Fantastic Semantics and Where to Find Them: Investigating Which Layers of Generative LLMs Reflect Lexical Semantics
2403.01509
0
0
Abstract
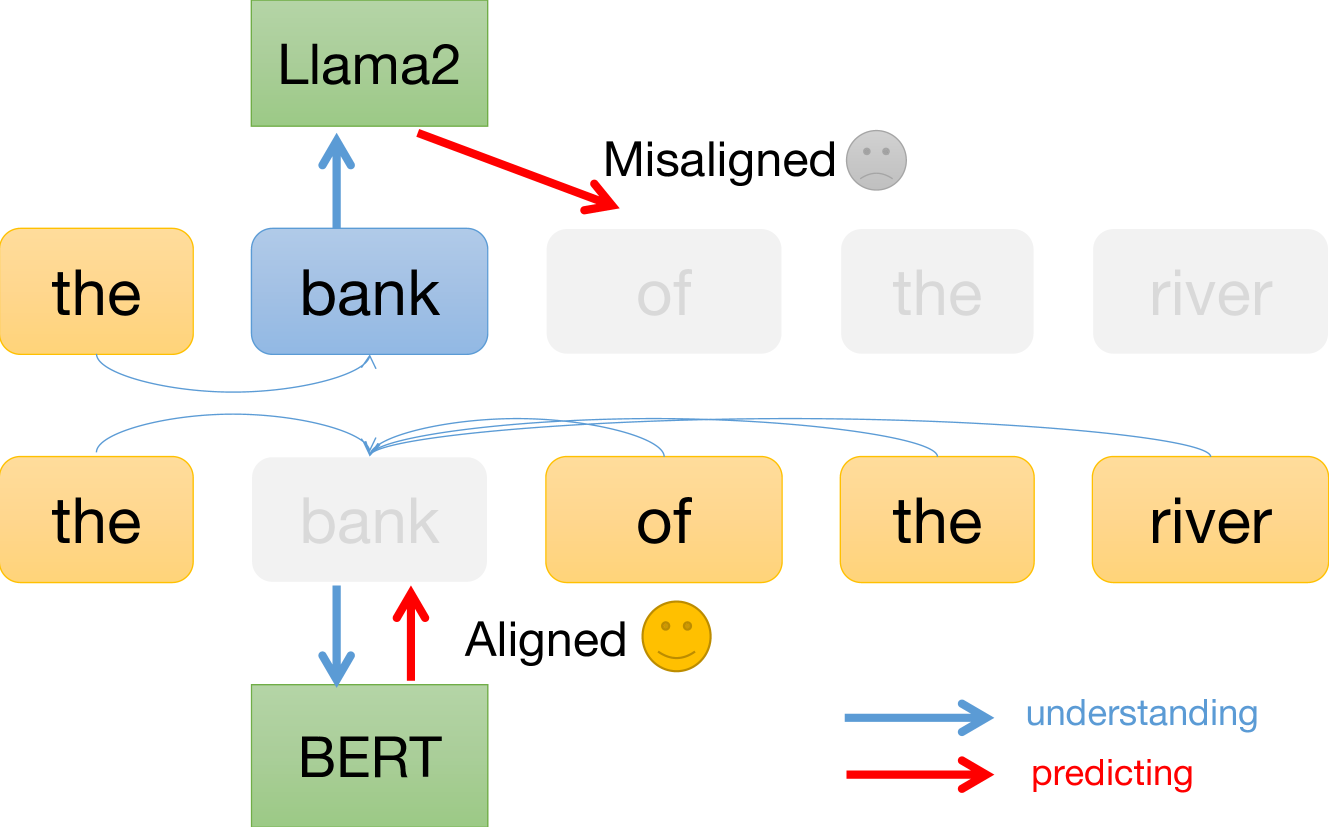
Large language models have achieved remarkable success in general language understanding tasks. However, as a family of generative methods with the objective of next token prediction, the semantic evolution with the depth of these models are not fully explored, unlike their predecessors, such as BERT-like architectures. In this paper, we specifically investigate the bottom-up evolution of lexical semantics for a popular LLM, namely Llama2, by probing its hidden states at the end of each layer using a contextualized word identification task. Our experiments show that the representations in lower layers encode lexical semantics, while the higher layers, with weaker semantic induction, are responsible for prediction. This is in contrast to models with discriminative objectives, such as mask language modeling, where the higher layers obtain better lexical semantics. The conclusion is further supported by the monotonic increase in performance via the hidden states for the last meaningless symbols, such as punctuation, in the prompting strategy. Our codes are available at https://github.com/RyanLiut/LLM_LexSem.
Create account to get full access
Overview
- This paper investigates which layers of generative large language models (LLMs) reflect lexical semantics, or the meanings of individual words.
- The researchers use a variety of techniques to probe the semantic representations in different layers of LLMs, including analyzing the performance on lexical tasks and visualizing the representations.
- The findings provide insights into the nature of semantic information captured by LLMs and have implications for understanding and interpreting these powerful language models.
Plain English Explanation
The paper looks at how well different parts, or "layers," of large language models (LLMs) - powerful AI systems that can generate human-like text - are able to capture the meanings of individual words, known as lexical semantics. The researchers use various analysis methods to investigate which layers of the LLMs contain the most information about word meanings.
This is an important question because these LLMs have become very good at generating fluent, human-like text, but it's not always clear what they actually "understand" about the language they're producing. By examining how the models represent word meanings, the researchers can get a better sense of the inner workings of these AI systems and what kinds of semantic information they are able to learn.
The findings from this paper provide insights into the nature of the semantic knowledge that gets encoded in different parts of LLMs, which can help us interpret and understand these powerful language models better. This could be useful for applications like improving interpretability of LLMs, understanding uncommon word meanings, and developing more comprehensive semantic representations in language models.
Technical Explanation
The paper investigates which layers of generative large language models (LLMs) best reflect lexical semantics - the meanings of individual words. The researchers use a variety of techniques to probe the semantic representations in different layers of LLMs, including:
- Evaluating the performance of individual layers on lexical tasks like word similarity and word sense disambiguation.
- Visualizing the representations of words in the different layers using techniques like t-SNE.
- Analyzing the degree to which the representations in each layer can be used to predict human judgments of word similarity.
The results suggest that the lower and middle layers of the LLMs tend to capture more detailed, fine-grained lexical semantic information, while the higher layers focus more on higher-level, contextual semantics. The researchers found that the specific patterns varied across different LLM architectures.
These findings provide insights into the nature of the semantic information that gets encoded in the internal representations of LLMs. This can help improve our understanding of how these powerful language models work under the hood and how we can best interpret and utilize their capabilities, as discussed in related work on interpreting LLM hidden states and disentangling LLM latent spaces.
Critical Analysis
The paper provides a thorough and rigorous investigation of the relationship between LLM layers and lexical semantics. The researchers use a diverse set of analysis techniques, which helps strengthen the credibility of their findings.
However, one potential limitation is that the study focuses primarily on generative LLMs, and the results may not fully generalize to other types of language models, such as discriminative models used for tasks like text classification. Further research could explore the semantic representations in a wider range of LLM architectures and applications.
Additionally, the paper does not delve into the potential implications of these findings for real-world use cases. More discussion on how the insights from this research could inform the development of more interpretable and semantically-grounded language models would be valuable.
Overall, this paper makes an important contribution to our understanding of the inner workings of LLMs and sets the stage for future work on improving the semantic representations in language models.
Conclusion
This paper provides a detailed investigation into the relationship between the layers of generative large language models (LLMs) and the representation of lexical semantics, or the meanings of individual words. The researchers use a variety of techniques to probe the semantic information encoded in different parts of the LLM architectures, finding that lower and middle layers tend to capture more fine-grained lexical semantics, while higher layers focus more on contextual, higher-level semantics.
These insights into the nature of semantic knowledge in LLMs can help us better interpret and understand the inner workings of these powerful language models, which have become central to many natural language processing applications. The findings set the stage for further research on developing more semantically-grounded and interpretable language models that can more effectively capture and represent the nuances of human language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Analyzing the Role of Semantic Representations in the Era of Large Language Models
Zhijing Jin, Yuen Chen, Fernando Gonzalez, Jiarui Liu, Jiayi Zhang, Julian Michael, Bernhard Scholkopf, Mona Diab
0
0
Traditionally, natural language processing (NLP) models often use a rich set of features created by linguistic expertise, such as semantic representations. However, in the era of large language models (LLMs), more and more tasks are turned into generic, end-to-end sequence generation problems. In this paper, we investigate the question: what is the role of semantic representations in the era of LLMs? Specifically, we investigate the effect of Abstract Meaning Representation (AMR) across five diverse NLP tasks. We propose an AMR-driven chain-of-thought prompting method, which we call AMRCoT, and find that it generally hurts performance more than it helps. To investigate what AMR may have to offer on these tasks, we conduct a series of analysis experiments. We find that it is difficult to predict which input examples AMR may help or hurt on, but errors tend to arise with multi-word expressions, named entities, and in the final inference step where the LLM must connect its reasoning over the AMR to its prediction. We recommend focusing on these areas for future work in semantic representations for LLMs. Our code: https://github.com/causalNLP/amr_llm.
5/3/2024
The Remarkable Robustness of LLMs: Stages of Inference?
Vedang Lad, Wes Gurnee, Max Tegmark
0
0
We demonstrate and investigate the remarkable robustness of Large Language Models by deleting and swapping adjacent layers. We find that deleting and swapping interventions retain 72-95% of the original model's prediction accuracy without fine-tuning, whereas models with more layers exhibit more robustness. Based on the results of the layer-wise intervention and further experiments, we hypothesize the existence of four universal stages of inference across eight different models: detokenization, feature engineering, prediction ensembling, and residual sharpening. The first stage integrates local information, lifting raw token representations into higher-level contextual representations. Next is the iterative refinement of task and entity-specific features. Then, the second half of the model begins with a phase transition, where hidden representations align more with the vocabulary space due to specialized model components. Finally, the last layer sharpens the following token distribution by eliminating obsolete features that add noise to the prediction.
6/28/2024

Can large language models understand uncommon meanings of common words?
Jinyang Wu, Feihu Che, Xinxin Zheng, Shuai Zhang, Ruihan Jin, Shuai Nie, Pengpeng Shao, Jianhua Tao
0
0
Large language models (LLMs) like ChatGPT have shown significant advancements across diverse natural language understanding (NLU) tasks, including intelligent dialogue and autonomous agents. Yet, lacking widely acknowledged testing mechanisms, answering `whether LLMs are stochastic parrots or genuinely comprehend the world' remains unclear, fostering numerous studies and sparking heated debates. Prevailing research mainly focuses on surface-level NLU, neglecting fine-grained explorations. However, such explorations are crucial for understanding their unique comprehension mechanisms, aligning with human cognition, and finally enhancing LLMs' general NLU capacities. To address this gap, our study delves into LLMs' nuanced semantic comprehension capabilities, particularly regarding common words with uncommon meanings. The idea stems from foundational principles of human communication within psychology, which underscore accurate shared understandings of word semantics. Specifically, this paper presents the innovative construction of a Lexical Semantic Comprehension (LeSC) dataset with novel evaluation metrics, the first benchmark encompassing both fine-grained and cross-lingual dimensions. Introducing models of both open-source and closed-source, varied scales and architectures, our extensive empirical experiments demonstrate the inferior performance of existing models in this basic lexical-meaning understanding task. Notably, even the state-of-the-art LLMs GPT-4 and GPT-3.5 lag behind 16-year-old humans by 3.9% and 22.3%, respectively. Additionally, multiple advanced prompting techniques and retrieval-augmented generation are also introduced to help alleviate this trouble, yet limitations persist. By highlighting the above critical shortcomings, this research motivates further investigation and offers novel insights for developing more intelligent LLMs.
5/10/2024
💬
Reinterpreting 'the Company a Word Keeps': Towards Explainable and Ontologically Grounded Language Models
Walid S. Saba
0
0
We argue that the relative success of large language models (LLMs) is not a reflection on the symbolic vs. subsymbolic debate but a reflection on employing a successful bottom-up strategy of a reverse engineering of language at scale. However, and due to their subsymbolic nature whatever knowledge these systems acquire about language will always be buried in millions of weights none of which is meaningful on its own, rendering such systems utterly unexplainable. Furthermore, and due to their stochastic nature, LLMs will often fail in making the correct inferences in various linguistic contexts that require reasoning in intensional, temporal, or modal contexts. To remedy these shortcomings we suggest employing the same successful bottom-up strategy employed in LLMs but in a symbolic setting, resulting in explainable, language-agnostic, and ontologically grounded language models.
6/12/2024