A Reference-Based 3D Semantic-Aware Framework for Accurate Local Facial Attribute Editing

0
🔎
Sign in to get full access
Overview
- This paper describes a new method for efficient 3D-aware facial image editing.
- The key innovation is a self-supervised training framework that disentangles the 3D facial structure from other attributes like expression, lighting, and texture.
- This allows for fine-grained control over the 3D shape of the face during editing, while preserving other important facial features.
Plain English Explanation
The paper presents a new way to edit facial images in 3D. Most existing methods for facial editing either don't account for the 3D structure of the face or require complex 3D modeling that is difficult to control. This new approach uses a technique called self-supervised learning to automatically discover the 3D shape of the face, as well as other important attributes like expression and lighting.
This separation of 3D structure from other facial features allows the system to edit the 3D shape of the face in a very fine-grained and intuitive way, while still preserving the person's identity, expression, and other details. For example, you could use this to change the 3D shape of someone's nose or jaw without affecting their eyes, mouth, or other parts of their face.
The key advantage is that this 3D editing can be done in a very efficient way, without the need for complex 3D modeling or reconstruction. This makes the technique practical for real-world applications like photo editing, computer graphics, and virtual try-on systems.
Technical Explanation
The paper introduces a self-supervised training framework that learns to disentangle the 3D facial structure from other attributes like expression, lighting, and texture. This is accomplished through a combination of self-supervised losses that encourage the model to discover these distinct factors of variation in the data.
The core architecture consists of an encoder-decoder network that takes a 2D facial image as input and outputs a set of latent codes representing the 3D shape, expression, lighting, and texture of the face. These latent codes can then be manipulated independently to edit the facial image in a 3D-aware manner.
The authors show that this approach outperforms prior methods on a range of facial editing tasks, including attribute transfer, expression editing, and 3D shape manipulation. Importantly, the 3D editing can be done in an efficient, real-time manner, making it suitable for practical applications.
Critical Analysis
The paper provides a compelling approach for 3D-aware facial image editing, with clear advantages over prior work in terms of efficiency and level of control. However, a few potential limitations and areas for further research are worth noting:
- The method assumes a relatively constrained facial domain, and it's unclear how well it would generalize to more diverse or extreme facial geometries and expressions.
- The self-supervised training process requires a large and diverse dataset of facial images, which may not be readily available in all settings.
- While the 3D editing capabilities are impressive, the paper does not address potential ethical concerns around the misuse of such technology for deceptive or nefarious purposes, such as generating fake or manipulated images.
Further research could explore ways to address these limitations, as well as investigate the broader societal implications of this type of facial editing technology.
Conclusion
Overall, this paper presents an innovative solution for efficient 3D-aware facial image editing, with promising results and practical applications. The key advance is the use of self-supervised learning to disentangle the 3D facial structure from other important attributes, enabling fine-grained control over the 3D shape while preserving other facial features. While there are some potential limitations, this work represents an important step forward in the field of facial editing and manipulation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
A Reference-Based 3D Semantic-Aware Framework for Accurate Local Facial Attribute Editing
Yu-Kai Huang, Yutong Zheng, Yen-Shuo Su, Anudeepsekhar Bolimera, Han Zhang, Fangyi Chen, Marios Savvides
Facial attribute editing plays a crucial role in synthesizing realistic faces with specific characteristics while maintaining realistic appearances. Despite advancements, challenges persist in achieving precise, 3D-aware attribute modifications, which are crucial for consistent and accurate representations of faces from different angles. Current methods struggle with semantic entanglement and lack effective guidance for incorporating attributes while maintaining image integrity. To address these issues, we introduce a novel framework that merges the strengths of latent-based and reference-based editing methods. Our approach employs a 3D GAN inversion technique to embed attributes from the reference image into a tri-plane space, ensuring 3D consistency and realistic viewing from multiple perspectives. We utilize blending techniques and predicted semantic masks to locate precise edit regions, merging them with the contextual guidance from the reference image. A coarse-to-fine inpainting strategy is then applied to preserve the integrity of untargeted areas, significantly enhancing realism. Our evaluations demonstrate superior performance across diverse editing tasks, validating our framework's effectiveness in realistic and applicable facial attribute editing.
Read more7/30/2024
0
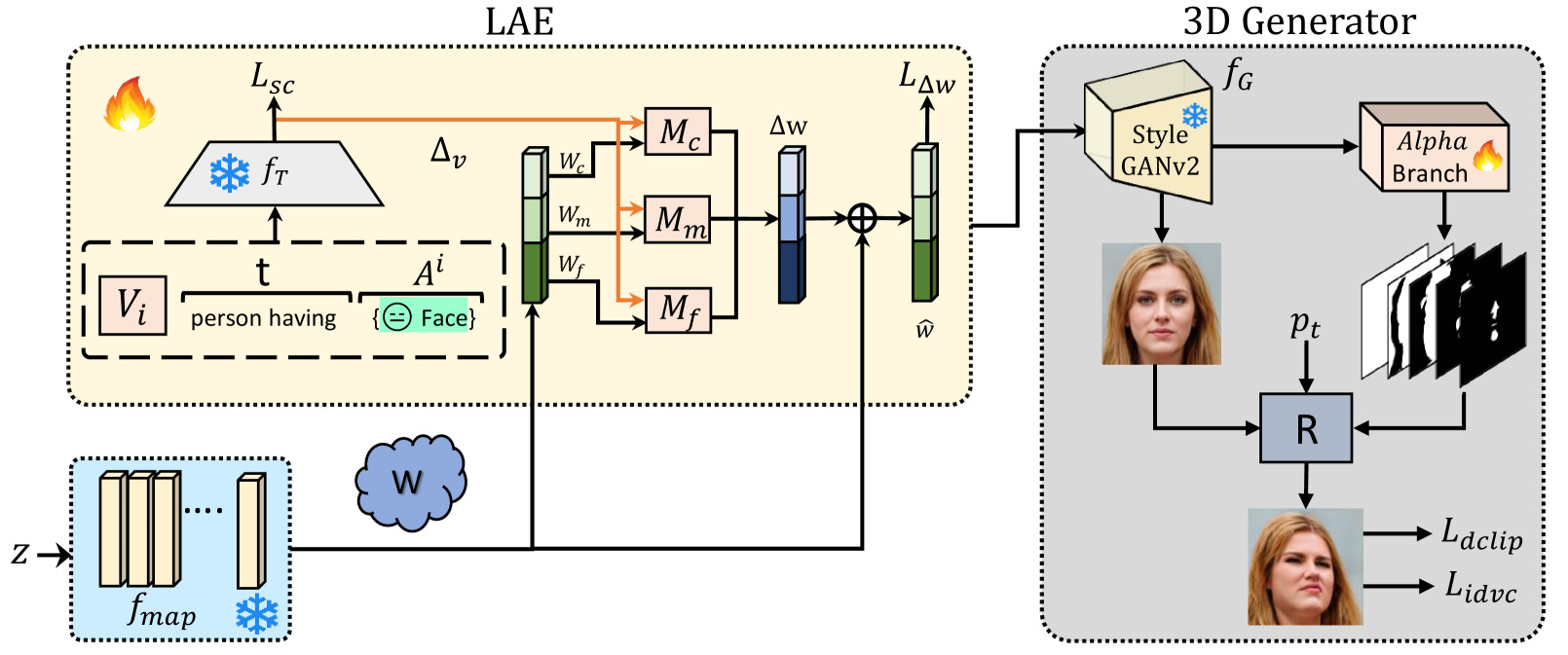
Efficient 3D-Aware Facial Image Editing via Attribute-Specific Prompt Learning
Amandeep Kumar, Muhammad Awais, Sanath Narayan, Hisham Cholakkal, Salman Khan, Rao Muhammad Anwer
Drawing upon StyleGAN's expressivity and disentangled latent space, existing 2D approaches employ textual prompting to edit facial images with different attributes. In contrast, 3D-aware approaches that generate faces at different target poses require attribute-specific classifiers, learning separate model weights for each attribute, and are not scalable for novel attributes. In this work, we propose an efficient, plug-and-play, 3D-aware face editing framework based on attribute-specific prompt learning, enabling the generation of facial images with controllable attributes across various target poses. To this end, we introduce a text-driven learnable style token-based latent attribute editor (LAE). The LAE harnesses a pre-trained vision-language model to find text-guided attribute-specific editing direction in the latent space of any pre-trained 3D-aware GAN. It utilizes learnable style tokens and style mappers to learn and transform this editing direction to 3D latent space. To train LAE with multiple attributes, we use directional contrastive loss and style token loss. Furthermore, to ensure view consistency and identity preservation across different poses and attributes, we employ several 3D-aware identity and pose preservation losses. Our experiments show that our proposed framework generates high-quality images with 3D awareness and view consistency while maintaining attribute-specific features. We demonstrate the effectiveness of our method on different facial attributes, including hair color and style, expression, and others.
Read more7/25/2024

0
Mitigating the Impact of Attribute Editing on Face Recognition
Sudipta Banerjee, Sai Pranaswi Mullangi, Shruti Wagle, Chinmay Hegde, Nasir Memon
Through a large-scale study over diverse face images, we show that facial attribute editing using modern generative AI models can severely degrade automated face recognition systems. This degradation persists even with identity-preserving generative models. To mitigate this issue, we propose two novel techniques for local and global attribute editing. We empirically ablate twenty-six facial semantic, demographic and expression-based attributes that have been edited using state-of-the-art generative models, and evaluate them using ArcFace and AdaFace matchers on CelebA, CelebAMaskHQ and LFW datasets. Finally, we use LLaVA, an emerging visual question-answering framework for attribute prediction to validate our editing techniques. Our methods outperform the current state-of-the-art at facial editing (BLIP, InstantID) while improving identity retention by a significant extent.
Read more4/11/2024

0
S3Editor: A Sparse Semantic-Disentangled Self-Training Framework for Face Video Editing
Guangzhi Wang, Tianyi Chen, Kamran Ghasedi, HsiangTao Wu, Tianyu Ding, Chris Nuesmeyer, Ilya Zharkov, Mohan Kankanhalli, Luming Liang
Face attribute editing plays a pivotal role in various applications. However, existing methods encounter challenges in achieving high-quality results while preserving identity, editing faithfulness, and temporal consistency. These challenges are rooted in issues related to the training pipeline, including limited supervision, architecture design, and optimization strategy. In this work, we introduce S3Editor, a Sparse Semantic-disentangled Self-training framework for face video editing. S3Editor is a generic solution that comprehensively addresses these challenges with three key contributions. Firstly, S3Editor adopts a self-training paradigm to enhance the training process through semi-supervision. Secondly, we propose a semantic disentangled architecture with a dynamic routing mechanism that accommodates diverse editing requirements. Thirdly, we present a structured sparse optimization schema that identifies and deactivates malicious neurons to further disentangle impacts from untarget attributes. S3Editor is model-agnostic and compatible with various editing approaches. Our extensive qualitative and quantitative results affirm that our approach significantly enhances identity preservation, editing fidelity, as well as temporal consistency.
Read more4/15/2024