Reinforcement Learning with Adaptive Control Regularization for Safe Control of Critical Systems

0
🏅
Sign in to get full access
Overview
- The paper proposes a new method called RL-ACR (Reinforcement Learning with Adaptive Control Regularization) to address the safety concerns of using Reinforcement Learning (RL) in critical systems.
- RL-ACR combines the RL policy with a control regularizer that enforces safety constraints on the system's forecasted behaviors.
- The adaptability is achieved by using a learnable focus weight that gradually increases the reliance on the RL policy as it improves through off-policy learning.
Plain English Explanation
Reinforcement Learning (RL) is a powerful technique for controlling dynamic systems, but it can sometimes lead to unpredictable and potentially unsafe actions. The paper introduces a new approach called RL-ACR that aims to make RL safer for critical applications.
The key idea is to combine the RL policy with an additional "control regularizer" that hard-codes safety constraints into the system. This regularizer helps ensure that the overall behavior of the system stays within safe bounds, even as the RL policy continues to learn and improve.
The adaptability of RL-ACR comes from a learnable "focus weight" that determines how much the system relies on the RL policy versus the control regularizer. As the RL policy gets better over time through off-policy learning, the focus weight gradually shifts to give more weight to the RL policy, allowing it to take on a larger role in controlling the system.
The researchers demonstrate the effectiveness of RL-ACR in a critical medical control application and four classic control environments. The approach helps ensure the safety of the system while still allowing the benefits of RL to improve performance.
Technical Explanation
The paper proposes a novel method called RL-ACR (Reinforcement Learning with Adaptive Control Regularization) to address the safety concerns of using Reinforcement Learning (RL) in critical systems. RL-ACR combines the RL policy with a control regularizer that enforces safety constraints on the system's forecasted behaviors.
The adaptability of RL-ACR is achieved by using a learnable "focus weight" that is trained to maximize the cumulative reward of the policy combination. As the RL policy improves through off-policy learning, the focus weight gradually increases the reliance on the RL policy, allowing it to take on a larger role in controlling the system.
The researchers evaluate the effectiveness of RL-ACR in a critical medical control application and four classic control environments, including inverted pendulum, cart-pole, continuous mountain car, and multi-agent pursuit-evasion. The results demonstrate that RL-ACR can effectively balance safety and performance, particularly in safety-critical applications.
Critical Analysis
The paper presents a thoughtful approach to address the safety concerns of using RL in critical systems. The adaptive control regularization method seems promising, as it allows the RL policy to gradually take on a larger role as it improves, while still maintaining safety constraints.
However, the paper does not provide a comprehensive analysis of the potential limitations or edge cases of the RL-ACR method. For example, it would be helpful to understand how the approach would perform in scenarios with more complex system dynamics or when the RL policy struggles to learn an effective policy.
Additionally, the paper could have explored the sensitivity of the RL-ACR method to the choice of hyperparameters, such as the weighting of the control regularizer or the learning rate of the focus weight. Understanding these factors could help guide the practical implementation of the method in real-world applications.
Further research could also investigate the generalizability of RL-ACR to a wider range of critical control problems, including applications with higher stakes or more stringent safety requirements, such as safe reinforcement learning.
Conclusion
The RL-ACR method proposed in this paper represents an important step towards making Reinforcement Learning safer for use in critical systems. By combining the RL policy with a control regularizer and an adaptive focus weight, the approach can balance the benefits of RL's learning capabilities with the need to ensure safe and predictable system behaviors.
While the paper demonstrates the effectiveness of RL-ACR in several test environments, further research is needed to fully understand its limitations and generalizability. Nonetheless, the core ideas presented in this work have the potential to significantly improve the deployment of RL in safety-critical applications, with far-reaching implications for industries such as healthcare, transportation, and manufacturing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Reinforcement Learning with Adaptive Control Regularization for Safe Control of Critical Systems
Haozhe Tian, Homayoun Hamedmoghadam, Robert Shorten, Pietro Ferraro
Reinforcement Learning (RL) is a powerful method for controlling dynamic systems, but its learning mechanism can lead to unpredictable actions that undermine the safety of critical systems. Here, we propose RL with Adaptive Control Regularization (RL-ACR), an algorithm that enables safe RL exploration by combining the RL policy with a policy regularizer that hard-codes safety constraints. We perform policy combination via a focus network, which determines the appropriate combination depending on the state -- relying more on the safe policy regularizer for less-exploited states while allowing unbiased convergence for well-exploited states. In a series of critical control applications, we demonstrate that RL-ACR ensures safety during training while achieving the performance standards of model-free RL approaches that disregard safety.
Read more5/24/2024

0
Online Behavior Modification for Expressive User Control of RL-Trained Robots
Isaac Sheidlower, Mavis Murdock, Emma Bethel, Reuben M. Aronson, Elaine Schaertl Short
Reinforcement Learning (RL) is an effective method for robots to learn tasks. However, in typical RL, end-users have little to no control over how the robot does the task after the robot has been deployed. To address this, we introduce the idea of online behavior modification, a paradigm in which users have control over behavior features of a robot in real time as it autonomously completes a task using an RL-trained policy. To show the value of this user-centered formulation for human-robot interaction, we present a behavior diversity based algorithm, Adjustable Control Of RL Dynamics (ACORD), and demonstrate its applicability to online behavior modification in simulation and a user study. In the study (n=23) users adjust the style of paintings as a robot traces a shape autonomously. We compare ACORD to RL and Shared Autonomy (SA), and show ACORD affords user-preferred levels of control and expression, comparable to SA, but with the potential for autonomous execution and robustness of RL.
Read more9/2/2024
🚀
0
ISAACS: Iterative Soft Adversarial Actor-Critic for Safety
Kai-Chieh Hsu, Duy Phuong Nguyen, Jaime Fern'andez Fisac
The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable deep methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial disturbance agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer's uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
Read more6/11/2024
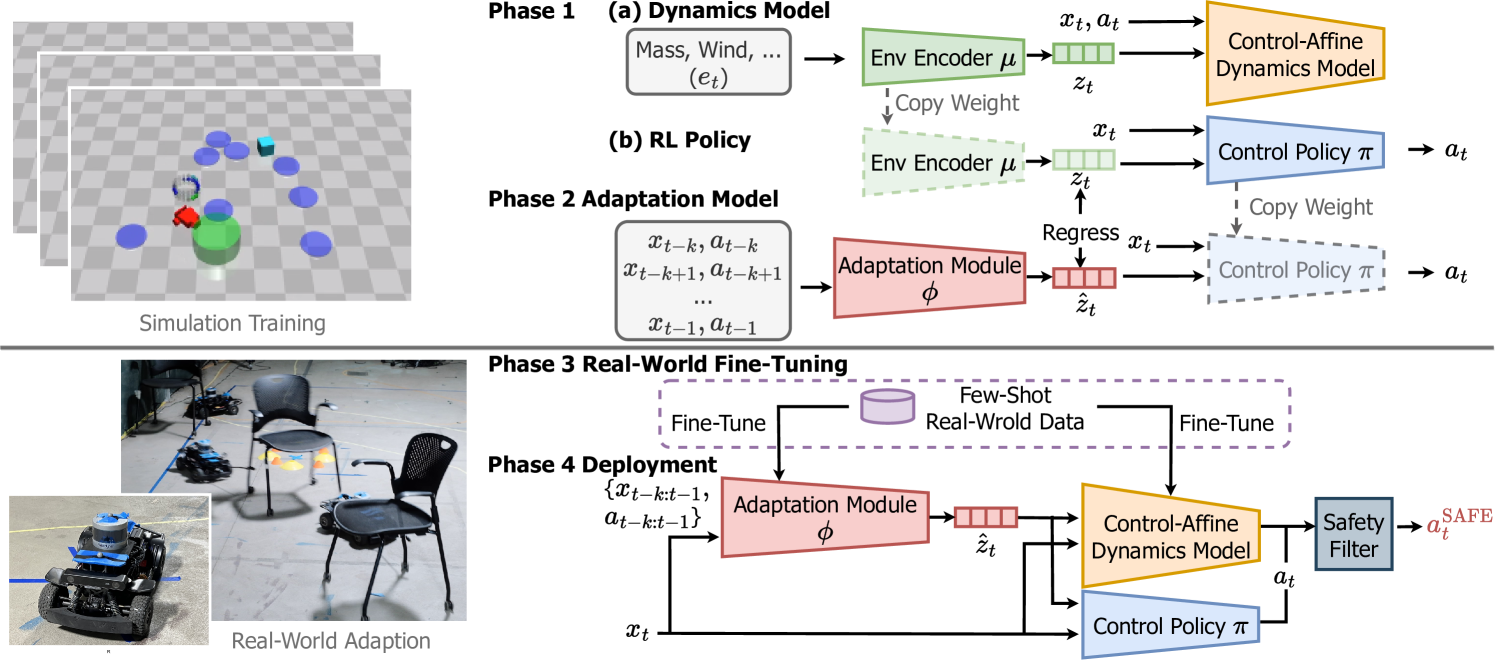
0
Safe Deep Policy Adaptation
Wenli Xiao, Tairan He, John Dolan, Guanya Shi
A critical goal of autonomy and artificial intelligence is enabling autonomous robots to rapidly adapt in dynamic and uncertain environments. Classic adaptive control and safe control provide stability and safety guarantees but are limited to specific system classes. In contrast, policy adaptation based on reinforcement learning (RL) offers versatility and generalizability but presents safety and robustness challenges. We propose SafeDPA, a novel RL and control framework that simultaneously tackles the problems of policy adaptation and safe reinforcement learning. SafeDPA jointly learns adaptive policy and dynamics models in simulation, predicts environment configurations, and fine-tunes dynamics models with few-shot real-world data. A safety filter based on the Control Barrier Function (CBF) on top of the RL policy is introduced to ensure safety during real-world deployment. We provide theoretical safety guarantees of SafeDPA and show the robustness of SafeDPA against learning errors and extra perturbations. Comprehensive experiments on (1) classic control problems (Inverted Pendulum), (2) simulation benchmarks (Safety Gym), and (3) a real-world agile robotics platform (RC Car) demonstrate great superiority of SafeDPA in both safety and task performance, over state-of-the-art baselines. Particularly, SafeDPA demonstrates notable generalizability, achieving a 300% increase in safety rate compared to the baselines, under unseen disturbances in real-world experiments.
Read more4/30/2024