Reexamining Racial Disparities in Automatic Speech Recognition Performance: The Role of Confounding by Provenance

0

Sign in to get full access
Overview
- Examines racial disparities in automatic speech recognition (ASR) performance
- Investigates the role of confounding by "provenance" - factors related to a speech sample's origin
- Finds that accounting for provenance reduces or eliminates previously reported racial disparities in ASR
Plain English Explanation
The paper reexamines racial differences in the accuracy of automatic speech recognition (ASR) systems. Previous studies have found that these systems tend to perform worse on speech samples from certain racial groups.
However, this new research suggests that these disparities may be explained by factors related to the "provenance" of the speech samples, such as the recording conditions, accents, or speaking styles. When the researchers accounted for these provenance-related factors, the racial differences in ASR performance were reduced or even eliminated.
In other words, the racial disparities may be more a result of the data used to train and test the ASR systems, rather than inherent biases in the systems themselves. The findings highlight the importance of carefully considering data provenance when evaluating the fairness and performance of these AI technologies.
Technical Explanation
The researchers conducted a series of experiments to assess the impact of provenance on reported racial disparities in ASR performance. They used multiple ASR models and speech datasets, including the widely-used LibriSpeech corpus.
Their analysis showed that factors like recording environment, accent, and speaking style significantly influenced ASR accuracy. When they accounted for these provenance-related factors, the previously observed racial differences in performance were reduced or eliminated.
This suggests that the racial disparities may be more a reflection of biases in the training data and evaluation procedures, rather than inherent limitations of the ASR systems. The findings emphasize the need for greater attention to data provenance when developing and testing these technologies.
Critical Analysis
The paper provides a thoughtful and rigorous examination of an important issue in the field of ASR. By considering the role of confounding factors related to data provenance, the researchers offer a more nuanced understanding of the observed racial disparities.
However, the study is limited to a select set of ASR models and datasets. It would be valuable to extend the analysis to a wider range of systems and data sources to further validate the findings. Additionally, the paper does not delve into the specific mechanisms by which provenance factors influence ASR performance.
Future research could explore these underlying relationships in greater depth, as well as investigate other potential sources of bias in ASR systems. Continued scrutiny and mitigation of such biases will be crucial for ensuring the fairness and equitable deployment of these increasingly ubiquitous technologies.
Conclusion
This paper challenges the prevailing narrative around racial disparities in automatic speech recognition. By accounting for factors related to the origin or provenance of speech samples, the researchers demonstrate that these disparities may be more a function of biases in the data than inherent limitations of the ASR systems.
The findings highlight the importance of carefully considering data provenance when developing and evaluating these AI technologies. As ASR systems become more widely adopted, it will be critical to address such sources of bias to ensure fair and equitable performance across diverse populations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reexamining Racial Disparities in Automatic Speech Recognition Performance: The Role of Confounding by Provenance
Changye Li, Trevor Cohen, Serguei Pakhomov
Automatic speech recognition (ASR) models trained on large amounts of audio data are now widely used to convert speech to written text in a variety of applications from video captioning to automated assistants used in healthcare and other domains. As such, it is important that ASR models and their use is fair and equitable. Prior work examining the performance of commercial ASR systems on the Corpus of Regional African American Language (CORAAL) demonstrated significantly worse ASR performance on African American English (AAE). The current study seeks to understand the factors underlying this disparity by examining the performance of the current state-of-the-art neural network based ASR system (Whisper, OpenAI) on the CORAAL dataset. Two key findings have been identified as a result of the current study. The first confirms prior findings of significant dialectal variation even across neighboring communities, and worse ASR performance on AAE that can be improved to some extent with fine-tuning of ASR models. The second is a novel finding not discussed in prior work on CORAAL: differences in audio recording practices within the dataset have a significant impact on ASR accuracy resulting in a ``confounding by provenance'' effect in which both language use and recording quality differ by study location. These findings highlight the need for further systematic investigation to disentangle the effects of recording quality and inherent linguistic diversity when examining the fairness and bias present in neural ASR models, as any bias in ASR accuracy may have negative downstream effects on disparities in various domains of life in which ASR technology is used.
Read more7/22/2024
🗣️
0
Self-supervised Speech Representations Still Struggle with African American Vernacular English
Kalvin Chang, Yi-Hui Chou, Jiatong Shi, Hsuan-Ming Chen, Nicole Holliday, Odette Scharenborg, David R. Mortensen
Underperformance of ASR systems for speakers of African American Vernacular English (AAVE) and other marginalized language varieties is a well-documented phenomenon, and one that reinforces the stigmatization of these varieties. We investigate whether or not the recent wave of Self-Supervised Learning (SSL) speech models can close the gap in ASR performance between AAVE and Mainstream American English (MAE). We evaluate four SSL models (wav2vec 2.0, HuBERT, WavLM, and XLS-R) on zero-shot Automatic Speech Recognition (ASR) for these two varieties and find that these models perpetuate the bias in performance against AAVE. Additionally, the models have higher word error rates on utterances with more phonological and morphosyntactic features of AAVE. Despite the success of SSL speech models in improving ASR for low resource varieties, SSL pre-training alone may not bridge the gap between AAVE and MAE. Our code is publicly available at https://github.com/cmu-llab/s3m-aave.
Read more8/27/2024
🤯
0
You don't understand me!: Comparing ASR results for L1 and L2 speakers of Swedish
Ronald Cumbal, Birger Moell, Jose Lopes, Olof Engwall
The performance of Automatic Speech Recognition (ASR) systems has constantly increased in state-of-the-art development. However, performance tends to decrease considerably in more challenging conditions (e.g., background noise, multiple speaker social conversations) and with more atypical speakers (e.g., children, non-native speakers or people with speech disorders), which signifies that general improvements do not necessarily transfer to applications that rely on ASR, e.g., educational software for younger students or language learners. In this study, we focus on the gap in performance between recognition results for native and non-native, read and spontaneous, Swedish utterances transcribed by different ASR services. We compare the recognition results using Word Error Rate and analyze the linguistic factors that may generate the observed transcription errors.
Read more5/24/2024
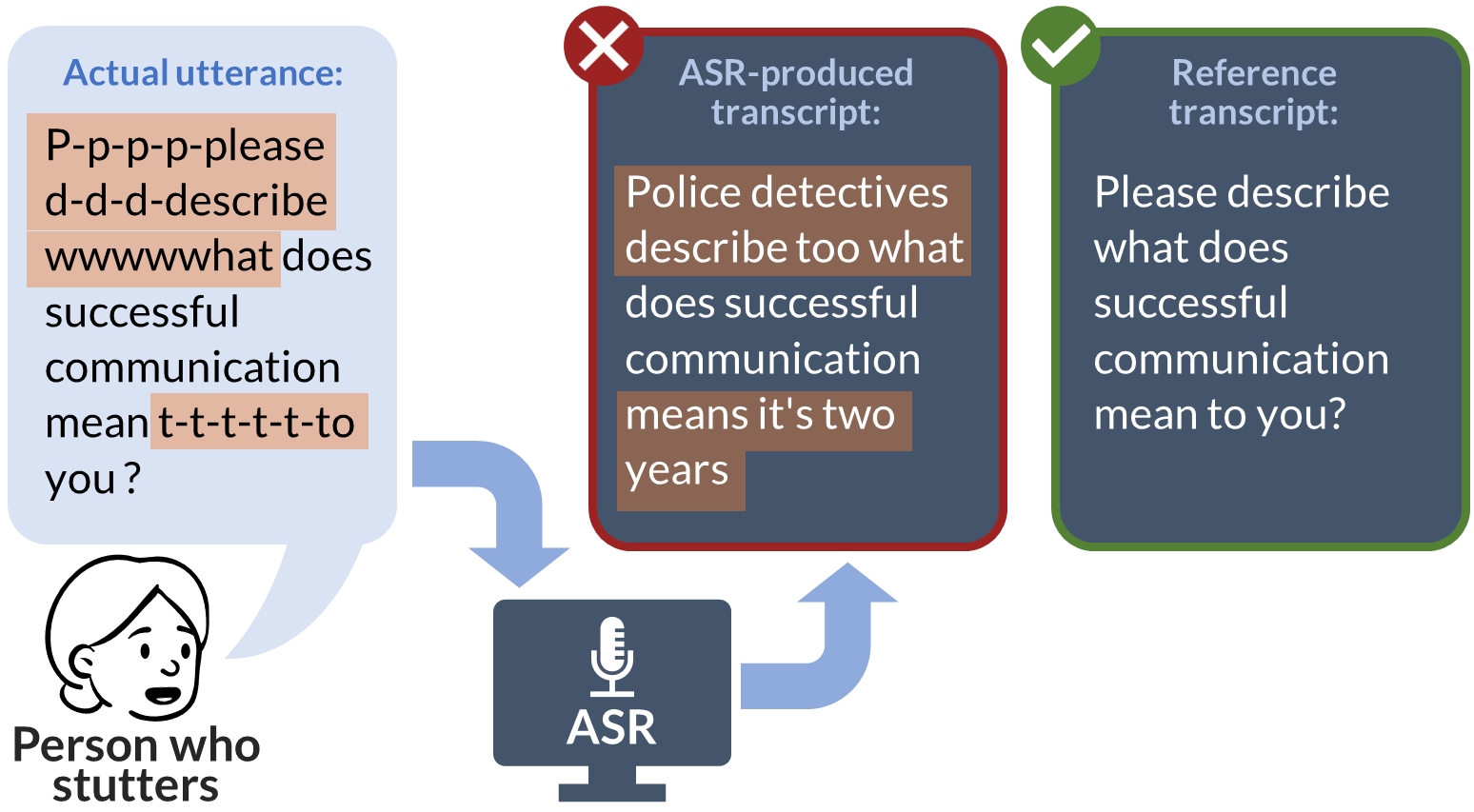
0
Lost in Transcription: Identifying and Quantifying the Accuracy Biases of Automatic Speech Recognition Systems Against Disfluent Speech
Dena Mujtaba, Nihar R. Mahapatra, Megan Arney, J. Scott Yaruss, Hope Gerlach-Houck, Caryn Herring, Jia Bin
Automatic speech recognition (ASR) systems, increasingly prevalent in education, healthcare, employment, and mobile technology, face significant challenges in inclusivity, particularly for the 80 million-strong global community of people who stutter. These systems often fail to accurately interpret speech patterns deviating from typical fluency, leading to critical usability issues and misinterpretations. This study evaluates six leading ASRs, analyzing their performance on both a real-world dataset of speech samples from individuals who stutter and a synthetic dataset derived from the widely-used LibriSpeech benchmark. The synthetic dataset, uniquely designed to incorporate various stuttering events, enables an in-depth analysis of each ASR's handling of disfluent speech. Our comprehensive assessment includes metrics such as word error rate (WER), character error rate (CER), and semantic accuracy of the transcripts. The results reveal a consistent and statistically significant accuracy bias across all ASRs against disfluent speech, manifesting in significant syntactical and semantic inaccuracies in transcriptions. These findings highlight a critical gap in current ASR technologies, underscoring the need for effective bias mitigation strategies. Addressing this bias is imperative not only to improve the technology's usability for people who stutter but also to ensure their equitable and inclusive participation in the rapidly evolving digital landscape.
Read more5/13/2024