Not all Layers of LLMs are Necessary during Inference
2403.02181
0
0
Abstract
The inference phase of Large Language Models (LLMs) is very expensive. An ideal inference stage of LLMs could utilize fewer computational resources while still maintaining its capabilities (e.g., generalization and in-context learning ability). In this paper, we try to answer the question, During LLM inference, can we use shallow layers for easy instances; and deep layers for hard ones? To answer this question, we first indicate that Not all Layers are Necessary during Inference by statistically analyzing the activated layers across tasks. Then, we propose a simple algorithm named AdaInfer to determine the inference termination moment based on the input instance adaptively. More importantly, AdaInfer does not alter LLM parameters and maintains generalizability across tasks. Experiments on well-known LLMs (i.e., Llama2 series and OPT) show that AdaInfer saves an average of 14.8% of computational resources, even up to 50% on sentiment tasks, while maintaining comparable performance. Additionally, this method is orthogonal to other model acceleration techniques, potentially boosting inference efficiency further.
Create account to get full access
Overview
- The paper examines the efficiency of large language models (LLMs) during inference, investigating whether all layers of the model are necessary to achieve good performance.
- The researchers analyze the computational cost and performance trade-offs of selectively using a subset of the model's layers.
- The findings suggest that not all layers of LLMs are required during inference, and that significant efficiency gains can be achieved by using only a subset of the layers.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have revolutionized natural language processing, but they can be computationally expensive to use. This paper explores whether all the layers in these models are actually necessary to get good results.
The researchers took a close look at the inner workings of LLMs and found that you don't need to use the full model to get accurate predictions. In fact, you can get similar performance by only using a subset of the model's layers. This could lead to significant efficiency gains, allowing LLMs to run faster and use less computing power.
It's kind of like a car - you don't need all the gears to get from point A to point B. By selectively using just the essential components, you can make the car (or the language model) more efficient without sacrificing too much in terms of performance.
The key insight is that not all the layers in an LLM are equally important. Some layers are more critical for producing accurate results than others. By identifying and using only the most essential layers, you can streamline the model and make it run more smoothly.
This research could have important implications for deploying LLMs in real-world applications, where efficiency and cost are major concerns. If you can get the same results from a smaller, lighter version of the model, that could open up new use cases and make these powerful AI systems more accessible.
Technical Explanation
The paper begins by providing a high-level overview of the building blocks of LLMs, including the input embedding, transformer layers, and output layers. These components work together to process natural language inputs and generate relevant outputs.
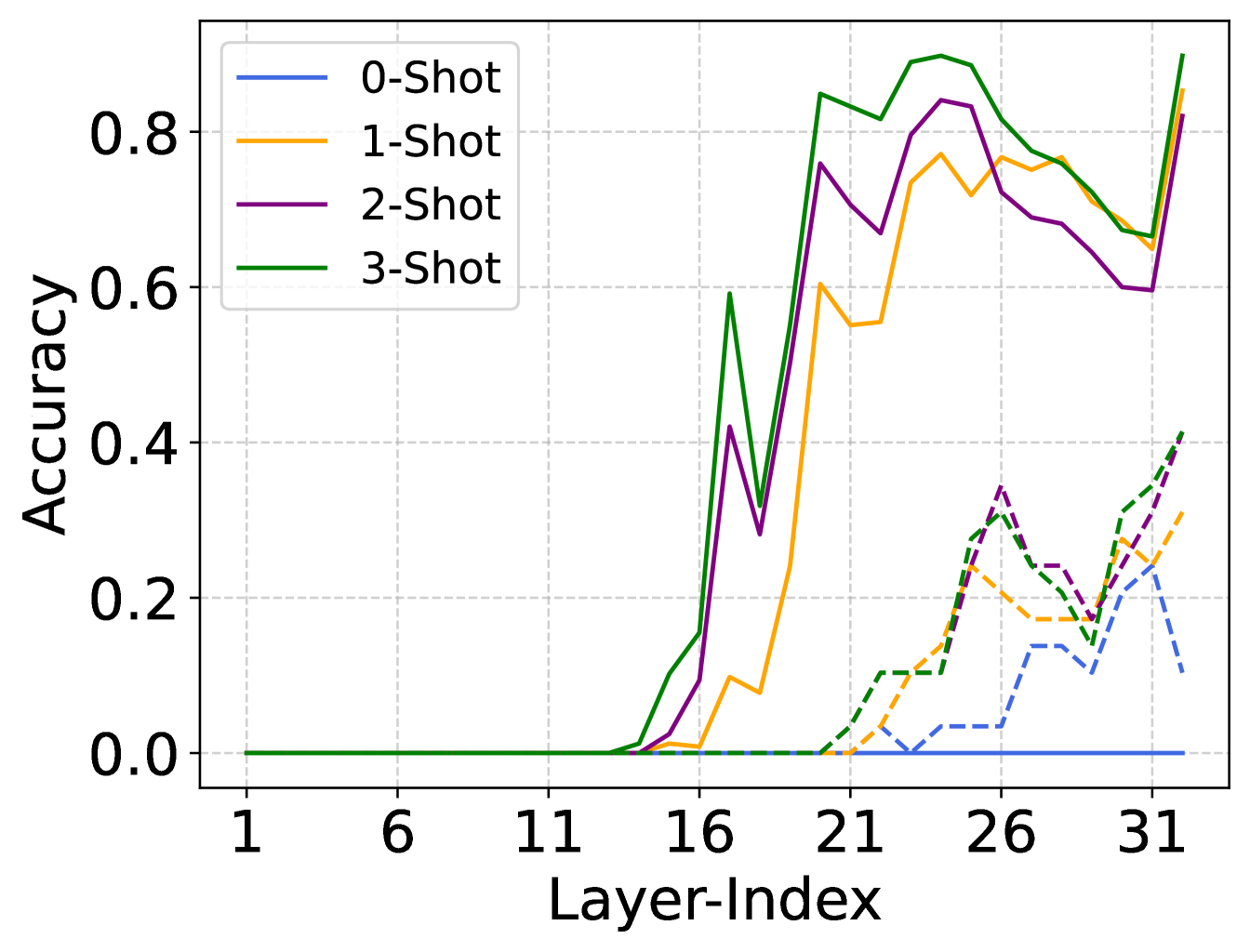
The researchers then dive into an efficiency analysis of LLM inference, examining the computational cost and performance trade-offs of selectively using a subset of the model's layers. They find that not all layers contribute equally to the final output, and that significant efficiency gains can be achieved by using only the most essential layers.
Through a series of experiments, the authors demonstrate that simple linguistic inferences can be accurately made using a much smaller number of layers than the full model. This suggests that the later layers of the LLM may be redundant or less critical for certain tasks.
The findings have important implications for making LLMs more energy-efficient and reducing their computational footprint, which is crucial for deploying these models in resource-constrained environments or at scale.
Critical Analysis
The paper provides a compelling analysis of LLM efficiency, but it does not explore the potential downsides or limitations of this approach. For example, the researchers do not investigate whether selectively using a subset of layers could impact the model's general capabilities or its ability to handle more complex language tasks.
Additionally, the paper does not address the challenge of identifying the most critical layers for a given task or application. Determining the optimal layer configuration may require additional research and could vary depending on the specific use case.
Further work is needed to fully understand the trade-offs and potential risks of this layer-pruning approach. It would be valuable to explore how the technique performs on a wider range of language tasks, as well as to investigate its impact on the model's robustness and generalization abilities.
Conclusion
This paper presents an insightful exploration of the efficiency of large language models, demonstrating that not all layers are necessary for accurate inference. By selectively using a subset of the model's layers, significant computational savings can be achieved without sacrificing too much in terms of performance.
These findings have important implications for the deployment of LLMs in real-world applications, where efficiency and cost are critical concerns. The ability to streamline these powerful AI systems could open up new use cases and make them more accessible to a wider range of users and industries.
While further research is needed to fully understand the trade-offs and limitations of this approach, the paper provides a valuable contribution to the ongoing effort to make large language models more energy-efficient and cost-effective.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!The Remarkable Robustness of LLMs: Stages of Inference?
Vedang Lad, Wes Gurnee, Max Tegmark
0
0
We demonstrate and investigate the remarkable robustness of Large Language Models by deleting and swapping adjacent layers. We find that deleting and swapping interventions retain 72-95% of the original model's prediction accuracy without fine-tuning, whereas models with more layers exhibit more robustness. Based on the results of the layer-wise intervention and further experiments, we hypothesize the existence of four universal stages of inference across eight different models: detokenization, feature engineering, prediction ensembling, and residual sharpening. The first stage integrates local information, lifting raw token representations into higher-level contextual representations. Next is the iterative refinement of task and entity-specific features. Then, the second half of the model begins with a phase transition, where hidden representations align more with the vocabulary space due to specialized model components. Finally, the last layer sharpens the following token distribution by eliminating obsolete features that add noise to the prediction.
6/28/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
6/11/2024
🤯
Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed A Aly, Beidi Chen, Carole-Jean Wu
0
0
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
4/30/2024