RegionPLC: Regional Point-Language Contrastive Learning for Open-World 3D Scene Understanding

0
🤔
Sign in to get full access
Overview
- Proposes a lightweight and scalable 3D scene understanding framework called RegionPLC
- Aims to identify and recognize open-set objects and categories in 3D scenes
- Introduces a 3D-aware SFusion strategy to derive high-quality, dense region-level language descriptions without human 3D annotations
- Devises a region-aware point-discriminative contrastive learning objective for robust and effective 3D learning
Plain English Explanation
The paper presents a new approach called RegionPLC for understanding 3D scenes. The goal is to be able to identify and recognize a wide range of objects and categories in 3D environments, even ones that the system hasn't been explicitly trained on before.
The key idea is to leverage the power of large language models trained on massive amounts of text data to generate detailed descriptions of 3D regions within a scene. This is done through a novel 3D-aware SFusion strategy that combines information from multiple 2D foundation models.
The system then uses a region-aware point-discriminative contrastive learning objective to learn robust 3D representations from these dense language descriptions, without needing any human-annotated 3D data.
The authors show that this approach outperforms prior 3D scene understanding methods, while being more scalable and requiring fewer computational resources. It also has the flexibility to be integrated with language models for open-ended 3D reasoning without additional training.
Technical Explanation
The proposed RegionPLC framework consists of two key components:
-
3D-aware SFusion: This module takes input from multiple 2D foundation models and fuses the resulting 3D vision-language pairs to generate high-quality, dense region-level language descriptions without the need for human-annotated 3D data.
-
Region-aware Point-discriminative Contrastive Learning: RegionPLC uses a specialized contrastive learning objective that focuses on discriminating between different regions within the 3D scene, rather than just individual points. This allows for more robust and effective 3D learning from the dense regional language supervision.
The authors evaluate their approach on several 3D scene understanding benchmarks, including ScanNet, ScanNet200, and nuScenes. Their model outperforms previous state-of-the-art methods by an average of 17.2% and 9.1% for semantic and instance segmentation, respectively, while being more scalable and requiring fewer computational resources.
Additionally, the flexibility of the RegionPLC framework allows it to be easily integrated with large language models, enabling open-ended 3D reasoning without the need for additional task-specific training.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the RegionPLC framework, highlighting its significant performance improvements over prior 3D scene understanding approaches. However, the authors do acknowledge a few potential limitations and areas for future research:
-
Dependence on 2D Foundation Models: The quality of the 3D vision-language pairs generated by the SFusion module is inherently dependent on the performance of the underlying 2D foundation models. Any limitations or biases in these models could be reflected in the final RegionPLC outputs.
-
Generalization to Unseen Environments: While the authors demonstrate the effectiveness of RegionPLC on several 3D scene benchmarks, it remains to be seen how well the framework would generalize to entirely new and diverse 3D environments beyond the training data.
-
Computational Complexity: Although the authors claim that RegionPLC is more scalable and efficient than previous methods, the practical implications of the framework's computational requirements in real-world deployments could be further investigated.
-
Interpretability and Explainability: The paper does not provide much insight into the inner workings of the region-aware contrastive learning objective and how the model arrives at its final 3D scene understanding outputs. Improving the interpretability and explainability of the system could be a valuable avenue for future research.
Overall, the RegionPLC framework represents a significant advance in the field of 3D scene understanding, leveraging the power of language models and contrastive learning to achieve state-of-the-art performance. However, as with any research, there are opportunities to further refine and expand upon the proposed approach.
Conclusion
The RegionPLC framework introduced in this paper offers a promising solution for open-world 3D scene understanding, addressing the challenges of identifying and recognizing a wide range of objects and categories in 3D environments. By fusing information from 2D foundation models and utilizing region-aware contrastive learning, the system can generate high-quality 3D representations without the need for expensive human-annotated 3D data.
The impressive performance improvements demonstrated on several benchmarks, coupled with the framework's scalability and flexibility, suggest that RegionPLC could have a significant impact on a variety of 3D perception and reasoning applications, from autonomous navigation to 3D-grounded language understanding. As the research community continues to explore the frontiers of 3D scene understanding and 3D representation learning, frameworks like RegionPLC will undoubtedly play a crucial role in advancing the state of the art and unlocking new possibilities for 3D reasoning and interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
RegionPLC: Regional Point-Language Contrastive Learning for Open-World 3D Scene Understanding
Jihan Yang, Runyu Ding, Weipeng Deng, Zhe Wang, Xiaojuan Qi
We propose a lightweight and scalable Regional Point-Language Contrastive learning framework, namely textbf{RegionPLC}, for open-world 3D scene understanding, aiming to identify and recognize open-set objects and categories. Specifically, based on our empirical studies, we introduce a 3D-aware SFusion strategy that fuses 3D vision-language pairs derived from multiple 2D foundation models, yielding high-quality, dense region-level language descriptions without human 3D annotations. Subsequently, we devise a region-aware point-discriminative contrastive learning objective to enable robust and effective 3D learning from dense regional language supervision. We carry out extensive experiments on ScanNet, ScanNet200, and nuScenes datasets, and our model outperforms prior 3D open-world scene understanding approaches by an average of 17.2% and 9.1% for semantic and instance segmentation, respectively, while maintaining greater scalability and lower resource demands. Furthermore, our method has the flexibility to be effortlessly integrated with language models to enable open-ended grounded 3D reasoning without extra task-specific training. Code is available at https://github.com/CVMI-Lab/PLA.
Read more5/7/2024

0
More Text, Less Point: Towards 3D Data-Efficient Point-Language Understanding
Yuan Tang, Xu Han, Xianzhi Li, Qiao Yu, Jinfeng Xu, Yixue Hao, Long Hu, Min Chen
Enabling Large Language Models (LLMs) to comprehend the 3D physical world remains a significant challenge. Due to the lack of large-scale 3D-text pair datasets, the success of LLMs has yet to be replicated in 3D understanding. In this paper, we rethink this issue and propose a new task: 3D Data-Efficient Point-Language Understanding. The goal is to enable LLMs to achieve robust 3D object understanding with minimal 3D point cloud and text data pairs. To address this task, we introduce GreenPLM, which leverages more text data to compensate for the lack of 3D data. First, inspired by using CLIP to align images and text, we utilize a pre-trained point cloud-text encoder to map the 3D point cloud space to the text space. This mapping leaves us to seamlessly connect the text space with LLMs. Once the point-text-LLM connection is established, we further enhance text-LLM alignment by expanding the intermediate text space, thereby reducing the reliance on 3D point cloud data. Specifically, we generate 6M free-text descriptions of 3D objects, and design a three-stage training strategy to help LLMs better explore the intrinsic connections between different modalities. To achieve efficient modality alignment, we design a zero-parameter cross-attention module for token pooling. Extensive experimental results show that GreenPLM requires only 12% of the 3D training data used by existing state-of-the-art models to achieve superior 3D understanding. Remarkably, GreenPLM also achieves competitive performance using text-only data. The code and weights are available at: https://github.com/TangYuan96/GreenPLM.
Read more9/6/2024
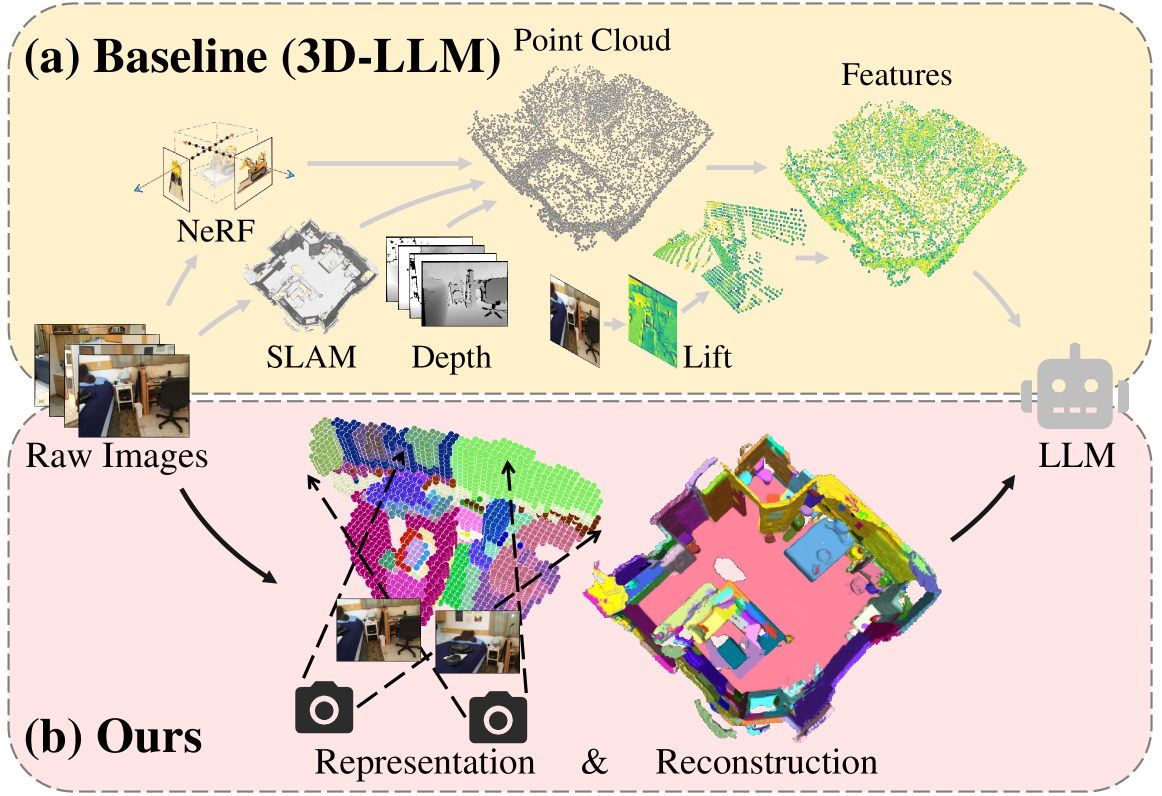
0
Unified Scene Representation and Reconstruction for 3D Large Language Models
Tao Chu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Qiong Liu, Jiaqi Wang
Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR^2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR^2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8%). When applied to LLMs, our Uni3DR^2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0% and +4.2% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
Read more4/22/2024
🛠️
0
Optimization Efficient Open-World Visual Region Recognition
Haosen Yang, Chuofan Ma, Bin Wen, Yi Jiang, Zehuan Yuan, Xiatian Zhu
Understanding the semantics of individual regions or patches of unconstrained images, such as open-world object detection, remains a critical yet challenging task in computer vision. Building on the success of powerful image-level vision-language (ViL) foundation models like CLIP, recent efforts have sought to harness their capabilities by either training a contrastive model from scratch with an extensive collection of region-label pairs or aligning the outputs of a detection model with image-level representations of region proposals. Despite notable progress, these approaches are plagued by computationally intensive training requirements, susceptibility to data noise, and deficiency in contextual information. To address these limitations, we explore the synergistic potential of off-the-shelf foundation models, leveraging their respective strengths in localization and semantics. We introduce a novel, generic, and efficient architecture, named RegionSpot, designed to integrate position-aware localization knowledge from a localization foundation model (e.g., SAM) with semantic information from a ViL model (e.g., CLIP). To fully exploit pretrained knowledge while minimizing training overhead, we keep both foundation models frozen, focusing optimization efforts solely on a lightweight attention-based knowledge integration module. Extensive experiments in open-world object recognition show that our RegionSpot achieves significant performance gain over prior alternatives, along with substantial computational savings (e.g., training our model with 3 million data in a single day using 8 V100 GPUs). RegionSpot outperforms GLIP-L by 2.9 in mAP on LVIS val set, with an even larger margin of 13.1 AP for more challenging and rare categories, and a 2.5 AP increase on ODinW. Furthermore, it exceeds GroundingDINO-L by 11.0 AP for rare categories on the LVIS minival set.
Read more6/14/2024