A Reinforcement Learning based Reset Policy for CDCL SAT Solvers
2404.03753
0
0
Abstract
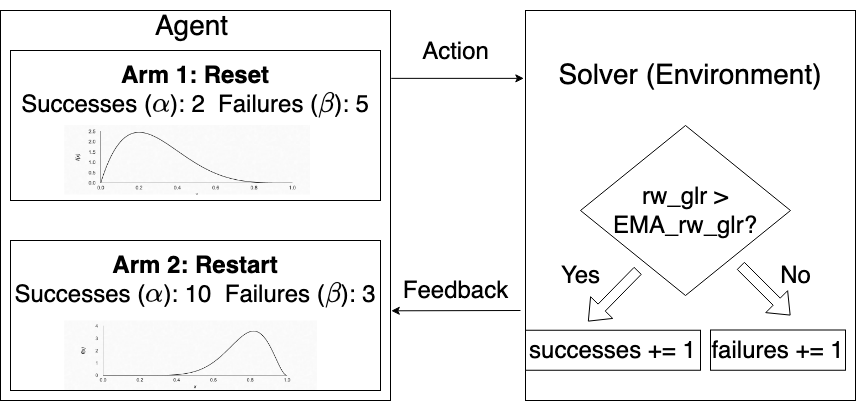
Restart policy is an important technique used in modern Conflict-Driven Clause Learning (CDCL) solvers, wherein some parts of the solver state are erased at certain intervals during the run of the solver. In most solvers, variable activities are preserved across restart boundaries, resulting in solvers continuing to search parts of the assignment tree that are not far from the one immediately prior to a restart. To enable the solver to search possibly distant parts of the assignment tree, we study the effect of resets, a variant of restarts which not only erases the assignment trail, but also randomizes the activity scores of the variables of the input formula after reset, thus potentially enabling a better global exploration of the search space. In this paper, we model the problem of whether to trigger reset as a multi-armed bandit (MAB) problem, and propose two reinforcement learning (RL) based adaptive reset policies using the Upper Confidence Bound (UCB) and Thompson sampling algorithms. These two algorithms balance the exploration-exploitation tradeoff by adaptively choosing arms (reset vs. no reset) based on their estimated rewards during the solver's run. We implement our reset policies in four baseline SOTA CDCL solvers and compare the baselines against the reset versions on Satcoin benchmarks and SAT Competition instances. Our results show that RL-based reset versions outperform the corresponding baseline solvers on both Satcoin and the SAT competition instances, suggesting that our RL policy helps to dynamically and profitably adapt the reset frequency for any given input instance. We also introduce the concept of a partial reset, where at least a constant number of variable activities are retained across reset boundaries. Building on previous results, we show that there is an exponential separation between O(1) vs. $Omega(n)$-length partial resets.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a reinforcement learning-based reset policy for CDCL (Conflict-Driven Clause Learning) SAT solvers, which are algorithms used to solve the Boolean Satisfiability (SAT) problem.
- The goal is to improve the performance of CDCL SAT solvers by intelligently determining when to reset the solver's internal state, rather than using a fixed reset strategy.
- The proposed approach uses reinforcement learning to learn an optimal reset policy that can adapt to the characteristics of the specific SAT problem instance being solved.
Plain English Explanation
The paper discusses a way to make CDCL SAT solvers more efficient. CDCL SAT solvers are algorithms that are used to solve a type of math problem called the Boolean Satisfiability (SAT) problem.
The key idea is to use reinforcement learning to teach the CDCL SAT solver when it should reset its internal state. Resetting the internal state can help the solver get unstuck when it's not making progress. But if you reset too often, it can slow down the solver. The researchers wanted to find the right balance, so they trained an AI system to learn the optimal reset strategy for each SAT problem.
The benefit of this approach is that the reset policy can adapt to the specific characteristics of the SAT problem being solved, rather than using a one-size-fits-all reset strategy. This allows the solver to be more efficient and solve problems faster.
Technical Explanation
The paper introduces a reinforcement learning-based approach to learn an optimal reset policy for CDCL SAT solvers. CDCL SAT solvers work by repeatedly making decisions about which variables to assign values to in order to satisfy a Boolean formula. When the solver gets stuck in a dead end, it can reset its internal state to try a different approach.
The key contribution of this work is to use reinforcement learning to automatically learn a reset policy that can adapt to the characteristics of the specific SAT problem being solved. The learnt policy determines when the solver should reset its state based on features like the number of conflicts, the age of learned clauses, and the current depth in the search tree.
The authors train the reset policy using a reward function that encourages faster solving times. They evaluate the approach on a suite of SAT benchmarks and show that it can outperform existing fixed reset strategies.
Critical Analysis
The paper presents a novel and promising approach to improving the performance of CDCL SAT solvers. The use of reinforcement learning to learn an adaptive reset policy is an interesting idea that could have broader applications beyond just SAT solving.
That said, the evaluation is limited to a relatively small set of benchmark instances, and it's not clear how well the approach would generalize to more diverse or complex SAT problems. Additionally, the paper does not provide much insight into the interpretability of the learned reset policy - it would be helpful to understand the specific features and decision-making process used by the policy.
Further research could explore ways to make the reset policy more robust and generalizable, as well as investigate potential applications of this approach to other combinatorial optimization problems beyond SAT.
Conclusion
This paper presents a reinforcement learning-based approach to learning an adaptive reset policy for CDCL SAT solvers. By automatically determining the optimal times to reset the solver's internal state, this method can outperform existing fixed reset strategies and solve SAT problems more efficiently.
The key innovation is the use of reinforcement learning to learn a reset policy tailored to the characteristics of the specific SAT problem being solved. This allows the solver to dynamically adjust its behavior rather than relying on a one-size-fits-all approach.
While the evaluation is limited, the paper demonstrates the potential of reinforcement learning techniques to enhance the performance of complex combinatorial optimization algorithms like CDCL SAT solvers. Further research in this direction could lead to significant advances in the field of SAT solving and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
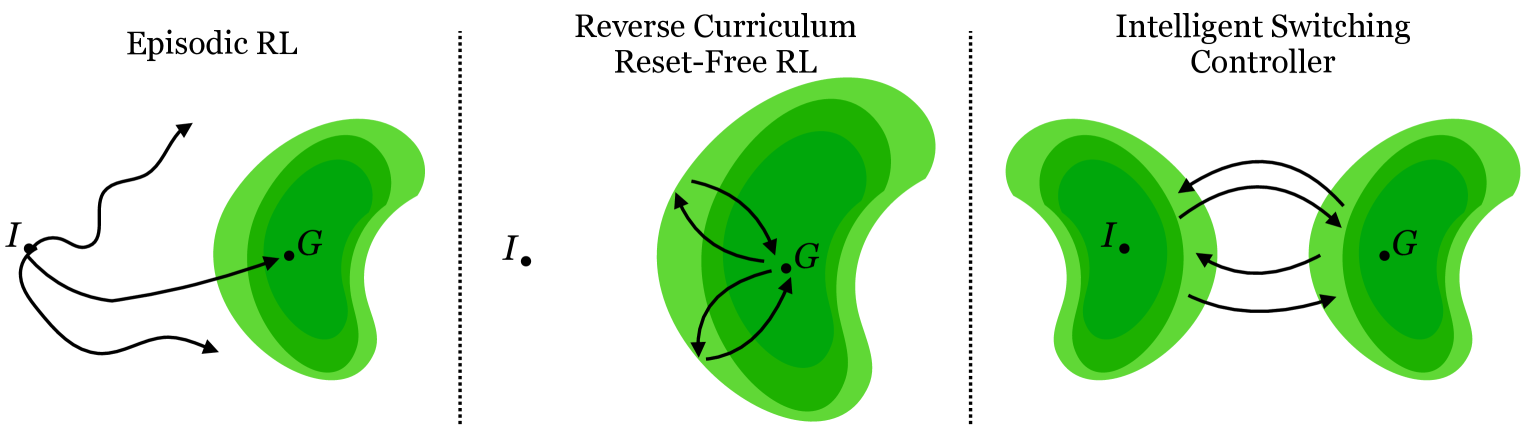
Intelligent Switching for Reset-Free RL
Darshan Patil, Janarthanan Rajendran, Glen Berseth, Sarath Chandar
0
0
In the real world, the strong episode resetting mechanisms that are needed to train agents in simulation are unavailable. The textit{resetting} assumption limits the potential of reinforcement learning in the real world, as providing resets to an agent usually requires the creation of additional handcrafted mechanisms or human interventions. Recent work aims to train agents (textit{forward}) with learned resets by constructing a second (textit{backward}) agent that returns the forward agent to the initial state. We find that the termination and timing of the transitions between these two agents are crucial for algorithm success. With this in mind, we create a new algorithm, Reset Free RL with Intelligently Switching Controller (RISC) which intelligently switches between the two agents based on the agent's confidence in achieving its current goal. Our new method achieves state-of-the-art performance on several challenging environments for reset-free RL.
5/6/2024
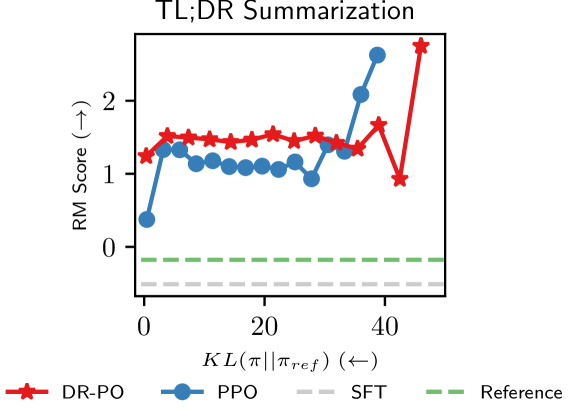
Dataset Reset Policy Optimization for RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kiant'e Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
0
0
Reinforcement Learning (RL) from Human Preference-based feedback is a popular paradigm for fine-tuning generative models, which has produced impressive models such as GPT-4 and Claude3 Opus. This framework often consists of two steps: learning a reward model from an offline preference dataset followed by running online RL to optimize the learned reward model. In this work, leveraging the idea of reset, we propose a new RLHF algorithm with provable guarantees. Motivated by the fact that offline preference dataset provides informative states (i.e., data that is preferred by the labelers), our new algorithm, Dataset Reset Policy Optimization (DR-PO), integrates the existing offline preference dataset into the online policy training procedure via dataset reset: it directly resets the policy optimizer to the states in the offline dataset, instead of always starting from the initial state distribution. In theory, we show that DR-PO learns to perform at least as good as any policy that is covered by the offline dataset under general function approximation with finite sample complexity. In experiments, we demonstrate that on both the TL;DR summarization and the Anthropic Helpful Harmful (HH) dataset, the generation from DR-PO is better than that from Proximal Policy Optimization (PPO) and Direction Preference Optimization (DPO), under the metric of GPT4 win-rate. Code for this work can be found at https://github.com/Cornell-RL/drpo.
4/17/2024
🏅
The Power of Resets in Online Reinforcement Learning
Zakaria Mhammedi, Dylan J. Foster, Alexander Rakhlin
0
0
Simulators are a pervasive tool in reinforcement learning, but most existing algorithms cannot efficiently exploit simulator access -- particularly in high-dimensional domains that require general function approximation. We explore the power of simulators through online reinforcement learning with {local simulator access} (or, local planning), an RL protocol where the agent is allowed to reset to previously observed states and follow their dynamics during training. We use local simulator access to unlock new statistical guarantees that were previously out of reach: - We show that MDPs with low coverability (Xie et al. 2023) -- a general structural condition that subsumes Block MDPs and Low-Rank MDPs -- can be learned in a sample-efficient fashion with only $Q^{star}$-realizability (realizability of the optimal state-value function); existing online RL algorithms require significantly stronger representation conditions. - As a consequence, we show that the notorious Exogenous Block MDP problem (Efroni et al. 2022) is tractable under local simulator access. The results above are achieved through a computationally inefficient algorithm. We complement them with a more computationally efficient algorithm, RVFS (Recursive Value Function Search), which achieves provable sample complexity guarantees under a strengthened statistical assumption known as pushforward coverability. RVFS can be viewed as a principled, provable counterpart to a successful empirical paradigm that combines recursive search (e.g., MCTS) with value function approximation.
4/29/2024
🏅
Nonstationary Reinforcement Learning with Linear Function Approximation
Huozhi Zhou, Jinglin Chen, Lav R. Varshney, Ashish Jagmohan
0
0
We consider reinforcement learning (RL) in episodic Markov decision processes (MDPs) with linear function approximation under drifting environment. Specifically, both the reward and state transition functions can evolve over time but their total variations do not exceed a $textit{variation budget}$. We first develop $texttt{LSVI-UCB-Restart}$ algorithm, an optimistic modification of least-squares value iteration with periodic restart, and bound its dynamic regret when variation budgets are known. Then we propose a parameter-free algorithm $texttt{Ada-LSVI-UCB-Restart}$ that extends to unknown variation budgets. We also derive the first minimax dynamic regret lower bound for nonstationary linear MDPs and as a byproduct establish a minimax regret lower bound for linear MDPs unsolved by Jin et al. (2020). Finally, we provide numerical experiments to demonstrate the effectiveness of our proposed algorithms.
4/16/2024