S3Editor: A Sparse Semantic-Disentangled Self-Training Framework for Face Video Editing

0

Sign in to get full access
Overview
- Proposes a novel framework called S3Editor for editing face videos using sparse semantic-disentangled self-training
- Aims to enable fine-grained, user-controllable face editing in real-time by disentangling the semantic attributes of a face
- Leverages self-supervised learning to learn a compact semantic representation without requiring expensive labeled data
Plain English Explanation
The S3Editor framework is designed to make it easier to edit and manipulate face videos in a precise and user-friendly way. Rather than relying on complex and rigid editing tools, S3Editor tries to understand the semantic attributes of a face - things like expression, age, gender, etc. - and allow the user to selectively modify these attributes.
By using self-supervised learning, the system can learn these semantic representations without needing large amounts of labeled training data, which is often difficult and expensive to obtain. This makes the system more accessible and practical for real-world use cases.
The key idea is to disentangle the different semantic components of a face, so the user can independently adjust things like <a href="https://aimodels.fyi/papers/arxiv/simple-semantic-aided-few-shot-learning">the smile, age, or gender</a> without affecting other aspects. This sparse, semantically-meaningful control allows for fine-grained face editing that was difficult with previous methods.
Overall, S3Editor aims to bring powerful face editing capabilities to users in an intuitive and efficient way, by leveraging recent advances in self-supervised learning and disentanglement.
Technical Explanation
The S3Editor framework consists of several key components:
-
Semantic Encoder: A neural network that learns to extract a compact, disentangled representation of the semantic attributes of a face, such as expression, age, and gender. This is done through self-supervised learning on unlabeled face videos.
-
Editing Network: A neural network that takes the semantic representation and allows the user to selectively modify the attributes, while preserving the overall face identity. This enables <a href="https://aimodels.fyi/papers/arxiv/videdit-zero-shot-spatially-aware-text-driven">fine-grained, user-controlled face editing</a>.
-
Generator: A neural network that takes the edited semantic representation and generates the corresponding edited face image or video frame.
The authors show that this framework can achieve state-of-the-art performance on face editing tasks, while requiring much less labeled training data compared to previous approaches. The self-supervised semantic representation learning is a key innovation that allows the system to work well even with limited supervision.
Critical Analysis
The paper makes a compelling case for the S3Editor framework and demonstrates its effectiveness through extensive experiments. However, a few potential limitations and areas for future research are worth considering:
- The system is currently focused on editing still images, and extending it to handle full face videos in a temporally consistent manner may require additional challenges to be addressed.
- While the self-supervised learning approach reduces the need for labeled data, the system still requires a significant amount of unlabeled face video data for training. Exploring ways to further reduce this data requirement could broaden the applicability of the approach.
- The paper does not delve deeply into potential ethical concerns around <a href="https://aimodels.fyi/papers/arxiv/mitigating-impact-attribute-editing-face-recognition">the misuse of face editing technologies</a> and how to mitigate them. This is an important consideration for real-world deployments.
Overall, the S3Editor framework represents a promising step forward in making face editing more accessible and user-friendly, with interesting avenues for future research and development.
Conclusion
The S3Editor framework proposed in this paper introduces a novel approach to face video editing that leverages self-supervised learning to disentangle the semantic attributes of a face. By enabling fine-grained, user-controlled editing without the need for extensive labeled training data, S3Editor has the potential to make powerful face editing capabilities more accessible to a wider range of users.
The core innovation lies in the self-supervised learning of a compact, semantically-meaningful representation of faces, which then allows the user to selectively modify attributes like expression, age, and gender. This sparse, disentangled control opens up new possibilities for <a href="https://aimodels.fyi/papers/arxiv/agent-driven-generative-semantic-communication-remote-surveillance">creative and practical applications of face editing</a>, with implications for fields ranging from entertainment to assistive technology.
While the paper demonstrates promising results, there are still opportunities for further research to address limitations and explore extensions, such as handling full face videos and considering potential ethical implications. Overall, the S3Editor framework represents an exciting step forward in making face editing more intuitive, user-friendly, and accessible to a broader audience.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
S3Editor: A Sparse Semantic-Disentangled Self-Training Framework for Face Video Editing
Guangzhi Wang, Tianyi Chen, Kamran Ghasedi, HsiangTao Wu, Tianyu Ding, Chris Nuesmeyer, Ilya Zharkov, Mohan Kankanhalli, Luming Liang
Face attribute editing plays a pivotal role in various applications. However, existing methods encounter challenges in achieving high-quality results while preserving identity, editing faithfulness, and temporal consistency. These challenges are rooted in issues related to the training pipeline, including limited supervision, architecture design, and optimization strategy. In this work, we introduce S3Editor, a Sparse Semantic-disentangled Self-training framework for face video editing. S3Editor is a generic solution that comprehensively addresses these challenges with three key contributions. Firstly, S3Editor adopts a self-training paradigm to enhance the training process through semi-supervision. Secondly, we propose a semantic disentangled architecture with a dynamic routing mechanism that accommodates diverse editing requirements. Thirdly, we present a structured sparse optimization schema that identifies and deactivates malicious neurons to further disentangle impacts from untarget attributes. S3Editor is model-agnostic and compatible with various editing approaches. Our extensive qualitative and quantitative results affirm that our approach significantly enhances identity preservation, editing fidelity, as well as temporal consistency.
Read more4/15/2024
🔎
0
A Reference-Based 3D Semantic-Aware Framework for Accurate Local Facial Attribute Editing
Yu-Kai Huang, Yutong Zheng, Yen-Shuo Su, Anudeepsekhar Bolimera, Han Zhang, Fangyi Chen, Marios Savvides
Facial attribute editing plays a crucial role in synthesizing realistic faces with specific characteristics while maintaining realistic appearances. Despite advancements, challenges persist in achieving precise, 3D-aware attribute modifications, which are crucial for consistent and accurate representations of faces from different angles. Current methods struggle with semantic entanglement and lack effective guidance for incorporating attributes while maintaining image integrity. To address these issues, we introduce a novel framework that merges the strengths of latent-based and reference-based editing methods. Our approach employs a 3D GAN inversion technique to embed attributes from the reference image into a tri-plane space, ensuring 3D consistency and realistic viewing from multiple perspectives. We utilize blending techniques and predicted semantic masks to locate precise edit regions, merging them with the contextual guidance from the reference image. A coarse-to-fine inpainting strategy is then applied to preserve the integrity of untargeted areas, significantly enhancing realism. Our evaluations demonstrate superior performance across diverse editing tasks, validating our framework's effectiveness in realistic and applicable facial attribute editing.
Read more7/30/2024

0
Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection
Gihyun Kwon, Jangho Park, Jong Chul Ye
While text-to-image models have achieved impressive capabilities in image generation and editing, their application across various modalities often necessitates training separate models. Inspired by existing method of single image editing with self attention injection and video editing with shared attention, we propose a novel unified editing framework that combines the strengths of both approaches by utilizing only a basic 2D image text-to-image (T2I) diffusion model. Specifically, we design a sampling method that facilitates editing consecutive images while maintaining semantic consistency utilizing shared self-attention features during both reference and consecutive image sampling processes. Experimental results confirm that our method enables editing across diverse modalities including 3D scenes, videos, and panorama images.
Read more5/28/2024
0
Efficient 3D-Aware Facial Image Editing via Attribute-Specific Prompt Learning
Amandeep Kumar, Muhammad Awais, Sanath Narayan, Hisham Cholakkal, Salman Khan, Rao Muhammad Anwer
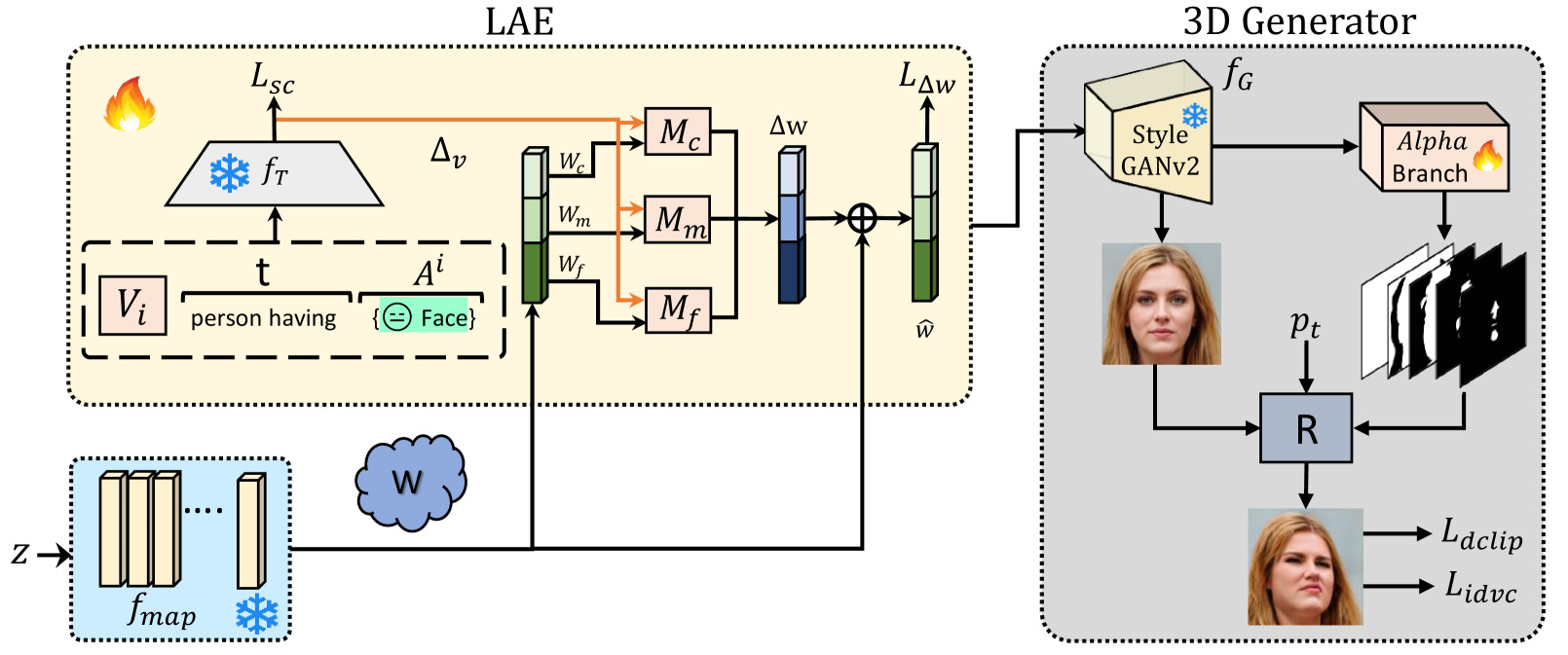
Drawing upon StyleGAN's expressivity and disentangled latent space, existing 2D approaches employ textual prompting to edit facial images with different attributes. In contrast, 3D-aware approaches that generate faces at different target poses require attribute-specific classifiers, learning separate model weights for each attribute, and are not scalable for novel attributes. In this work, we propose an efficient, plug-and-play, 3D-aware face editing framework based on attribute-specific prompt learning, enabling the generation of facial images with controllable attributes across various target poses. To this end, we introduce a text-driven learnable style token-based latent attribute editor (LAE). The LAE harnesses a pre-trained vision-language model to find text-guided attribute-specific editing direction in the latent space of any pre-trained 3D-aware GAN. It utilizes learnable style tokens and style mappers to learn and transform this editing direction to 3D latent space. To train LAE with multiple attributes, we use directional contrastive loss and style token loss. Furthermore, to ensure view consistency and identity preservation across different poses and attributes, we employ several 3D-aware identity and pose preservation losses. Our experiments show that our proposed framework generates high-quality images with 3D awareness and view consistency while maintaining attribute-specific features. We demonstrate the effectiveness of our method on different facial attributes, including hair color and style, expression, and others.
Read more7/25/2024