Reinforcement Learning Driven Cooperative Ball Balance in Rigidly Coupled Drones

0

Sign in to get full access
Overview
- This paper explores the use of reinforcement learning to enable cooperative ball balancing in a system of rigidly coupled drones.
- The researchers developed a decentralized control framework that allows the drones to work together to maintain the balance of a ball on a platform.
- The system utilizes a centralized critic network to coordinate the actions of the individual drones, which are modeled as independent agents.
- Experiments demonstrate the effectiveness of the approach in stabilizing the ball under various disturbances and configurations.
Plain English Explanation
The researchers in this paper have developed a way for a group of drones to work together to balance a ball on a platform. This is a challenging problem because the drones need to coordinate their movements precisely to keep the ball from falling off.
To solve this, the researchers used a technique called reinforcement learning. This involves training the drones to learn how to balance the ball through trial and error, with a central "critic" network providing feedback to help them improve. Each drone acts as an independent agent, making its own decisions, but the critic network helps them work together as a team.
Through experiments, the researchers showed that this decentralized control framework was effective at stabilizing the ball even when faced with disturbances or changes in the system configuration. The drones were able to adapt and coordinate their actions to keep the ball balanced.
This research could have applications in areas like aerial robotics, where teams of drones need to cooperate to accomplish complex tasks. By using reinforcement learning, the drones can learn to work together in a flexible and adaptive way, without requiring centralized control.
Technical Explanation
The paper presents a reinforcement learning-based control framework for cooperative ball balancing using a team of rigidly coupled drones. The system utilizes a decentralized control architecture where each drone is modeled as an independent agent, making its own decisions based on local observations.
To coordinate the drones' actions, the researchers employ a centralized critic network that evaluates the overall performance of the team and provides feedback to the individual agents. This allows the drones to learn cooperative strategies through reinforcement learning, without requiring explicit inter-drone communication.
The system dynamics are modeled using Radial Basis Function Neural Networks, which capture the nonlinear relationships between the drones' actions and the ball's motion. The researchers then develop a decentralized control policy that minimizes the ball's deviation from the desired position and orientation.
Through simulation experiments, the authors demonstrate the effectiveness of their approach in maintaining ball balance under various disturbances and configuration changes. The results highlight the ability of the reinforcement learning-based system to adapt and coordinate the drones' actions to achieve the desired cooperative behavior.
Critical Analysis
The paper presents a novel and promising approach to cooperative control of a team of drones for the task of ball balancing. The decentralized reinforcement learning framework allows the drones to learn effective coordination strategies without the need for explicit communication, which could be advantageous in real-world scenarios with limited bandwidth or unreliable connections.
However, the paper does not address potential issues related to the scalability of the approach as the number of drones increases. The centralized critic network may become a bottleneck as the system complexity grows, and the training process could become more challenging. Additionally, the simulated experiments do not capture the full complexity of real-world drone dynamics and environmental factors, which could introduce additional challenges in deploying the system in a physical setting.
Further research could explore distributed critic architectures or hierarchical control schemes to improve the scalability and robustness of the approach. Validating the system's performance with physical drone experiments would also be a valuable next step to assess its practical feasibility and identify any additional challenges that may arise in real-world implementation.
Conclusion
This paper presents a reinforcement learning-driven cooperative control framework for ball balancing using a team of rigidly coupled drones. The decentralized architecture, where each drone acts as an independent agent guided by a centralized critic network, allows the system to learn effective coordination strategies through trial and error.
The simulation results demonstrate the effectiveness of the approach in maintaining ball balance under various disturbances and configuration changes, highlighting the potential of reinforcement learning techniques for enabling adaptive and cooperative behaviors in multi-drone systems. Further research is needed to address the scalability and real-world deployment challenges, but this work represents an important step towards more advanced cooperative control algorithms for aerial robotics applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reinforcement Learning Driven Cooperative Ball Balance in Rigidly Coupled Drones
Shraddha Barawkar, Nikhil Chopra
Multi-drone cooperative transport (CT) problem has been widely studied in the literature. However, limited work exists on control of such systems in the presence of time-varying uncertainties, such as the time-varying center of gravity (CG). This paper presents a leader-follower approach for the control of a multi-drone CT system with time-varying CG. The leader uses a traditional Proportional-Integral-Derivative (PID) controller, and in contrast, the follower uses a deep reinforcement learning (RL) controller using only local information and minimal leader information. Extensive simulation results are presented, showing the effectiveness of the proposed method over a previously developed adaptive controller and for variations in the mass of the objects being transported and CG speeds. Preliminary experimental work also demonstrates ball balance (depicting moving CG) on a stick/rod lifted by two Crazyflie drones cooperatively.
Read more5/1/2024

0
Dashing for the Golden Snitch: Multi-Drone Time-Optimal Motion Planning with Multi-Agent Reinforcement Learning
Xian Wang, Jin Zhou, Yuanli Feng, Jiahao Mei, Jiming Chen, Shuo Li
Recent innovations in autonomous drones have facilitated time-optimal flight in single-drone configurations and enhanced maneuverability in multi-drone systems through the application of optimal control and learning-based methods. However, few studies have achieved time-optimal motion planning for multi-drone systems, particularly during highly agile maneuvers or in dynamic scenarios. This paper presents a decentralized policy network for time-optimal multi-drone flight using multi-agent reinforcement learning. To strike a balance between flight efficiency and collision avoidance, we introduce a soft collision penalty inspired by optimization-based methods. By customizing PPO in a centralized training, decentralized execution (CTDE) fashion, we unlock higher efficiency and stability in training, while ensuring lightweight implementation. Extensive simulations show that, despite slight performance trade-offs compared to single-drone systems, our multi-drone approach maintains near-time-optimal performance with low collision rates. Real-world experiments validate our method, with two quadrotors using the same network as simulation achieving a maximum speed of 13.65 m/s and a maximum body rate of 13.4 rad/s in a 5.5 m * 5.5 m * 2.0 m space across various tracks, relying entirely on onboard computation.
Read more9/26/2024
🏅
0
Reinforcement Learning based Autonomous Multi-Rotor Landing on Moving Platforms
Pascal Goldschmid, Aamir Ahmad
Multi-rotor UAVs suffer from a restricted range and flight duration due to limited battery capacity. Autonomous landing on a 2D moving platform offers the possibility to replenish batteries and offload data, thus increasing the utility of the vehicle. Classical approaches rely on accurate, complex and difficult-to-derive models of the vehicle and the environment. Reinforcement learning (RL) provides an attractive alternative due to its ability to learn a suitable control policy exclusively from data during a training procedure. However, current methods require several hours to train, have limited success rates and depend on hyperparameters that need to be tuned by trial-and-error. We address all these issues in this work. First, we decompose the landing procedure into a sequence of simpler, but similar learning tasks. This is enabled by applying two instances of the same RL based controller trained for 1D motion for controlling the multi-rotor's movement in both the longitudinal and the lateral directions. Second, we introduce a powerful state space discretization technique that is based on i) kinematic modeling of the moving platform to derive information about the state space topology and ii) structuring the training as a sequential curriculum using transfer learning. Third, we leverage the kinematics model of the moving platform to also derive interpretable hyperparameters for the training process that ensure sufficient maneuverability of the multi-rotor vehicle. The training is performed using the tabular RL method Double Q-Learning. Through extensive simulations we show that the presented method significantly increases the rate of successful landings, while requiring less training time compared to other deep RL approaches. Finally, we deploy and demonstrate our algorithm on real hardware. For all evaluation scenarios we provide statistics on the agent's performance.
Read more5/17/2024
0
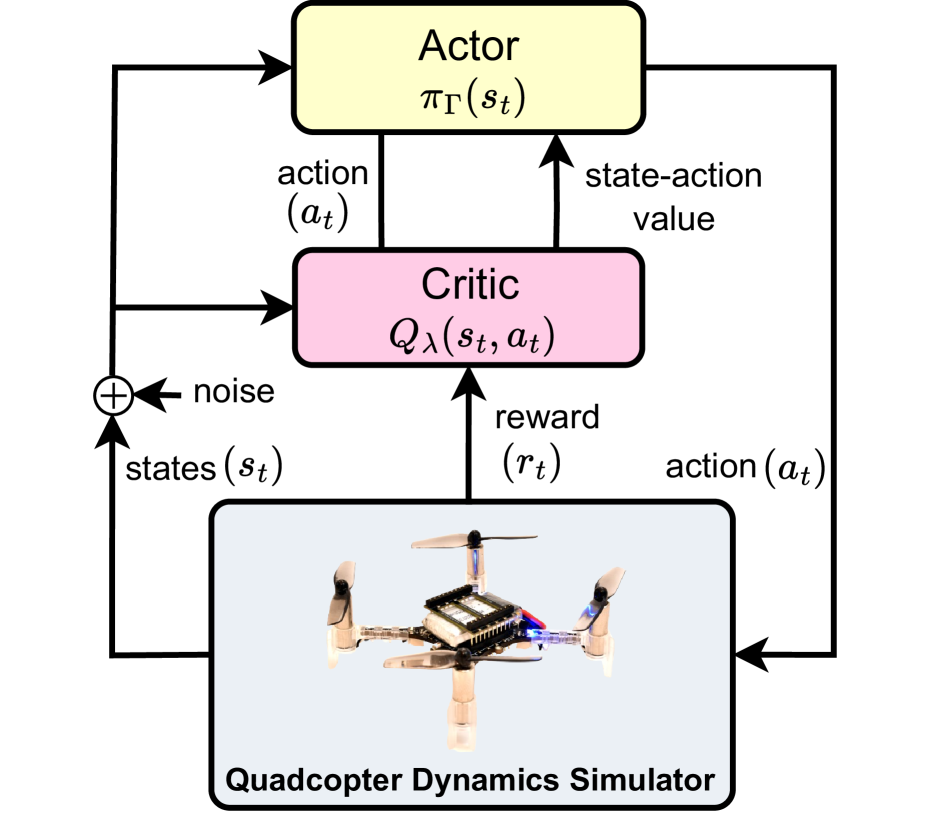
Deep Reinforcement Learning-based Quadcopter Controller: A Practical Approach and Experiments
Truong-Dong Do, Nguyen Xuan Mung, Sung Kyung Hong
Quadcopters have been studied for decades thanks to their maneuverability and capability of operating in a variety of circumstances. However, quadcopters suffer from dynamical nonlinearity, actuator saturation, as well as sensor noise that make it challenging and time consuming to obtain accurate dynamic models and achieve satisfactory control performance. Fortunately, deep reinforcement learning came and has shown significant potential in system modelling and control of autonomous multirotor aerial vehicles, with recent advancements in deployment, performance enhancement, and generalization. In this paper, an end-to-end deep reinforcement learning-based controller for quadcopters is proposed that is secure for real-world implementation, data-efficient, and free of human gain adjustments. First, a novel actor-critic-based architecture is designed to map the robot states directly to the motor outputs. Then, a quadcopter dynamics-based simulator was devised to facilitate the training of the controller policy. Finally, the trained policy is deployed on a real Crazyflie nano quadrotor platform, without any additional fine-tuning process. Experimental results show that the quadcopter exhibits satisfactory performance as it tracks a given complicated trajectory, which demonstrates the effectiveness and feasibility of the proposed method and signifies its capability in filling the simulation-to-reality gap.
Read more6/19/2024