ReGround: Improving Textual and Spatial Grounding at No Cost

0

Sign in to get full access
Overview
- The paper introduces a novel technique called "ReGround" that improves both textual and spatial grounding in diffusion models at no additional cost.
- Textual grounding refers to the ability of a model to understand and relate language to visual concepts, while spatial grounding refers to the model's understanding of the spatial relationships between objects.
- ReGround works by rewiring the connections within the model's architecture to better integrate these two key capabilities.
Plain English Explanation
[object Object] is the ability of an AI model to understand the meaning of words and relate them to visual concepts. For example, if you show the model an image of a dog, it should be able to recognize that the word "dog" applies to that image.
[object Object] is the model's understanding of the spatial relationships between objects in an image or scene. This allows the model to know that a dog is typically located on the ground, rather than floating in the air.
The ReGround technique improves both of these capabilities by modifying the connections within the model's neural network. This "rewiring" helps the model better integrate its textual and spatial understanding, allowing it to perform tasks like generating text-to-video or adapting backgrounds to text more effectively.
Importantly, ReGround achieves these improvements without requiring any additional training or computational resources, making it a cost-effective way to enhance model capabilities.
Technical Explanation
The key idea behind ReGround is to rewire the connections within the diffusion model's architecture to better integrate textual and spatial grounding. Diffusion models are a type of generative AI that can be used for tasks like text-to-video generation.
The authors hypothesize that by modifying the model's internal connections, they can improve its ability to understand the relationships between language and visual concepts, as well as the spatial relationships between objects. This is accomplished through a novel network rewiring technique that selectively strengthens or weakens connections within the model.
In their experiments, the researchers demonstrate that ReGround can enhance textual and spatial grounding performance on a variety of benchmark tasks, without requiring any additional training or computational resources. This makes it a cost-effective way to improve model capabilities compared to training entirely new models from scratch.
Critical Analysis
The ReGround technique presents a clever and efficient approach to improving the grounding capabilities of diffusion models. By focusing on the internal connections of the model, rather than training new components, the authors are able to achieve performance gains at no additional cost.
However, it's important to note that the scope of the evaluation in the paper is relatively limited, focusing primarily on textual and spatial grounding tasks. It would be valuable to see how ReGround generalizes to a wider range of applications, such as text-to-video generation or background adaptation.
Additionally, the underlying mechanisms by which ReGround improves grounding are not fully explored or explained. Further research into the specific connections that are strengthened or weakened, and how this impacts the model's internal representations, could provide valuable insights.
Conclusion
The ReGround technique presented in this paper offers a novel and cost-effective way to enhance the grounding capabilities of diffusion models. By rewiring the internal connections of the model, the authors are able to improve both textual and spatial understanding without requiring any additional training or computational resources.
This efficient approach to improving model performance has the potential to benefit a wide range of applications, from text-to-video generation to background adaptation. While the current evaluation is limited, the core ideas behind ReGround suggest that it could be a valuable tool for researchers and practitioners working with diffusion models and other generative AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ReGround: Improving Textual and Spatial Grounding at No Cost
Phillip Y. Lee, Minhyuk Sung
When an image generation process is guided by both a text prompt and spatial cues, such as a set of bounding boxes, do these elements work in harmony, or does one dominate the other? Our analysis of a pretrained image diffusion model that integrates gated self-attention into the U-Net reveals that spatial grounding often outweighs textual grounding due to the sequential flow from gated self-attention to cross-attention. We demonstrate that such bias can be significantly mitigated without sacrificing accuracy in either grounding by simply rewiring the network architecture, changing from sequential to parallel for gated self-attention and cross-attention. This surprisingly simple yet effective solution does not require any fine-tuning of the network but significantly reduces the trade-off between the two groundings. Our experiments demonstrate significant improvements from the original GLIGEN to the rewired version in the trade-off between textual grounding and spatial grounding.
Read more7/22/2024

0
New!GroundingBooth: Grounding Text-to-Image Customization
Zhexiao Xiong, Wei Xiong, Jing Shi, He Zhang, Yizhi Song, Nathan Jacobs
Recent studies in text-to-image customization show great success in generating personalized object variants given several images of a subject. While existing methods focus more on preserving the identity of the subject, they often fall short of controlling the spatial relationship between objects. In this work, we introduce GroundingBooth, a framework that achieves zero-shot instance-level spatial grounding on both foreground subjects and background objects in the text-to-image customization task. Our proposed text-image grounding module and masked cross-attention layer allow us to generate personalized images with both accurate layout alignment and identity preservation while maintaining text-image coherence. With such layout control, our model inherently enables the customization of multiple subjects at once. Our model is evaluated on both layout-guided image synthesis and reference-based customization tasks, showing strong results compared to existing methods. Our work is the first work to achieve a joint grounding of both subject-driven foreground generation and text-driven background generation.
Read more9/16/2024

0
Learning Visual Grounding from Generative Vision and Language Model
Shijie Wang, Dahun Kim, Ali Taalimi, Chen Sun, Weicheng Kuo
Visual grounding tasks aim to localize image regions based on natural language references. In this work, we explore whether generative VLMs predominantly trained on image-text data could be leveraged to scale up the text annotation of visual grounding data. We find that grounding knowledge already exists in generative VLM and can be elicited by proper prompting. We thus prompt a VLM to generate object-level descriptions by feeding it object regions from existing object detection datasets. We further propose attribute modeling to explicitly capture the important object attributes, and spatial relation modeling to capture inter-object relationship, both of which are common linguistic pattern in referring expression. Our constructed dataset (500K images, 1M objects, 16M referring expressions) is one of the largest grounding datasets to date, and the first grounding dataset with purely model-generated queries and human-annotated objects. To verify the quality of this data, we conduct zero-shot transfer experiments to the popular RefCOCO benchmarks for both referring expression comprehension (REC) and segmentation (RES) tasks. On both tasks, our model significantly outperform the state-of-the-art approaches without using human annotated visual grounding data. Our results demonstrate the promise of generative VLM to scale up visual grounding in the real world. Code and models will be released.
Read more7/23/2024
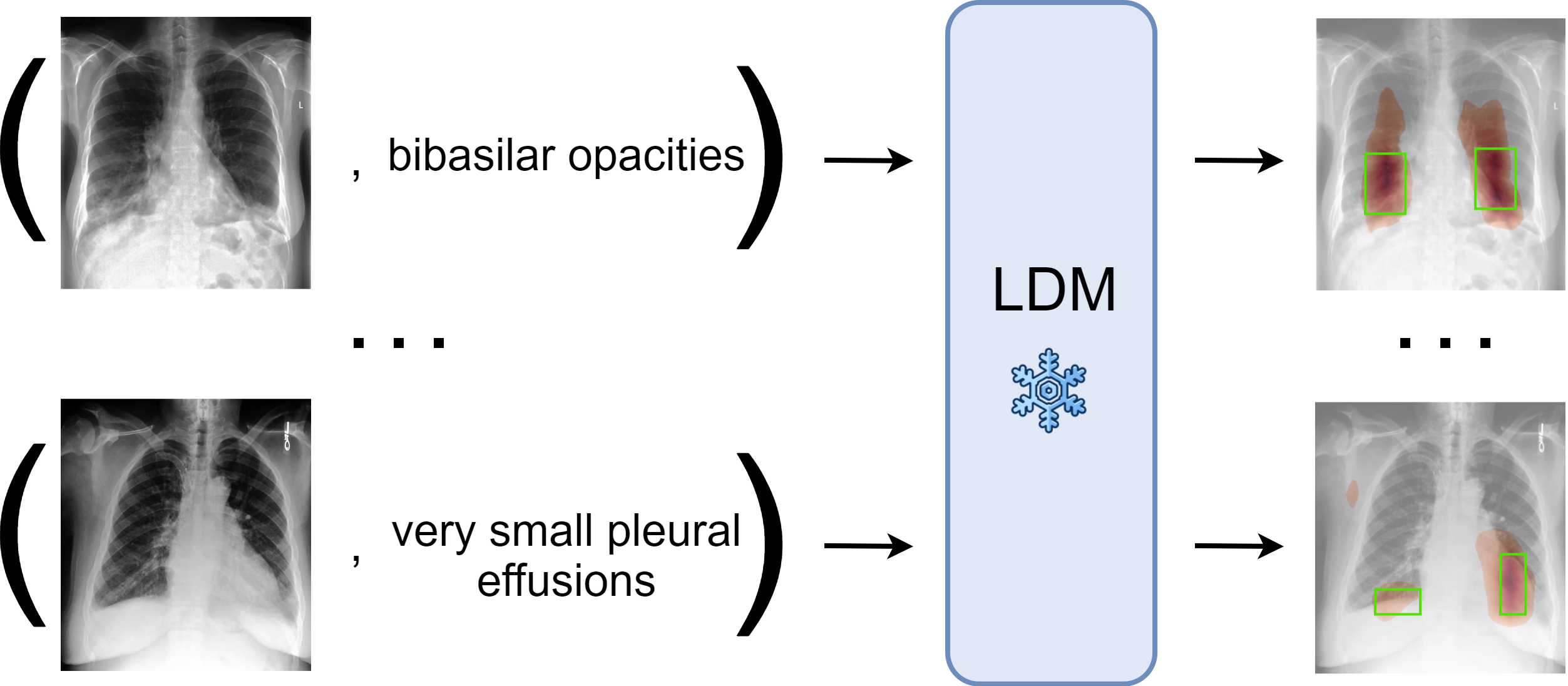
0
Zero-Shot Medical Phrase Grounding with Off-the-shelf Diffusion Models
Konstantinos Vilouras, Pedro Sanchez, Alison Q. O'Neil, Sotirios A. Tsaftaris
Localizing the exact pathological regions in a given medical scan is an important imaging problem that requires a large amount of bounding box ground truth annotations to be accurately solved. However, there exist alternative, potentially weaker, forms of supervision, such as accompanying free-text reports, which are readily available. The task of performing localization with textual guidance is commonly referred to as phrase grounding. In this work, we use a publicly available Foundation Model, namely the Latent Diffusion Model, to solve this challenging task. This choice is supported by the fact that the Latent Diffusion Model, despite being generative in nature, contains mechanisms (cross-attention) that implicitly align visual and textual features, thus leading to intermediate representations that are suitable for the task at hand. In addition, we aim to perform this task in a zero-shot manner, i.e., without any further training on target data, meaning that the model's weights remain frozen. To this end, we devise strategies to select features and also refine them via post-processing without extra learnable parameters. We compare our proposed method with state-of-the-art approaches which explicitly enforce image-text alignment in a joint embedding space via contrastive learning. Results on a popular chest X-ray benchmark indicate that our method is competitive wih SOTA on different types of pathology, and even outperforms them on average in terms of two metrics (mean IoU and AUC-ROC). Source code will be released upon acceptance.
Read more7/18/2024