On the Relationship Between Interpretability and Explainability in Machine Learning
2311.11491
0
0
🖼️
Abstract
Interpretability and explainability have gained more and more attention in the field of machine learning as they are crucial when it comes to high-stakes decisions and troubleshooting. Since both provide information about predictors and their decision process, they are often seen as two independent means for one single end. This view has led to a dichotomous literature: explainability techniques designed for complex black-box models, or interpretable approaches ignoring the many explainability tools. In this position paper, we challenge the common idea that interpretability and explainability are substitutes for one another by listing their principal shortcomings and discussing how both of them mitigate the drawbacks of the other. In doing so, we call for a new perspective on interpretability and explainability, and works targeting both topics simultaneously, leveraging each of their respective assets.
Create account to get full access
Overview
- Interpretability and explainability are crucial in high-stakes machine learning decisions and troubleshooting.
- Interpretability and explainability are often seen as independent, leading to a divide in the literature.
- This paper challenges the idea that interpretability and explainability are substitutes, and instead argues they can complement each other.
Plain English Explanation
Machine learning models are being used to make important decisions in fields like healthcare and finance. However, it's often difficult to understand how these complex "black box" models arrive at their predictions. Interpretability and explainability are two related concepts that aim to provide insight into how these models work.
Interpretability refers to the ability to understand the internal logic of a model - for example, which features it is using to make its decisions. Explainability, on the other hand, is about providing post-hoc explanations for a model's outputs, such as highlighting the most important factors contributing to a particular prediction.
Traditionally, these two ideas have been seen as separate approaches. But this paper argues that interpretability and explainability actually complement each other and can be used together to better understand and debug machine learning systems. By leveraging the strengths of both, we can gain a more holistic picture of how these complex models work.
Technical Explanation
This paper challenges the common view that interpretability and explainability are substitutes for one another. The authors argue that while they are distinct concepts, they can in fact work together to provide a more comprehensive understanding of machine learning models.
Interpretability refers to the ability to understand the internal logic and decision-making process of a model. This is often associated with simpler, more transparent "white box" models. Explainability, on the other hand, is about providing post-hoc explanations for the outputs of complex "black box" models, such as highlighting the most important factors contributing to a prediction.
The authors note that the literature on these topics has largely been dichotomous, with researchers focusing on either interpretability or explainability techniques. However, they posit that both perspectives are valuable and can in fact mitigate the shortcomings of the other.
For example, interpretable models may lack the predictive power of more complex black boxes. But explainability techniques can be used to shed light on how these black box models arrive at their predictions. Conversely, while explainability can provide insights into complex models, interpretability is still crucial for understanding the fundamental logic of a system.
The key contribution of this paper is to call for a new, more integrated perspective on interpretability and explainability. The authors argue that research targeting both topics simultaneously, leveraging the strengths of each, could lead to more robust and trustworthy machine learning systems.
Critical Analysis
The authors make a compelling case for why interpretability and explainability should be viewed as complementary rather than competing concepts. By highlighting the limitations of addressing them in isolation, they make a strong argument for a more holistic approach.
That said, the paper does not delve deeply into the specific methods or techniques for achieving this integration. While the high-level idea is clear, more details on how to practically combine interpretability and explainability techniques would have strengthened the paper.
Additionally, the authors could have explored some potential challenges or trade-offs in trying to balance these two objectives. For instance, achieving a high degree of interpretability may come at the cost of model performance, which explainability techniques would then need to reconcile.
Overall, this is a thought-provoking position paper that successfully challenges the prevailing dichotomy in the field. By encouraging researchers to think more expansively about interpretability and explainability, the authors open the door for more innovative approaches to understanding and improving complex machine learning systems.
Conclusion
This paper makes a compelling case for a more integrated approach to interpretability and explainability in machine learning. By highlighting how these two concepts can work together to provide a more comprehensive understanding of model behavior, the authors offer a new perspective that could lead to more robust and trustworthy AI systems.
As machine learning becomes increasingly influential in high-stakes decision-making, the need for interpretable and explainable models will only grow. This paper lays the groundwork for future research that simultaneously addresses both interpretability and explainability, leveraging the unique strengths of each to advance the field as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
Towards a Unified Framework for Evaluating Explanations
Juan D. Pinto, Luc Paquette
0
0
The challenge of creating interpretable models has been taken up by two main research communities: ML researchers primarily focused on lower-level explainability methods that suit the needs of engineers, and HCI researchers who have more heavily emphasized user-centered approaches often based on participatory design methods. This paper reviews how these communities have evaluated interpretability, identifying overlaps and semantic misalignments. We propose moving towards a unified framework of evaluation criteria and lay the groundwork for such a framework by articulating the relationships between existing criteria. We argue that explanations serve as mediators between models and stakeholders, whether for intrinsically interpretable models or opaque black-box models analyzed via post-hoc techniques. We further argue that useful explanations require both faithfulness and intelligibility. Explanation plausibility is a prerequisite for intelligibility, while stability is a prerequisite for explanation faithfulness. We illustrate these criteria, as well as specific evaluation methods, using examples from an ongoing study of an interpretable neural network for predicting a particular learner behavior.
5/24/2024
📊
Interpretability Needs a New Paradigm
Andreas Madsen, Himabindu Lakkaraju, Siva Reddy, Sarath Chandar
0
0
Interpretability is the study of explaining models in understandable terms to humans. At present, interpretability is divided into two paradigms: the intrinsic paradigm, which believes that only models designed to be explained can be explained, and the post-hoc paradigm, which believes that black-box models can be explained. At the core of this debate is how each paradigm ensures its explanations are faithful, i.e., true to the model's behavior. This is important, as false but convincing explanations lead to unsupported confidence in artificial intelligence (AI), which can be dangerous. This paper's position is that we should think about new paradigms while staying vigilant regarding faithfulness. First, by examining the history of paradigms in science, we see that paradigms are constantly evolving. Then, by examining the current paradigms, we can understand their underlying beliefs, the value they bring, and their limitations. Finally, this paper presents 3 emerging paradigms for interpretability. The first paradigm designs models such that faithfulness can be easily measured. Another optimizes models such that explanations become faithful. The last paradigm proposes to develop models that produce both a prediction and an explanation.
5/10/2024
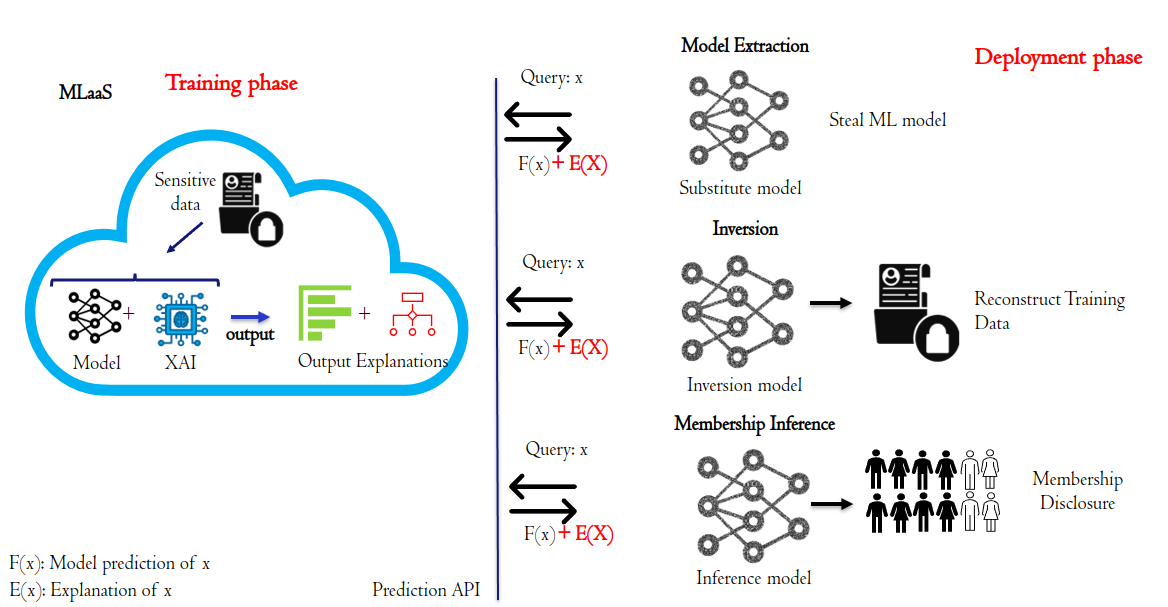
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
0
0
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
6/26/2024
Data Science Principles for Interpretable and Explainable AI
Kris Sankaran
0
0
Society's capacity for algorithmic problem-solving has never been greater. Artificial Intelligence is now applied across more domains than ever, a consequence of powerful abstractions, abundant data, and accessible software. As capabilities have expanded, so have risks, with models often deployed without fully understanding their potential impacts. Interpretable and interactive machine learning aims to make complex models more transparent and controllable, enhancing user agency. This review synthesizes key principles from the growing literature in this field. We first introduce precise vocabulary for discussing interpretability, like the distinction between glass box and explainable algorithms. We then explore connections to classical statistical and design principles, like parsimony and the gulfs of interaction. Basic explainability techniques -- including learned embeddings, integrated gradients, and concept bottlenecks -- are illustrated with a simple case study. We also review criteria for objectively evaluating interpretability approaches. Throughout, we underscore the importance of considering audience goals when designing interactive algorithmic systems. Finally, we outline open challenges and discuss the potential role of data science in addressing them. Code to reproduce all examples can be found at https://go.wisc.edu/3k1ewe.
5/20/2024