The Remarkable Robustness of LLMs: Stages of Inference?
2406.19384
2
0
Abstract
We demonstrate and investigate the remarkable robustness of Large Language Models by deleting and swapping adjacent layers. We find that deleting and swapping interventions retain 72-95% of the original model's prediction accuracy without fine-tuning, whereas models with more layers exhibit more robustness. Based on the results of the layer-wise intervention and further experiments, we hypothesize the existence of four universal stages of inference across eight different models: detokenization, feature engineering, prediction ensembling, and residual sharpening. The first stage integrates local information, lifting raw token representations into higher-level contextual representations. Next is the iterative refinement of task and entity-specific features. Then, the second half of the model begins with a phase transition, where hidden representations align more with the vocabulary space due to specialized model components. Finally, the last layer sharpens the following token distribution by eliminating obsolete features that add noise to the prediction.
Create account to get full access
Overview
- Explores the remarkable robustness of large language models (LLMs) and the potential stages involved in their inference process
- Investigates how different layers of LLMs contribute to the model's overall performance and capabilities
- Provides insights into the emergence of high-dimensional abstract representations in language transformers
Plain English Explanation
This paper examines the impressive robustness and capabilities of large language models (LLMs), which are AI systems that can generate human-like text. The researchers explore the different stages or layers that may be involved in the inference process of these models, meaning the steps they take to understand and generate language.
The paper investigates how the various layers or components of an LLM contribute to its overall performance. For example, some layers may be more important than others for certain tasks. The researchers also look at how LLMs can correct speech or language and become more efficient at inference.
Additionally, the paper examines the emergence of high-dimensional abstract representations in language transformers, which are a type of LLM. This means the models develop sophisticated and complex ways of understanding and representing language that go beyond simple patterns or rules.
Overall, the research aims to provide a deeper understanding of how these powerful AI language models work and the various stages or components involved in their ability to process and generate human-like text.
Technical Explanation
The paper investigates the remarkable robustness and capabilities of large language models (LLMs), which are AI systems that can generate human-like text. The researchers explore the potential stages or layers involved in the inference process of these models, meaning the steps they take to understand and generate language.
The study examines how the different layers or components of an LLM contribute to its overall performance. For example, some layers may be more important than others for certain tasks, and the models can correct speech or language and become more efficient at inference.
Additionally, the paper investigates the emergence of high-dimensional abstract representations in language transformers, a type of LLM. This means the models develop sophisticated and complex ways of understanding and representing language that go beyond simple patterns or rules.
Critical Analysis
The paper provides valuable insights into the inner workings and capabilities of large language models, but it also acknowledges certain caveats and areas for further research. For example, the researchers note that their analysis of model layers and inference stages is based on specific experimental setups and architectures, and the findings may not universally apply to all LLMs.
Additionally, while the paper explores the emergence of high-dimensional abstract representations in language transformers, it does not delve deeply into the specific mechanisms or implications of this phenomenon. Further research could investigate the nature and significance of these abstract representations and how they contribute to the overall capabilities of LLMs.
Overall, the paper presents a thoughtful and nuanced examination of LLM robustness and inference stages, but there is still much to be explored in this rapidly evolving field of AI.
Conclusion
This paper provides valuable insights into the remarkable robustness and capabilities of large language models (LLMs). By investigating the potential stages or layers involved in the inference process, the researchers offer a deeper understanding of how these powerful AI systems process and generate human-like text.
The findings suggest that the different components of an LLM play varying roles in its overall performance, and the models can demonstrate sophisticated abilities, such as correcting speech or language and becoming more efficient at inference. Additionally, the paper examines the emergence of high-dimensional abstract representations in language transformers, indicating the models' capacity for complex and nuanced language understanding.
These insights have important implications for the continued development and application of LLMs in a wide range of domains, from natural language processing to creative writing and beyond. As the field of AI continues to advance, further research in this area could yield even more remarkable discoveries about the inner workings and potential of these remarkable language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Not all Layers of LLMs are Necessary during Inference
Siqi Fan, Xin Jiang, Xiang Li, Xuying Meng, Peng Han, Shuo Shang, Aixin Sun, Yequan Wang, Zhongyuan Wang
0
0
The inference phase of Large Language Models (LLMs) is very expensive. An ideal inference stage of LLMs could utilize fewer computational resources while still maintaining its capabilities (e.g., generalization and in-context learning ability). In this paper, we try to answer the question, During LLM inference, can we use shallow layers for easy instances; and deep layers for hard ones? To answer this question, we first indicate that Not all Layers are Necessary during Inference by statistically analyzing the activated layers across tasks. Then, we propose a simple algorithm named AdaInfer to determine the inference termination moment based on the input instance adaptively. More importantly, AdaInfer does not alter LLM parameters and maintains generalizability across tasks. Experiments on well-known LLMs (i.e., Llama2 series and OPT) show that AdaInfer saves an average of 14.8% of computational resources, even up to 50% on sentiment tasks, while maintaining comparable performance. Additionally, this method is orthogonal to other model acceleration techniques, potentially boosting inference efficiency further.
4/16/2024

Multi-stage Large Language Model Correction for Speech Recognition
Jie Pu, Thai-Son Nguyen, Sebastian Stuker
0
0
In this paper, we investigate the usage of large language models (LLMs) to improve the performance of competitive speech recognition systems. Different from previous LLM-based ASR error correction methods, we propose a novel multi-stage approach that utilizes uncertainty estimation of ASR outputs and reasoning capability of LLMs. Specifically, the proposed approach has two stages: the first stage is about ASR uncertainty estimation and exploits N-best list hypotheses to identify less reliable transcriptions; The second stage works on these identified transcriptions and performs LLM-based corrections. This correction task is formulated as a multi-step rule-based LLM reasoning process, which uses explicitly written rules in prompts to decompose the task into concrete reasoning steps. Our experimental results demonstrate the effectiveness of the proposed method by showing 10% ~ 20% relative improvement in WER over competitive ASR systems -- across multiple test domains and in zero-shot settings.
6/18/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
Fantastic Semantics and Where to Find Them: Investigating Which Layers of Generative LLMs Reflect Lexical Semantics
Zhu Liu, Cunliang Kong, Ying Liu, Maosong Sun
0
0
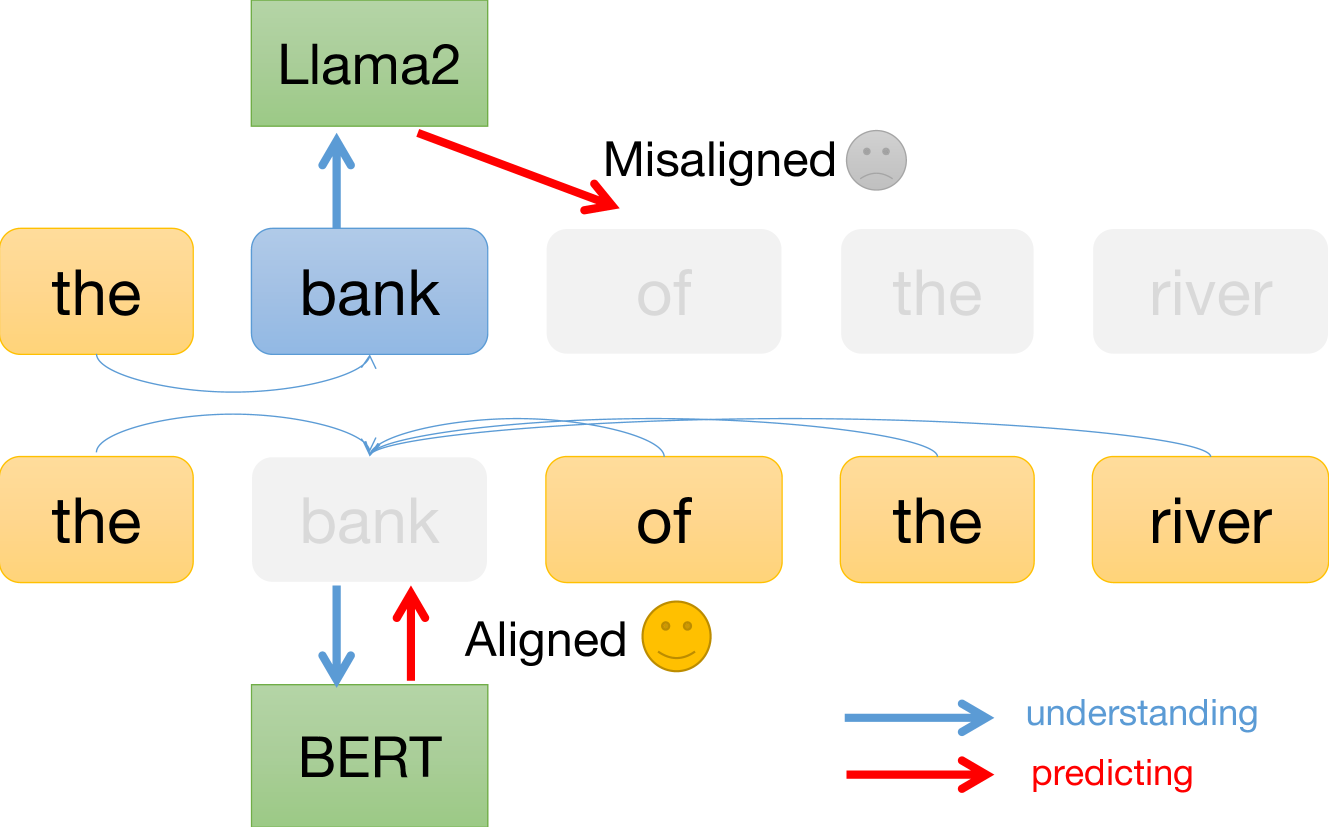
Large language models have achieved remarkable success in general language understanding tasks. However, as a family of generative methods with the objective of next token prediction, the semantic evolution with the depth of these models are not fully explored, unlike their predecessors, such as BERT-like architectures. In this paper, we specifically investigate the bottom-up evolution of lexical semantics for a popular LLM, namely Llama2, by probing its hidden states at the end of each layer using a contextualized word identification task. Our experiments show that the representations in lower layers encode lexical semantics, while the higher layers, with weaker semantic induction, are responsible for prediction. This is in contrast to models with discriminative objectives, such as mask language modeling, where the higher layers obtain better lexical semantics. The conclusion is further supported by the monotonic increase in performance via the hidden states for the last meaningless symbols, such as punctuation, in the prompting strategy. Our codes are available at https://github.com/RyanLiut/LLM_LexSem.
6/11/2024