Red Teaming Game: A Game-Theoretic Framework for Red Teaming Language Models

0
Sign in to get full access
Overview
- This paper proposes a game-theoretic framework called the "Red Teaming Game" to model the interaction between a language model (the "Blue Team") and an adversary (the "Red Team") that aims to find vulnerabilities in the language model.
- The framework allows the Red Team to strategically probe the language model and the Blue Team to adapt its defense mechanisms, creating an interactive adversarial game.
- The authors also present a "Gamified Red Teaming Solver" that can be used to solve the Red Teaming Game and identify effective attack strategies against the language model.
Plain English Explanation
The paper introduces a new way to test the security and robustness of language models, such as GPT-4v, by framing it as an interactive game between two teams. The "Blue Team" represents the language model, while the "Red Team" plays the role of an adversary trying to find weaknesses or vulnerabilities in the model.
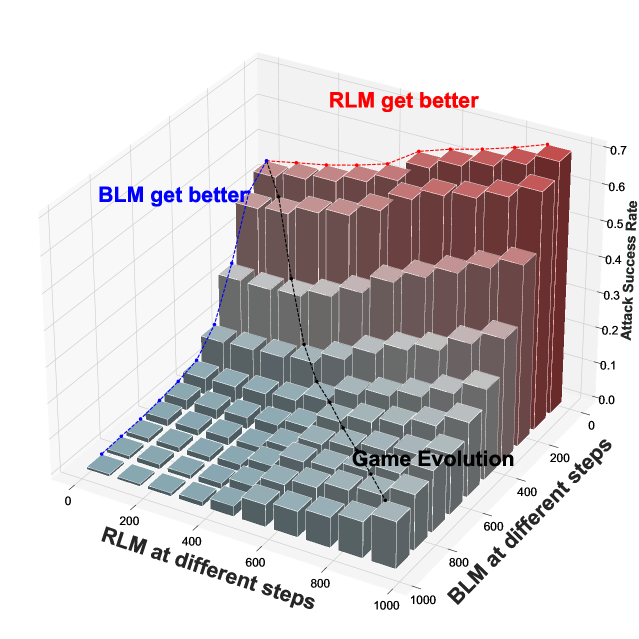
In this "Red Teaming Game," the Red Team can strategically probe the language model, trying different prompts and techniques to see how it reacts. The Blue Team, in turn, can adapt its defenses to become more robust against these attacks. This back-and-forth creates a dynamic game where both sides try to outsmart the other.
To help solve this game, the researchers developed a "Gamified Red Teaming Solver" that can analyze the game's dynamics and identify effective attack strategies for the Red Team. This tool could be useful for researchers and developers who want to thoroughly test the security of their language models before deploying them in real-world applications.
Technical Explanation
The paper presents a game-theoretic framework, called the "Red Teaming Game," to model the interaction between a language model (the "Blue Team") and an adversary (the "Red Team") that aims to find vulnerabilities in the language model. The framework consists of the following key elements:
- Blue Team (Language Model): Represents the language model being tested, which tries to provide accurate and coherent responses to the Red Team's prompts.
- Red Team (Adversary): Represents the entity trying to find vulnerabilities in the language model by strategically probing it with different prompts and techniques.
- Game Dynamics: The Red Team and Blue Team engage in an iterative game where the Red Team attempts to find weaknesses in the Blue Team's responses, and the Blue Team adapts its defenses to become more robust.
The authors also introduce a "Gamified Red Teaming Solver" that can be used to analyze the dynamics of the Red Teaming Game and identify effective attack strategies for the Red Team. This solver leverages game-theoretic concepts and techniques, such as game-theoretic deep reinforcement learning, to find optimal strategies for both the Red Team and the Blue Team.
Critical Analysis
The researchers acknowledge several limitations and areas for future research:
- The framework currently assumes a single Red Team and a single Blue Team, but in reality, there could be multiple adversaries and multiple language models involved.
- The game-theoretic model relies on certain assumptions, such as the ability to accurately model the payoff functions for both teams, which may be challenging in practice.
- The Gamified Red Teaming Solver is a proof-of-concept and may need further refinement and validation to be used in real-world scenarios.
Additionally, while the framework provides a structured approach to testing language model security, it does not address the broader ethical and societal implications of developing increasingly capable and potentially exploitable language models. Further research is needed to ensure that these models are deployed responsibly and with appropriate safeguards in place.
Conclusion
The "Red Teaming Game" framework and the associated "Gamified Red Teaming Solver" introduce a novel approach to evaluating the security and robustness of language models. By framing the interaction between a language model and an adversary as an interactive game, the researchers have laid the groundwork for a more systematic and comprehensive testing process.
This work could have significant implications for the development of secure and trustworthy language models that can be deployed in a wide range of applications, from conversational agents to game-playing agents. As the field of language models continues to evolve, frameworks like the "Red Teaming Game" will become increasingly important in ensuring the safety and reliability of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Red Teaming Game: A Game-Theoretic Framework for Red Teaming Language Models
Chengdong Ma, Ziran Yang, Hai Ci, Jun Gao, Minquan Gao, Xuehai Pan, Yaodong Yang
The primary challenge in deploying Large Language Model (LLM) is ensuring its harmlessness. Red team can identify vulnerabilities by attacking LLM to attain safety. However, current efforts heavily rely on single-round prompt designs and unilateral red team optimizations against fixed blue teams. These static approaches lead to significant reductions in generation diversity, known as the mode collapse, which makes it difficult to discover the potential risks in the increasingly complex human-LLM interactions. Here we introduce dynamic Red Team Game (RTG) to comprehensively analyze the multi-round offensive and defensive interactions between red team and blue team. Furthermore, we develop a Gamified Red Team Solver (GRTS) with diversity measures to mitigate mode collapse and theoretically guarantee the convergence of approximate Nash equilibrium which results in better strategies for both teams. Empirical results demonstrate that GRTS explore diverse and implicit attacks to adaptively exploit various LLMs, surpassing the constraints of specific modes. Insightfully, the geometrical structure we unveil of the red team task aligns with the spinning top hypothesis, confirming the necessity of constructing a diverse LLM population as a promising proxy for heterogeneous human expert red-teamers. This paves the way for scalable toxicity detection and safe alignment for LLMs.
Read more7/30/2024
📈
45
Operationalizing a Threat Model for Red-Teaming Large Language Models (LLMs)
Apurv Verma, Satyapriya Krishna, Sebastian Gehrmann, Madhavan Seshadri, Anu Pradhan, Tom Ault, Leslie Barrett, David Rabinowitz, John Doucette, NhatHai Phan
Creating secure and resilient applications with large language models (LLM) requires anticipating, adjusting to, and countering unforeseen threats. Red-teaming has emerged as a critical technique for identifying vulnerabilities in real-world LLM implementations. This paper presents a detailed threat model and provides a systematization of knowledge (SoK) of red-teaming attacks on LLMs. We develop a taxonomy of attacks based on the stages of the LLM development and deployment process and extract various insights from previous research. In addition, we compile methods for defense and practical red-teaming strategies for practitioners. By delineating prominent attack motifs and shedding light on various entry points, this paper provides a framework for improving the security and robustness of LLM-based systems.
Read more7/23/2024

0
Learning diverse attacks on large language models for robust red-teaming and safety tuning
Seanie Lee, Minsu Kim, Lynn Cherif, David Dobre, Juho Lee, Sung Ju Hwang, Kenji Kawaguchi, Gauthier Gidel, Yoshua Bengio, Nikolay Malkin, Moksh Jain
Red-teaming, or identifying prompts that elicit harmful responses, is a critical step in ensuring the safe and responsible deployment of large language models (LLMs). Developing effective protection against many modes of attack prompts requires discovering diverse attacks. Automated red-teaming typically uses reinforcement learning to fine-tune an attacker language model to generate prompts that elicit undesirable responses from a target LLM, as measured, for example, by an auxiliary toxicity classifier. We show that even with explicit regularization to favor novelty and diversity, existing approaches suffer from mode collapse or fail to generate effective attacks. As a flexible and probabilistically principled alternative, we propose to use GFlowNet fine-tuning, followed by a secondary smoothing phase, to train the attacker model to generate diverse and effective attack prompts. We find that the attacks generated by our method are effective against a wide range of target LLMs, both with and without safety tuning, and transfer well between target LLMs. Finally, we demonstrate that models safety-tuned using a dataset of red-teaming prompts generated by our method are robust to attacks from other RL-based red-teaming approaches.
Read more5/30/2024

0
Exploring Straightforward Conversational Red-Teaming
George Kour, Naama Zwerdling, Marcel Zalmanovici, Ateret Anaby-Tavor, Ora Nova Fandina, Eitan Farchi
Large language models (LLMs) are increasingly used in business dialogue systems but they pose security and ethical risks. Multi-turn conversations, where context influences the model's behavior, can be exploited to produce undesired responses. In this paper, we examine the effectiveness of utilizing off-the-shelf LLMs in straightforward red-teaming approaches, where an attacker LLM aims to elicit undesired output from a target LLM, comparing both single-turn and conversational red-teaming tactics. Our experiments offer insights into various usage strategies that significantly affect their performance as red teamers. They suggest that off-the-shelf models can act as effective red teamers and even adjust their attack strategy based on past attempts, although their effectiveness decreases with greater alignment.
Read more9/10/2024