RefMask3D: Language-Guided Transformer for 3D Referring Segmentation

0
Sign in to get full access
Overview
- The paper presents a language-guided transformer model for 3D referring segmentation.
- The model, called RefMask3D, takes a 3D point cloud and a natural language query as input, and outputs a segmentation mask that identifies the object referred to in the query.
- RefMask3D leverages vision-language learning to effectively understand and ground the language description to the 3D object.
Plain English Explanation
The paper introduces a new model, called RefMask3D, that can understand natural language descriptions and use that understanding to identify specific 3D objects in a larger 3D scene. For example, if you give the model a 3D point cloud of a room and say "the blue chair in the corner", the model will be able to find and outline the correct chair.
This is an important capability because it allows users to interact with 3D environments in a more natural and intuitive way, simply by describing what they're looking for. This could be useful in a variety of applications, such as interior design, robotic assistance, or 3D scene understanding.
The key innovation of RefMask3D is that it uses a transformer-based architecture to effectively combine the visual information from the 3D point cloud with the language description. This allows the model to understand the semantic relationship between the words and the 3D geometry, and use that understanding to accurately identify the correct object.
Technical Explanation
The RefMask3D model is built on a transformer-based architecture that takes a 3D point cloud and a natural language query as input, and outputs a segmentation mask that identifies the object referred to in the query.
The model consists of several key components:
- 3D Encoder: This module encodes the input 3D point cloud into a set of visual features.
- Language Encoder: This module encodes the natural language query into a set of language features.
- Cross-modal Transformer: This module combines the visual and language features, allowing the model to learn the semantic relationship between the language description and the 3D geometry.
- Segmentation Head: This module takes the combined features and outputs a segmentation mask for the referred object.
The key innovation of RefMask3D is the cross-modal transformer, which effectively fuses the visual and language information to enable accurate 3D referring segmentation. This allows the model to ground the language description to the correct 3D object, even in complex scenes with multiple objects.
The paper evaluates RefMask3D on several 3D referring segmentation datasets and shows that it outperforms previous state-of-the-art methods, demonstrating the effectiveness of the language-guided transformer approach.
Critical Analysis
The paper provides a comprehensive evaluation of RefMask3D, demonstrating its strong performance on various 3D referring segmentation benchmarks. However, the authors acknowledge several limitations and areas for further research:
- Scalability: The model's performance may degrade as the complexity of the 3D scenes and language queries increases. Exploring ways to improve the model's scalability would be an important next step.
- Generalization: The paper focuses on evaluating RefMask3D on existing datasets, which may not fully capture the diversity of real-world 3D environments and language descriptions. Investigating the model's ability to generalize to new, unseen scenarios would be valuable.
- Interpretability: The transformer-based architecture of RefMask3D can be challenging to interpret, making it difficult to understand the model's reasoning process. Developing more interpretable approaches could enhance the model's transparency and trustworthiness.
Despite these limitations, the paper makes a significant contribution to the field of 3D vision-language understanding, and the RefMask3D model represents an important step towards more natural and intuitive interaction with 3D environments.
Conclusion
The RefMask3D paper presents a novel language-guided transformer model for 3D referring segmentation, which allows users to interact with 3D scenes by describing the objects they're interested in. The model's ability to effectively fuse visual and language information enables accurate identification of referred objects, even in complex 3D environments.
While the paper highlights some areas for further research, the RefMask3D model represents an important advancement in the field of 3D vision-language understanding, with potential applications in a wide range of domains, from interior design to robotic assistance. As the research in this area continues to evolve, we can expect to see even more intuitive and natural ways for humans to interact with and understand 3D digital worlds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RefMask3D: Language-Guided Transformer for 3D Referring Segmentation
Shuting He, Henghui Ding
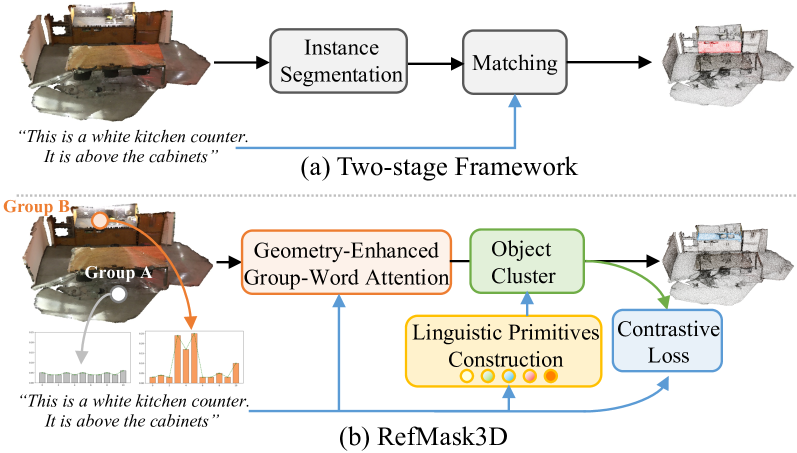
3D referring segmentation is an emerging and challenging vision-language task that aims to segment the object described by a natural language expression in a point cloud scene. The key challenge behind this task is vision-language feature fusion and alignment. In this work, we propose RefMask3D to explore the comprehensive multi-modal feature interaction and understanding. First, we propose a Geometry-Enhanced Group-Word Attention to integrate language with geometrically coherent sub-clouds through cross-modal group-word attention, which effectively addresses the challenges posed by the sparse and irregular nature of point clouds. Then, we introduce a Linguistic Primitives Construction to produce semantic primitives representing distinct semantic attributes, which greatly enhance the vision-language understanding at the decoding stage. Furthermore, we introduce an Object Cluster Module that analyzes the interrelationships among linguistic primitives to consolidate their insights and pinpoint common characteristics, helping to capture holistic information and enhance the precision of target identification. The proposed RefMask3D achieves new state-of-the-art performance on 3D referring segmentation, 3D visual grounding, and also 2D referring image segmentation. Especially, RefMask3D outperforms previous state-of-the-art method by a large margin of 3.16% mIoU} on the challenging ScanRefer dataset. Code is available at https://github.com/heshuting555/RefMask3D.
Read more7/26/2024

0
Reason3D: Searching and Reasoning 3D Segmentation via Large Language Model
Kuan-Chih Huang, Xiangtai Li, Lu Qi, Shuicheng Yan, Ming-Hsuan Yang
Recent advancements in multimodal large language models (LLMs) have shown their potential in various domains, especially concept reasoning. Despite these developments, applications in understanding 3D environments remain limited. This paper introduces Reason3D, a novel LLM designed for comprehensive 3D understanding. Reason3D takes point cloud data and text prompts as input to produce textual responses and segmentation masks, facilitating advanced tasks like 3D reasoning segmentation, hierarchical searching, express referring, and question answering with detailed mask outputs. Specifically, we propose a hierarchical mask decoder to locate small objects within expansive scenes. This decoder initially generates a coarse location estimate covering the object's general area. This foundational estimation facilitates a detailed, coarse-to-fine segmentation strategy that significantly enhances the precision of object identification and segmentation. Experiments validate that Reason3D achieves remarkable results on large-scale ScanNet and Matterport3D datasets for 3D express referring, 3D question answering, and 3D reasoning segmentation tasks. Code and models are available at: https://github.com/KuanchihHuang/Reason3D.
Read more5/28/2024

0
Transcrib3D: 3D Referring Expression Resolution through Large Language Models
Jiading Fang, Xiangshan Tan, Shengjie Lin, Igor Vasiljevic, Vitor Guizilini, Hongyuan Mei, Rares Ambrus, Gregory Shakhnarovich, Matthew R Walter
If robots are to work effectively alongside people, they must be able to interpret natural language references to objects in their 3D environment. Understanding 3D referring expressions is challenging -- it requires the ability to both parse the 3D structure of the scene and correctly ground free-form language in the presence of distraction and clutter. We introduce Transcrib3D, an approach that brings together 3D detection methods and the emergent reasoning capabilities of large language models (LLMs). Transcrib3D uses text as the unifying medium, which allows us to sidestep the need to learn shared representations connecting multi-modal inputs, which would require massive amounts of annotated 3D data. As a demonstration of its effectiveness, Transcrib3D achieves state-of-the-art results on 3D reference resolution benchmarks, with a great leap in performance from previous multi-modality baselines. To improve upon zero-shot performance and facilitate local deployment on edge computers and robots, we propose self-correction for fine-tuning that trains smaller models, resulting in performance close to that of large models. We show that our method enables a real robot to perform pick-and-place tasks given queries that contain challenging referring expressions. Project site is at https://ripl.github.io/Transcrib3D.
Read more5/1/2024

0
SegPoint: Segment Any Point Cloud via Large Language Model
Shuting He, Henghui Ding, Xudong Jiang, Bihan Wen
Despite significant progress in 3D point cloud segmentation, existing methods primarily address specific tasks and depend on explicit instructions to identify targets, lacking the capability to infer and understand implicit user intentions in a unified framework. In this work, we propose a model, called SegPoint, that leverages the reasoning capabilities of a multi-modal Large Language Model (LLM) to produce point-wise segmentation masks across a diverse range of tasks: 1) 3D instruction segmentation, 2) 3D referring segmentation, 3) 3D semantic segmentation, and 4) 3D open-vocabulary semantic segmentation. To advance 3D instruction research, we introduce a new benchmark, Instruct3D, designed to evaluate segmentation performance from complex and implicit instructional texts, featuring 2,565 point cloud-instruction pairs. Our experimental results demonstrate that SegPoint achieves competitive performance on established benchmarks such as ScanRefer for referring segmentation and ScanNet for semantic segmentation, while delivering outstanding outcomes on the Instruct3D dataset. To our knowledge, SegPoint is the first model to address these varied segmentation tasks within a single framework, achieving satisfactory performance.
Read more7/19/2024