaming activities in the AI industry and conduct an extensive survey of relevant research literature to characterize the scope, structure, and criteria for AI red-teaming practices. Our analysis reveals that prior methods and practices of AI red-teaming diverge along several axes, including the purpose of the activity (which is often vague), the artifact under evaluation, the setting in which the activity is conducted (e.g., actors, resources, and methods), and the resulting decisions it informs (e.g., reporting, disclosure, and mitigation). In light of our findings, we argue that while red-teaming may be a valuable big-tent idea for characterizing GenAI harm mitigations, and that industry may effectively apply red-teaming and other strategies behind closed doors to safeguard AI, gestures towards red-teaming (based on public definitions) as a panacea for every possible risk verge on security theater. To move toward a more robust toolbox of evaluations for generative AI, we synthesize our recommendations into a question bank meant to guide and scaffold future AI red-teaming practices.
Read more8/29/2024
🤖
0
The Human Factor in AI Red Teaming: Perspectives from Social and Collaborative Computing
Alice Qian Zhang, Ryland Shaw, Jacy Reese Anthis, Ashlee Milton, Emily Tseng, Jina Suh, Lama Ahmad, Ram Shankar Siva Kumar, Julian Posada, Benjamin Shestakofsky, Sarah T. Roberts, Mary L. Gray
Rapid progress in general-purpose AI has sparked significant interest in red teaming, a practice of adversarial testing originating in military and cybersecurity applications. AI red teaming raises many questions about the human factor, such as how red teamers are selected, biases and blindspots in how tests are conducted, and harmful content's psychological effects on red teamers. A growing body of HCI and CSCW literature examines related practices-including data labeling, content moderation, and algorithmic auditing. However, few, if any have investigated red teaming itself. Future studies may explore topics ranging from fairness to mental health and other areas of potential harm. We aim to facilitate a community of researchers and practitioners who can begin to meet these challenges with creativity, innovation, and thoughtful reflection.
Read more9/12/2024
0
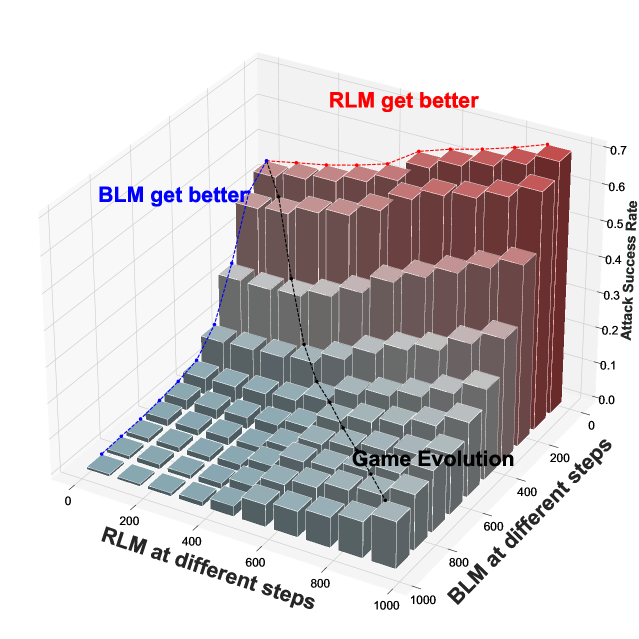
Red Teaming Game: A Game-Theoretic Framework for Red Teaming Language Models
Chengdong Ma, Ziran Yang, Hai Ci, Jun Gao, Minquan Gao, Xuehai Pan, Yaodong Yang
The primary challenge in deploying Large Language Model (LLM) is ensuring its harmlessness. Red team can identify vulnerabilities by attacking LLM to attain safety. However, current efforts heavily rely on single-round prompt designs and unilateral red team optimizations against fixed blue teams. These static approaches lead to significant reductions in generation diversity, known as the mode collapse, which makes it difficult to discover the potential risks in the increasingly complex human-LLM interactions. Here we introduce dynamic Red Team Game (RTG) to comprehensively analyze the multi-round offensive and defensive interactions between red team and blue team. Furthermore, we develop a Gamified Red Team Solver (GRTS) with diversity measures to mitigate mode collapse and theoretically guarantee the convergence of approximate Nash equilibrium which results in better strategies for both teams. Empirical results demonstrate that GRTS explore diverse and implicit attacks to adaptively exploit various LLMs, surpassing the constraints of specific modes. Insightfully, the geometrical structure we unveil of the red team task aligns with the spinning top hypothesis, confirming the necessity of constructing a diverse LLM population as a promising proxy for heterogeneous human expert red-teamers. This paves the way for scalable toxicity detection and safe alignment for LLMs.
Read more7/30/2024

0
ART: Automatic Red-teaming for Text-to-Image Models to Protect Benign Users
Guanlin Li, Kangjie Chen, Shudong Zhang, Jie Zhang, Tianwei Zhang
Large-scale pre-trained generative models are taking the world by storm, due to their abilities in generating creative content. Meanwhile, safeguards for these generative models are developed, to protect users' rights and safety, most of which are designed for large language models. Existing methods primarily focus on jailbreak and adversarial attacks, which mainly evaluate the model's safety under malicious prompts. Recent work found that manually crafted safe prompts can unintentionally trigger unsafe generations. To further systematically evaluate the safety risks of text-to-image models, we propose a novel Automatic Red-Teaming framework, ART. Our method leverages both vision language model and large language model to establish a connection between unsafe generations and their prompts, thereby more efficiently identifying the model's vulnerabilities. With our comprehensive experiments, we reveal the toxicity of the popular open-source text-to-image models. The experiments also validate the effectiveness, adaptability, and great diversity of ART. Additionally, we introduce three large-scale red-teaming datasets for studying the safety risks associated with text-to-image models. Datasets and models can be found in https://github.com/GuanlinLee/ART.
Read more6/18/2024