Time-optimal Flight in Cluttered Environments via Safe Reinforcement Learning
2406.19646
0
0

Abstract
This paper addresses the problem of guiding a quadrotor through a predefined sequence of waypoints in cluttered environments, aiming to minimize the flight time while avoiding collisions. Previous approaches either suffer from prolonged computational time caused by solving complex non-convex optimization problems or are limited by the inherent smoothness of polynomial trajectory representations, thereby restricting the flexibility of movement. In this work, we present a safe reinforcement learning approach for autonomous drone racing with time-optimal flight in cluttered environments. The reinforcement learning policy, trained using safety and terminal rewards specifically designed to enforce near time-optimal and collision-free flight, outperforms current state-of-the-art algorithms. Additionally, experimental results demonstrate the efficacy of the proposed approach in achieving both minimum flight time and obstacle avoidance objectives in complex environments, with a commendable $66.7%$ success rate in unseen, challenging settings.
Create account to get full access
Overview
- This research paper presents a method for time-optimal flight in cluttered environments using safe reinforcement learning.
- The approach enables a robot or drone to navigate through obstacles while minimizing flight time.
- Key techniques include a novel reward function, safety constraints, and a deep reinforcement learning algorithm.
- Experiments in simulation demonstrate the method's ability to find efficient, collision-free trajectories.
Plain English Explanation
The paper describes a way for robots or drones to fly through cluttered, obstacle-filled environments as quickly as possible while staying safe. The core idea is to use a type of artificial intelligence called reinforcement learning, which allows the robot to learn how to navigate by trial and error and receive rewards for good behavior.
The researchers designed a special reward function that encourages the robot to find the fastest path through the obstacles, while also adding constraints to keep the robot from crashing. They then used a deep neural network, a powerful machine learning technique, to help the robot learn the best way to fly based on these rewards and constraints.
Through experiments in computer simulation, the researchers showed that their approach allows the robot to plan and execute time-optimal trajectories through cluttered spaces without colliding with any obstacles. This could be useful for applications like drone delivery, search and rescue missions, or other scenarios where rapid, safe navigation is important.
Technical Explanation
The paper presents a framework for time-optimal flight in cluttered environments using safe reinforcement learning. The key components include:
-
Reward Function: The researchers designed a reward function that encourages the robot to find the fastest path through the obstacles while also incorporating safety constraints to avoid collisions.
-
Safety Constraints: The researchers incorporated safety constraints into the optimization problem to ensure that the robot maintains a minimum distance from obstacles during flight.
-
Deep Reinforcement Learning: The researchers used a deep reinforcement learning algorithm, specifically a variant of proximal policy optimization (PPO), to learn an optimal control policy for the robot. The deep neural network learns to map the robot's observations (e.g., obstacle positions) to the best control actions to take.
-
Simulation Experiments: The researchers evaluated their approach in simulation environments with various obstacle configurations. The results showed that the robot was able to plan and execute time-optimal, collision-free trajectories through the cluttered spaces.
This work builds on previous research in areas like collision-free trajectory optimization, quadcopter control, and decentralized multi-agent planning. The novel contribution of this paper is the integration of time-optimal planning, safety constraints, and deep reinforcement learning to enable rapid, collision-free navigation in cluttered environments.
Critical Analysis
The paper presents a promising approach for time-optimal flight in cluttered environments, but there are a few caveats and areas for further research:
- The experiments were conducted in simulation, and the performance of the approach in real-world scenarios with noisy sensor data and model uncertainties remains to be evaluated.
- The safety constraints in the optimization problem may be conservative, potentially leading to suboptimal trajectories in some cases. Exploring more sophisticated safety metrics or learning-based approaches to safety could be an area for future work.
- The scalability of the deep reinforcement learning algorithm to more complex environments with larger numbers of obstacles is not addressed in the paper. Techniques like hierarchical planning or distributed control may be needed to handle more complex scenarios.
Overall, this research presents an interesting and promising step towards enabling rapid, safe navigation for robots and drones in cluttered environments. Further development and real-world testing will be important to fully assess the practicality and limitations of the approach.
Conclusion
This paper introduces a method for time-optimal flight in cluttered environments using safe reinforcement learning. The key innovations include a novel reward function, safety constraints, and a deep reinforcement learning algorithm to plan and execute collision-free trajectories. Simulation experiments demonstrate the effectiveness of the approach, and the researchers highlight several areas for future work to improve the scalability and real-world applicability of the method.
If successfully deployed, this technology could have significant implications for a wide range of applications, from drone delivery and search and rescue missions to autonomous transportation and industrial automation, where the ability to navigate quickly and safely through complex environments is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning
Zhehui Huang, Zhaojing Yang, Rahul Krupani, Bask{i}n c{S}enbac{s}lar, Sumeet Batra, Gaurav S. Sukhatme
0
0
End-to-end deep reinforcement learning (DRL) for quadrotor control promises many benefits -- easy deployment, task generalization and real-time execution capability. Prior end-to-end DRL-based methods have showcased the ability to deploy learned controllers onto single quadrotors or quadrotor teams maneuvering in simple, obstacle-free environments. However, the addition of obstacles increases the number of possible interactions exponentially, thereby increasing the difficulty of training RL policies. In this work, we propose an end-to-end DRL approach to control quadrotor swarms in environments with obstacles. We provide our agents a curriculum and a replay buffer of the clipped collision episodes to improve performance in obstacle-rich environments. We implement an attention mechanism to attend to the neighbor robots and obstacle interactions - the first successful demonstration of this mechanism on policies for swarm behavior deployed on severely compute-constrained hardware. Our work is the first work that demonstrates the possibility of learning neighbor-avoiding and obstacle-avoiding control policies trained with end-to-end DRL that transfers zero-shot to real quadrotors. Our approach scales to 32 robots with 80% obstacle density in simulation and 8 robots with 20% obstacle density in physical deployment. Video demonstrations are available on the project website at: https://sites.google.com/view/obst-avoid-swarm-rl.
5/7/2024
🤿
Deep Reinforcement Learning for Time-Critical Wilderness Search And Rescue Using Drones
Jan-Hendrik Ewers, David Anderson, Douglas Thomson
0
0
Traditional search and rescue methods in wilderness areas can be time-consuming and have limited coverage. Drones offer a faster and more flexible solution, but optimizing their search paths is crucial. This paper explores the use of deep reinforcement learning to create efficient search missions for drones in wilderness environments. Our approach leverages a priori data about the search area and the missing person in the form of a probability distribution map. This allows the deep reinforcement learning agent to learn optimal flight paths that maximize the probability of finding the missing person quickly. Experimental results show that our method achieves a significant improvement in search times compared to traditional coverage planning and search planning algorithms. In one comparison, deep reinforcement learning is found to outperform other algorithms by over $160%$, a difference that can mean life or death in real-world search operations. Additionally, unlike previous work, our approach incorporates a continuous action space enabled by cubature, allowing for more nuanced flight patterns.
5/24/2024
💬
DREAM: Decentralized Real-time Asynchronous Probabilistic Trajectory Planning for Collision-free Multi-Robot Navigation in Cluttered Environments
Bask{i}n c{S}enbac{s}lar, Gaurav S. Sukhatme
0
0
Collision-free navigation in cluttered environments with static and dynamic obstacles is essential for many multi-robot tasks. Dynamic obstacles may also be interactive, i.e., their behavior varies based on the behavior of other entities. We propose a novel representation for interactive behavior of dynamic obstacles and a decentralized real-time multi-robot trajectory planning algorithm allowing inter-robot collision avoidance as well as static and dynamic obstacle avoidance. Our planner simulates the behavior of dynamic obstacles, accounting for interactivity. We account for the perception inaccuracy of static and prediction inaccuracy of dynamic obstacles. We handle asynchronous planning between teammates and message delays, drops, and re-orderings. We evaluate our algorithm in simulations using 25400 random cases and compare it against three state-of-the-art baselines using 2100 random cases. Our algorithm achieves up to 1.68x success rate using as low as 0.28x time in single-robot, and up to 2.15x success rate using as low as 0.36x time in multi-robot cases compared to the best baseline. We implement our planner on real quadrotors to show its real-world applicability.
5/21/2024
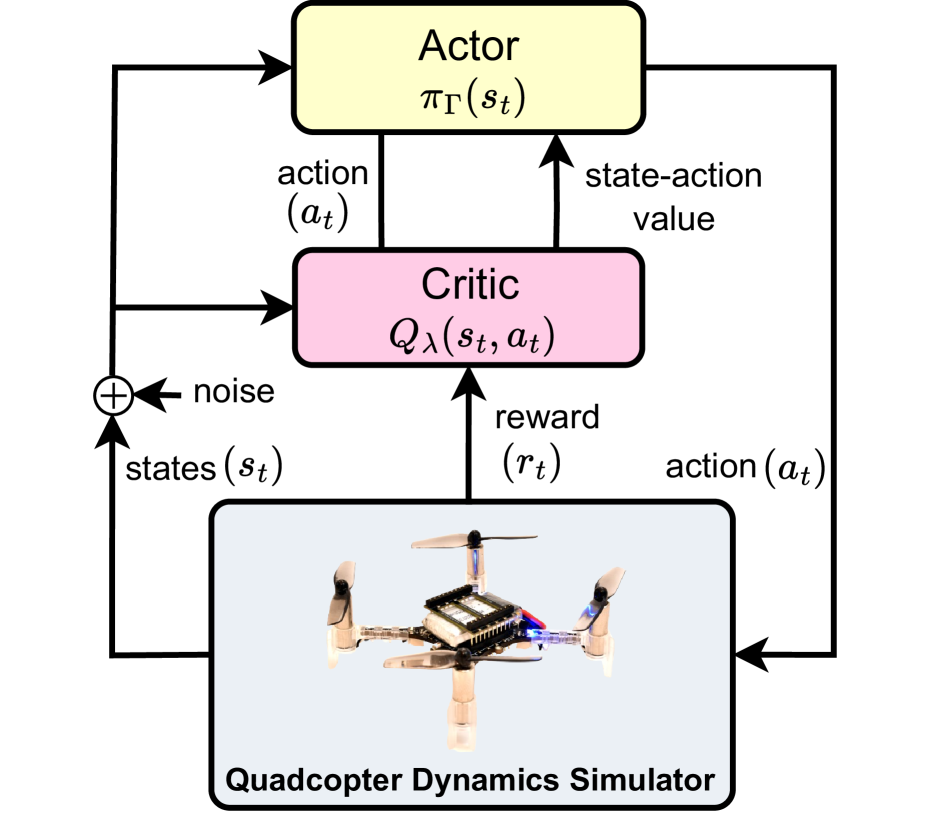
Deep Reinforcement Learning-based Quadcopter Controller: A Practical Approach and Experiments
Truong-Dong Do, Nguyen Xuan Mung, Sung Kyung Hong
0
0
Quadcopters have been studied for decades thanks to their maneuverability and capability of operating in a variety of circumstances. However, quadcopters suffer from dynamical nonlinearity, actuator saturation, as well as sensor noise that make it challenging and time consuming to obtain accurate dynamic models and achieve satisfactory control performance. Fortunately, deep reinforcement learning came and has shown significant potential in system modelling and control of autonomous multirotor aerial vehicles, with recent advancements in deployment, performance enhancement, and generalization. In this paper, an end-to-end deep reinforcement learning-based controller for quadcopters is proposed that is secure for real-world implementation, data-efficient, and free of human gain adjustments. First, a novel actor-critic-based architecture is designed to map the robot states directly to the motor outputs. Then, a quadcopter dynamics-based simulator was devised to facilitate the training of the controller policy. Finally, the trained policy is deployed on a real Crazyflie nano quadrotor platform, without any additional fine-tuning process. Experimental results show that the quadcopter exhibits satisfactory performance as it tracks a given complicated trajectory, which demonstrates the effectiveness and feasibility of the proposed method and signifies its capability in filling the simulation-to-reality gap.
6/19/2024