A Reinforcement Learning Based Motion Planner for Quadrotor Autonomous Flight in Dense Environment

0

Sign in to get full access
Overview
- Presents a reinforcement learning-based motion planner for quadrotor autonomous flight in dense environments
- Aims to enable quadrotors to navigate safely and efficiently through cluttered spaces
- Employs deep reinforcement learning techniques to learn an optimal control policy for the quadrotor
Plain English Explanation
This paper describes a new approach for enabling quadrotor drones to fly autonomously through crowded, obstacle-filled environments. The researchers used a technique called reinforcement learning to train the drone to navigate these complex spaces.
The key idea is that the drone learns an "optimal control policy" through trial-and-error interactions with a simulated environment. The drone is rewarded for reaching its goal while avoiding collisions, and over many iterations, it learns to make the best decisions to accomplish the task safely and efficiently.
This is an important capability, as it could enable drones to perform useful tasks like package delivery or search-and-rescue operations in cluttered urban or natural settings, where traditional motion planning approaches may struggle. By incorporating reinforcement learning, the drone can adapt to dynamic, unpredictable environments in real-time, rather than relying on pre-programmed paths.
Technical Explanation
The paper presents a reinforcement learning-based motion planner for autonomous quadrotor flight in dense environments. The authors model the quadrotor's motion planning as a Markov Decision Process (MDP), where the drone's state, actions, and rewards are defined.
They then use a deep reinforcement learning algorithm, specifically Proximal Policy Optimization (PPO), to learn an optimal control policy that maps the drone's current state to the best action to take. The state space includes the drone's position, velocity, and orientation, as well as the positions of nearby obstacles.
The reward function encourages the drone to reach its goal while avoiding collisions, with penalties for deviating from the optimal path and for collisions. Through many training episodes in a simulated environment, the drone learns to navigate through cluttered spaces efficiently and safely.
The authors validate their approach through extensive simulations and real-world experiments, demonstrating the effectiveness of their reinforcement learning-based motion planner compared to traditional planning methods.
Critical Analysis
The paper presents a promising approach for enabling quadrotors to navigate autonomously in dense, cluttered environments. The use of reinforcement learning allows the drone to adapt to dynamic, unpredictable situations in real-time, which is a significant advantage over traditional motion planning techniques.
However, the authors acknowledge several limitations and areas for future research. For example, the simulated environment may not fully capture the complexities of the real world, and the drone's sensors and actuators may introduce additional sources of uncertainty and error. Additionally, the training process can be computationally intensive and may require significant data to achieve reliable performance.
Further research could explore ways to improve the sample efficiency of the reinforcement learning algorithm, incorporate more realistic sensor models, and validate the approach in a wider range of environments and scenarios. Addressing these challenges could help make this technology more practical and scalable for real-world applications.
Conclusion
This paper presents a novel approach for enabling quadrotor drones to navigate autonomously through dense, cluttered environments using reinforcement learning. By learning an optimal control policy through trial-and-error interactions with a simulated environment, the drone can adapt to dynamic, unpredictable situations and safely reach its goal.
The potential impact of this technology is significant, as it could enable drones to perform a wide range of useful tasks in complex, real-world settings, such as package delivery or search-and-rescue operations. While the approach has some limitations that require further research, this work represents an important step forward in the development of robust and adaptive motion planning algorithms for autonomous aerial vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Reinforcement Learning Based Motion Planner for Quadrotor Autonomous Flight in Dense Environment
Zhaohong Liu, Wenxuan Gao, Yinshuai Sun, Peng Dong
Quadrotor motion planning is critical for autonomous flight in complex environments, such as rescue operations. Traditional methods often employ trajectory generation optimization and passive time allocation strategies, which can limit the exploitation of the quadrotor's dynamic capabilities and introduce delays and inaccuracies. To address these challenges, we propose a novel motion planning framework that integrates visibility path searching and reinforcement learning (RL) motion generation. Our method constructs collision-free paths using heuristic search and visibility graphs, which are then refined by an RL policy to generate low-level motion commands. We validate our approach in simulated indoor environments, demonstrating better performance than traditional methods in terms of time span.
Read more8/7/2024

0
Time-optimal Flight in Cluttered Environments via Safe Reinforcement Learning
Wei Xiao, Zhaohan Feng, Ziyu Zhou, Jian Sun, Gang Wang, Jie Chen
This paper addresses the problem of guiding a quadrotor through a predefined sequence of waypoints in cluttered environments, aiming to minimize the flight time while avoiding collisions. Previous approaches either suffer from prolonged computational time caused by solving complex non-convex optimization problems or are limited by the inherent smoothness of polynomial trajectory representations, thereby restricting the flexibility of movement. In this work, we present a safe reinforcement learning approach for autonomous drone racing with time-optimal flight in cluttered environments. The reinforcement learning policy, trained using safety and terminal rewards specifically designed to enforce near time-optimal and collision-free flight, outperforms current state-of-the-art algorithms. Additionally, experimental results demonstrate the efficacy of the proposed approach in achieving both minimum flight time and obstacle avoidance objectives in complex environments, with a commendable $66.7%$ success rate in unseen, challenging settings.
Read more7/1/2024
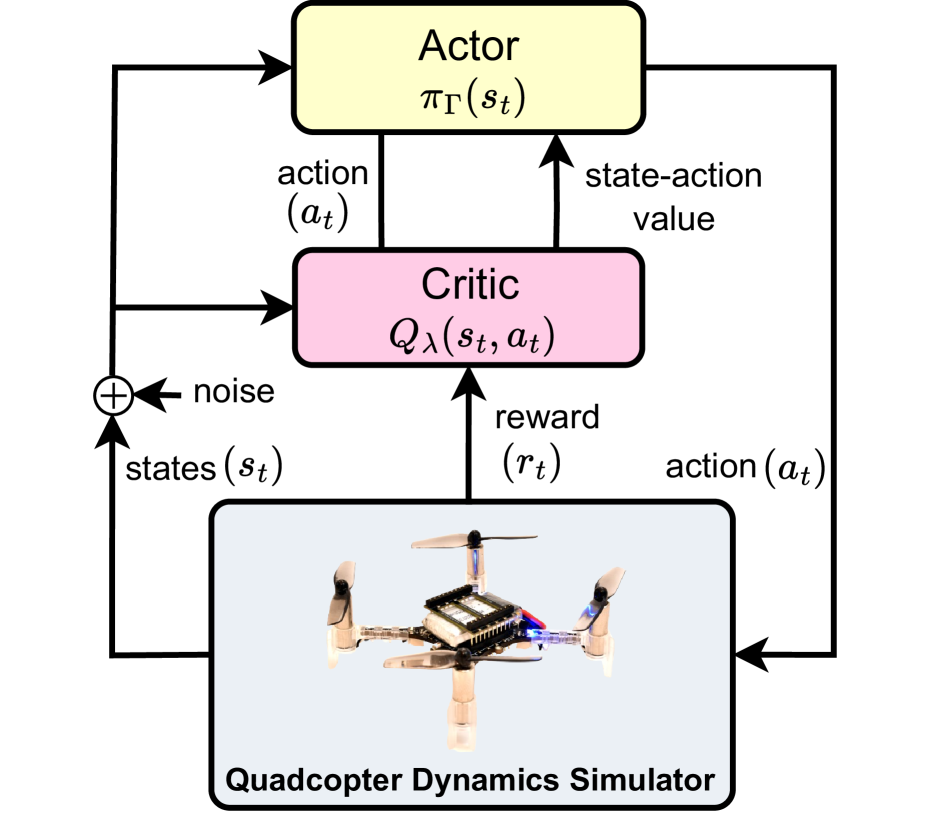
0
Deep Reinforcement Learning-based Quadcopter Controller: A Practical Approach and Experiments
Truong-Dong Do, Nguyen Xuan Mung, Sung Kyung Hong
Quadcopters have been studied for decades thanks to their maneuverability and capability of operating in a variety of circumstances. However, quadcopters suffer from dynamical nonlinearity, actuator saturation, as well as sensor noise that make it challenging and time consuming to obtain accurate dynamic models and achieve satisfactory control performance. Fortunately, deep reinforcement learning came and has shown significant potential in system modelling and control of autonomous multirotor aerial vehicles, with recent advancements in deployment, performance enhancement, and generalization. In this paper, an end-to-end deep reinforcement learning-based controller for quadcopters is proposed that is secure for real-world implementation, data-efficient, and free of human gain adjustments. First, a novel actor-critic-based architecture is designed to map the robot states directly to the motor outputs. Then, a quadcopter dynamics-based simulator was devised to facilitate the training of the controller policy. Finally, the trained policy is deployed on a real Crazyflie nano quadrotor platform, without any additional fine-tuning process. Experimental results show that the quadcopter exhibits satisfactory performance as it tracks a given complicated trajectory, which demonstrates the effectiveness and feasibility of the proposed method and signifies its capability in filling the simulation-to-reality gap.
Read more6/19/2024
0
QuAD: Query-based Interpretable Neural Motion Planning for Autonomous Driving
Sourav Biswas, Sergio Casas, Quinlan Sykora, Ben Agro, Abbas Sadat, Raquel Urtasun
A self-driving vehicle must understand its environment to determine the appropriate action. Traditional autonomy systems rely on object detection to find the agents in the scene. However, object detection assumes a discrete set of objects and loses information about uncertainty, so any errors compound when predicting the future behavior of those agents. Alternatively, dense occupancy grid maps have been utilized to understand free-space. However, predicting a grid for the entire scene is wasteful since only certain spatio-temporal regions are reachable and relevant to the self-driving vehicle. We present a unified, interpretable, and efficient autonomy framework that moves away from cascading modules that first perceive, then predict, and finally plan. Instead, we shift the paradigm to have the planner query occupancy at relevant spatio-temporal points, restricting the computation to those regions of interest. Exploiting this representation, we evaluate candidate trajectories around key factors such as collision avoidance, comfort, and progress for safety and interpretability. Our approach achieves better highway driving quality than the state-of-the-art in high-fidelity closed-loop simulations.
Read more4/3/2024