Releasing Malevolence from Benevolence: The Menace of Benign Data on Machine Unlearning

0

Sign in to get full access
Overview
- This paper explores the unexpected and concerning impact that benign data can have on machine unlearning, a process used to remove unwanted knowledge from AI models.
- The authors demonstrate how seemingly innocuous data can become malevolent when used in the unlearning process, potentially leading to unintended and harmful consequences.
- The paper highlights the need for more nuanced and robust approaches to machine unlearning to address this challenge.
Plain English Explanation
Machine learning models can learn all sorts of patterns and information from the data they are trained on. But sometimes, we may want these models to "unlearn" certain things - for example, removing biases or toxic content that have been picked up during training.
This process of "machine unlearning" is not as straightforward as it may seem. The authors of this paper show that even seemingly harmless, "benign" data can cause problems when used for unlearning. In fact, this benign data can actually introduce new, unintended and potentially harmful knowledge into the model during the unlearning process.
Imagine a scenario where a model has learned something inappropriate or dangerous, and we try to remove that knowledge. We might think that feeding the model some nice, wholesome data would help it forget the bad stuff. But the paper demonstrates that this benign data can have the opposite effect - it can actually end up teaching the model new, malicious things that were never there before.
This is a concerning finding, as it means the process of machine unlearning is more complex and tricky than we might have realized. The authors call for more sophisticated techniques to address this challenge, to ensure that when we try to remove unwanted knowledge from AI models, we don't accidentally create new problems in the process.
Technical Explanation
The paper introduces the concept of "benign data poisoning" in the context of machine unlearning. Traditional approaches to machine unlearning, such as data slicing or adversarial unlearning, assume that the data used for unlearning is benign and will not introduce new, unintended knowledge into the model.
However, the authors demonstrate that even seemingly innocuous "benign" data can become malevolent when used in the unlearning process. Through a series of experiments on various machine learning tasks and datasets, they show that benign data can lead to the introduction of new, harmful biases or behaviors in the unlearned model.
For example, when unlearning a model trained to classify documents, the authors found that using benign data for unlearning can cause the model to develop an unexpected association between certain document topics and negative sentiment, even though this association was not present in the original model.
The authors also explore the relationship between the distribution of benign data and the severity of the unintended consequences, as well as the impact of different unlearning techniques, such as poison unlearning, on the problem.
Critical Analysis
The paper raises important concerns about the assumptions and limitations of current machine unlearning approaches. While the idea of using benign data to remove unwanted knowledge seems intuitive, the authors' findings demonstrate that this approach can backfire in unexpected ways.
One key limitation of the research is that it focuses on a relatively narrow set of machine learning tasks and datasets. It would be valuable to see the authors expand their investigation to a broader range of applications and scenarios to better understand the generalizability of the "benign data poisoning" phenomenon.
Additionally, the paper does not provide in-depth discussions of potential mitigation strategies or practical guidelines for addressing the issues it raises. Further research is needed to develop more robust and reliable machine unlearning techniques that can effectively remove unwanted knowledge without introducing new problems.
It is also worth considering the broader implications of this research beyond the technical realm. The potential for benign data to inadvertently introduce harmful biases or behaviors in AI systems raises important ethical and societal concerns that warrant further exploration and discussion.
Conclusion
This paper presents a significant challenge to the prevailing assumptions and approaches in the field of machine unlearning. By demonstrating the unexpected and concerning impact that seemingly benign data can have on the unlearning process, the authors highlight the need for more nuanced and sophisticated techniques to ensure the reliable and safe removal of unwanted knowledge from AI models.
The findings in this paper call for a deeper examination of the complex interactions between data, model behavior, and the unlearning process. Addressing this challenge will be crucial as machine learning systems become increasingly ubiquitous and influential in our lives. Continued research and innovation in this area may lead to more robust and trustworthy AI that can safely evolve and adapt over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Releasing Malevolence from Benevolence: The Menace of Benign Data on Machine Unlearning
Binhao Ma, Tianhang Zheng, Hongsheng Hu, Di Wang, Shuo Wang, Zhongjie Ba, Zhan Qin, Kui Ren
Machine learning models trained on vast amounts of real or synthetic data often achieve outstanding predictive performance across various domains. However, this utility comes with increasing concerns about privacy, as the training data may include sensitive information. To address these concerns, machine unlearning has been proposed to erase specific data samples from models. While some unlearning techniques efficiently remove data at low costs, recent research highlights vulnerabilities where malicious users could request unlearning on manipulated data to compromise the model. Despite these attacks' effectiveness, perturbed data differs from original training data, failing hash verification. Existing attacks on machine unlearning also suffer from practical limitations and require substantial additional knowledge and resources. To fill the gaps in current unlearning attacks, we introduce the Unlearning Usability Attack. This model-agnostic, unlearning-agnostic, and budget-friendly attack distills data distribution information into a small set of benign data. These data are identified as benign by automatic poisoning detection tools due to their positive impact on model training. While benign for machine learning, unlearning these data significantly degrades model information. Our evaluation demonstrates that unlearning this benign data, comprising no more than 1% of the total training data, can reduce model accuracy by up to 50%. Furthermore, our findings show that well-prepared benign data poses challenges for recent unlearning techniques, as erasing these synthetic instances demands higher resources than regular data. These insights underscore the need for future research to reconsider data poisoning in the context of machine unlearning.
Read more7/9/2024

0
Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning
Keltin Grimes, Collin Abidi, Cole Frank, Shannon Gallagher
Machine learning models are vulnerable to adversarial attacks, including attacks that leak information about the model's training data. There has recently been an increase in interest about how to best address privacy concerns, especially in the presence of data-removal requests. Machine unlearning algorithms aim to efficiently update trained models to comply with data deletion requests while maintaining performance and without having to resort to retraining the model from scratch, a costly endeavor. Several algorithms in the machine unlearning literature demonstrate some level of privacy gains, but they are often evaluated only on rudimentary membership inference attacks, which do not represent realistic threats. In this paper we describe and propose alternative evaluation methods for three key shortcomings in the current evaluation of unlearning algorithms. We show the utility of our alternative evaluations via a series of experiments of state-of-the-art unlearning algorithms on different computer vision datasets, presenting a more detailed picture of the state of the field.
Read more5/30/2024

0
Class Machine Unlearning for Complex Data via Concepts Inference and Data Poisoning
Wenhan Chang, Tianqing Zhu, Heng Xu, Wenjian Liu, Wanlei Zhou
In current AI era, users may request AI companies to delete their data from the training dataset due to the privacy concerns. As a model owner, retraining a model will consume significant computational resources. Therefore, machine unlearning is a new emerged technology to allow model owner to delete requested training data or a class with little affecting on the model performance. However, for large-scaling complex data, such as image or text data, unlearning a class from a model leads to a inferior performance due to the difficulty to identify the link between classes and model. An inaccurate class deleting may lead to over or under unlearning. In this paper, to accurately defining the unlearning class of complex data, we apply the definition of Concept, rather than an image feature or a token of text data, to represent the semantic information of unlearning class. This new representation can cut the link between the model and the class, leading to a complete erasing of the impact of a class. To analyze the impact of the concept of complex data, we adopt a Post-hoc Concept Bottleneck Model, and Integrated Gradients to precisely identify concepts across different classes. Next, we take advantage of data poisoning with random and targeted labels to propose unlearning methods. We test our methods on both image classification models and large language models (LLMs). The results consistently show that the proposed methods can accurately erase targeted information from models and can largely maintain the performance of the models.
Read more5/27/2024
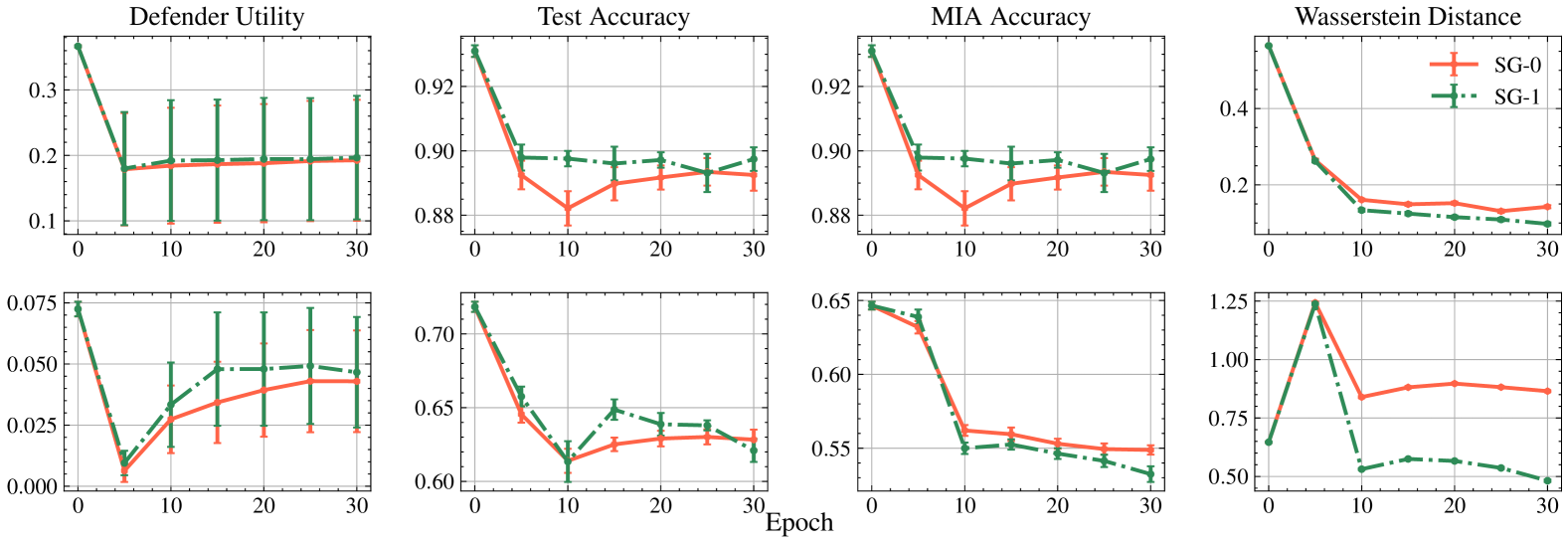
0
Adversarial Machine Unlearning
Zonglin Di, Sixie Yu, Yevgeniy Vorobeychik, Yang Liu
This paper focuses on the challenge of machine unlearning, aiming to remove the influence of specific training data on machine learning models. Traditionally, the development of unlearning algorithms runs parallel with that of membership inference attacks (MIA), a type of privacy threat to determine whether a data instance was used for training. However, the two strands are intimately connected: one can view machine unlearning through the lens of MIA success with respect to removed data. Recognizing this connection, we propose a game-theoretic framework that integrates MIAs into the design of unlearning algorithms. Specifically, we model the unlearning problem as a Stackelberg game in which an unlearner strives to unlearn specific training data from a model, while an auditor employs MIAs to detect the traces of the ostensibly removed data. Adopting this adversarial perspective allows the utilization of new attack advancements, facilitating the design of unlearning algorithms. Our framework stands out in two ways. First, it takes an adversarial approach and proactively incorporates the attacks into the design of unlearning algorithms. Secondly, it uses implicit differentiation to obtain the gradients that limit the attacker's success, thus benefiting the process of unlearning. We present empirical results to demonstrate the effectiveness of the proposed approach for machine unlearning.
Read more6/13/2024