Optimization Efficient Open-World Visual Region Recognition

0
🛠️
Sign in to get full access
Overview
- This paper explores a novel approach called RegionSpot to improve open-world object detection by leveraging the strengths of pre-trained computer vision and language models.
- Open-world object detection, where models must recognize objects in unconstrained images, remains a challenging task in computer vision.
- Recent efforts have attempted to harness the capabilities of powerful vision-language models like CLIP, but these approaches have limitations, such as computationally intensive training and susceptibility to data noise.
- The authors of this paper propose RegionSpot, a generic and efficient architecture that integrates localization knowledge from a localization model (e.g., SAM) with semantic information from a vision-language model (e.g., CLIP).
Plain English Explanation
The paper aims to solve the problem of open-world object detection, which is the task of recognizing objects in unconstrained images, like those you might find on the internet. This is a challenging problem in computer vision because the objects can appear in many different sizes, positions, and contexts.
Recent approaches have tried to use powerful AI models that can understand both images and language, like CLIP, to help with this task. However, these methods have some drawbacks, such as requiring a lot of computational power to train and being sensitive to errors in the training data.
To address these limitations, the researchers developed a new system called RegionSpot. RegionSpot combines the strengths of two different types of AI models: a localization model, which is good at identifying the positions of objects in an image, and a vision-language model, which is good at understanding the semantic meaning of objects.
By integrating these two types of models in a clever way, RegionSpot is able to achieve significant performance improvements in open-world object detection, while also being much more efficient to train than previous approaches.
Technical Explanation
The key innovation of this paper is the RegionSpot architecture, which integrates position-aware localization knowledge from a foundation model like SAM with semantic information from a vision-language model like CLIP.
To fully exploit the pre-trained knowledge of these foundation models while minimizing training overhead, the authors keep both models frozen and focus the optimization efforts solely on a lightweight attention-based knowledge integration module.
Through extensive experiments on open-world object recognition benchmarks, the authors demonstrate that RegionSpot achieves significant performance gains over prior alternatives, such as:
- Outperforming GLIP-L by 2.9 in mAP on the LVIS validation set, with an even larger margin of 13.1 AP for more challenging and rare categories.
- Exceeding GroundingDINO-L by 11.0 AP for rare categories on the LVIS minival set.
- Achieving these improvements while requiring substantially less computational resources (e.g., training the model with 3 million data points in a single day using 8 V100 GPUs).
Critical Analysis
The authors of this paper have presented a compelling solution to the challenge of open-world object detection. By leveraging the complementary strengths of localization and vision-language models, RegionSpot demonstrates significant performance gains over previous approaches.
However, the paper does not delve into the potential limitations or caveats of this approach. For example, it would be interesting to know how well RegionSpot performs on more complex or ambiguous images, where the context and semantic understanding may play a more crucial role.
Additionally, the paper does not provide much insight into the inner workings of the attention-based knowledge integration module. A deeper exploration of this component and its impact on the overall performance would help readers better understand the key innovations.
Nonetheless, the authors' focus on leveraging pre-trained models and minimizing training overhead is a promising direction for improving the efficiency and accessibility of advanced computer vision systems. Future research could explore ways to further enhance the contextual understanding and generalization capabilities of RegionSpot, potentially through regional contrastive learning or other innovative approaches.
Conclusion
This paper presents a novel and efficient solution, called RegionSpot, for the challenge of open-world object detection. By integrating the localization knowledge of a foundation model with the semantic understanding of a vision-language model, RegionSpot achieves significant performance gains over prior alternatives while requiring substantially less computational resources.
The authors' approach of leveraging pre-trained models and minimizing training overhead is a promising direction for advancing computer vision systems and making them more accessible to a wider range of applications and users. As the field of AI continues to evolve, research like this will play a crucial role in pushing the boundaries of what's possible and unlocking new opportunities for real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Optimization Efficient Open-World Visual Region Recognition
Haosen Yang, Chuofan Ma, Bin Wen, Yi Jiang, Zehuan Yuan, Xiatian Zhu
Understanding the semantics of individual regions or patches of unconstrained images, such as open-world object detection, remains a critical yet challenging task in computer vision. Building on the success of powerful image-level vision-language (ViL) foundation models like CLIP, recent efforts have sought to harness their capabilities by either training a contrastive model from scratch with an extensive collection of region-label pairs or aligning the outputs of a detection model with image-level representations of region proposals. Despite notable progress, these approaches are plagued by computationally intensive training requirements, susceptibility to data noise, and deficiency in contextual information. To address these limitations, we explore the synergistic potential of off-the-shelf foundation models, leveraging their respective strengths in localization and semantics. We introduce a novel, generic, and efficient architecture, named RegionSpot, designed to integrate position-aware localization knowledge from a localization foundation model (e.g., SAM) with semantic information from a ViL model (e.g., CLIP). To fully exploit pretrained knowledge while minimizing training overhead, we keep both foundation models frozen, focusing optimization efforts solely on a lightweight attention-based knowledge integration module. Extensive experiments in open-world object recognition show that our RegionSpot achieves significant performance gain over prior alternatives, along with substantial computational savings (e.g., training our model with 3 million data in a single day using 8 V100 GPUs). RegionSpot outperforms GLIP-L by 2.9 in mAP on LVIS val set, with an even larger margin of 13.1 AP for more challenging and rare categories, and a 2.5 AP increase on ODinW. Furthermore, it exceeds GroundingDINO-L by 11.0 AP for rare categories on the LVIS minival set.
Read more6/14/2024

0
Region-centric Image-Language Pretraining for Open-Vocabulary Detection
Dahun Kim, Anelia Angelova, Weicheng Kuo
We present a new open-vocabulary detection approach based on region-centric image-language pretraining to bridge the gap between image-level pretraining and open-vocabulary object detection. At the pretraining phase, we incorporate the detector architecture on top of the classification backbone, which better serves the region-level recognition needs of detection by enabling the detector heads to learn from large-scale image-text pairs. Using only standard contrastive loss and no pseudo-labeling, our approach is a simple yet effective extension of the contrastive learning method to learn emergent object-semantic cues. In addition, we propose a shifted-window learning approach upon window attention to make the backbone representation more robust, translation-invariant, and less biased by the window pattern. On the popular LVIS open-vocabulary detection benchmark, our approach sets a new state of the art of 37.6 mask APr using the common ViT-L backbone and public LAION dataset, and 40.5 mask APr using the DataComp-1B dataset, significantly outperforming the best existing approach by +3.7 mask APr at system level. On the COCO benchmark, we achieve very competitive 39.6 novel AP without pseudo labeling or weak supervision. In addition, we evaluate our approach on the transfer detection setup, where it demonstrates notable improvement over the baseline. Visualization reveals emerging object locality from the pretraining recipes compared to the baseline.
Read more7/22/2024
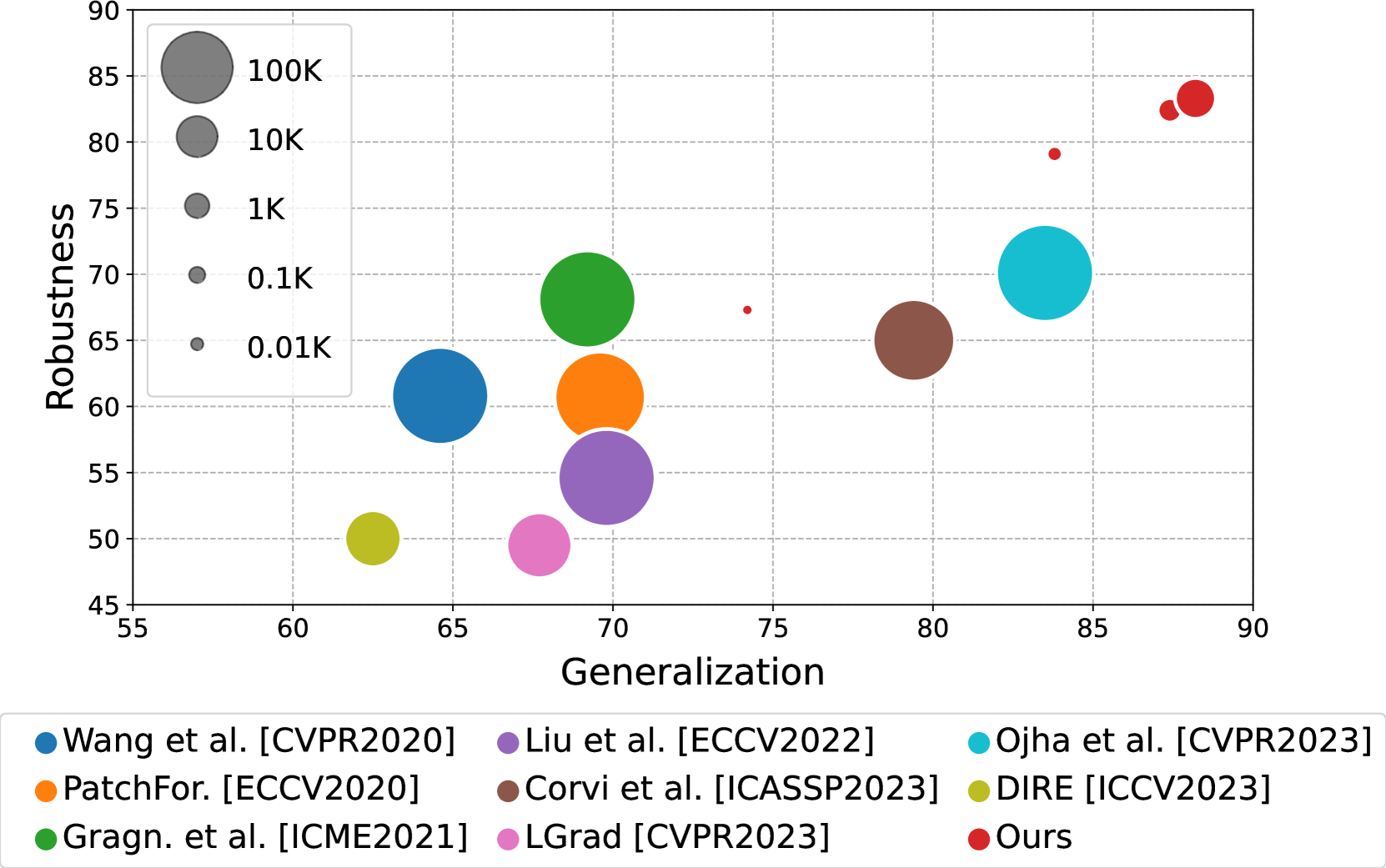
0
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
Read more4/30/2024

0
Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
Zihan Liu, Hanyi Wang, Yaoyu Kang, Shilin Wang
Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
Read more4/9/2024