RepEval: Effective Text Evaluation with LLM Representation

0
✅
Sign in to get full access
Overview
- Existing automatic evaluation metrics for generated texts often have limited capabilities, making it difficult to meet the evaluation requirements of the rapidly expanding applications of large language models (LLMs).
- This study introduces RepEval, a new metric that leverages the projection of LLM representations for evaluation.
- RepEval requires minimal sample pairs for training and can easily transition to various tasks through simple prompt modifications.
- Results on ten datasets across three tasks demonstrate the high effectiveness of RepEval, which exhibits stronger correlations with human judgments compared to previous metrics, even outperforming GPT-4.
Plain English Explanation
Automatic evaluation metrics are tools that help assess the quality of text generated by AI systems, such as large language models (LLMs). These metrics play a crucial role in the field of natural language generation (NLG), especially as LLMs continue to grow in their capabilities.
However, the existing evaluation metrics often have limitations, as they are typically designed for specific scenarios. This makes it challenging to use them effectively as LLMs are applied to an expanding range of tasks.
To address this issue, the researchers in this study have developed a new metric called RepEval. RepEval works by leveraging the internal representations, or "projections," of LLMs to assess the quality of generated text. One of the key advantages of RepEval is that it requires only a minimal amount of sample pairs for training, and it can be easily adapted to different tasks by modifying the prompts used.
The researchers tested RepEval on ten datasets across three different tasks and found that it outperformed previous evaluation metrics, including GPT-4, in terms of correlation with human judgments of text quality. This suggests that the information about text quality embedded within LLM representations is rich and can be effectively leveraged to develop new and improved evaluation metrics.
Technical Explanation
The study introduces RepEval, a new automatic evaluation metric for generated texts that leverages the projection of LLM representations. Unlike previous metrics, which are often limited to specific scenarios, RepEval is designed to be more flexible and adaptable to a wider range of tasks.
The key innovation of RepEval is its ability to extract and utilize the information about text quality that is encoded within the internal representations of LLMs. The researchers hypothesized that these representations contain rich information that can be effectively leveraged for evaluation purposes.
To test this hypothesis, the researchers conducted experiments on ten datasets across three different tasks: open-ended generation, multi-agent discussion, and mathematical reasoning. They compared the performance of RepEval to that of several established evaluation metrics, including METEOR and BLEU.
The results of the experiments demonstrated the high effectiveness of RepEval, which exhibited stronger correlations with human judgments of text quality compared to the existing metrics. In some cases, RepEval even outperformed the powerful GPT-4 model in terms of evaluation accuracy.
These findings suggest that the information about text quality embedded within LLM representations is indeed rich and can be leveraged to develop new and more effective evaluation metrics. The researchers believe that their work offers valuable insights for the ongoing efforts to improve automatic evaluation in the field of natural language generation.
Critical Analysis
The study presents a promising new approach to automatic text evaluation, but it is important to consider some potential limitations and areas for further research.
One potential concern is the reliance on LLM representations, which can be sensitive to factors like model architecture, training data, and fine-tuning. It's possible that the performance of RepEval may vary depending on the specific LLM used, and more research is needed to understand the extent of this dependence.
Additionally, the study only tested RepEval on a limited set of tasks and datasets. While the results are impressive, it would be valuable to explore the metric's performance on a wider range of applications, including more domain-specific and specialized tasks.
Another area for further investigation is the interpretability of RepEval's evaluation process. Understanding the specific aspects of text quality that the metric is capturing could help researchers develop even more targeted and effective evaluation approaches.
Despite these potential limitations, the study's findings highlight the rich information about text quality that is encoded within LLM representations. This insight opens up new avenues for research and development in the field of automatic text evaluation, which is crucial for the continued advancement of natural language generation technologies.
Conclusion
This study introduces RepEval, a new automatic evaluation metric that leverages the projection of LLM representations to assess the quality of generated texts. The key innovation of RepEval is its ability to effectively capture the rich information about text quality embedded within LLM representations, allowing it to outperform previous metrics, including GPT-4, in terms of correlation with human judgments.
The study's findings underscore the potential of LLM representations as a valuable source of information for the development of new and more effective evaluation metrics. This work offers important insights that can inform ongoing efforts to improve automatic text evaluation, a critical component of the rapidly evolving field of natural language generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
RepEval: Effective Text Evaluation with LLM Representation
Shuqian Sheng, Yi Xu, Tianhang Zhang, Zanwei Shen, Luoyi Fu, Jiaxin Ding, Lei Zhou, Xinbing Wang, Chenghu Zhou
Automatic evaluation metrics for generated texts play an important role in the NLG field, especially with the rapid growth of LLMs. However, existing metrics are often limited to specific scenarios, making it challenging to meet the evaluation requirements of expanding LLM applications. Therefore, there is a demand for new, flexible, and effective metrics. In this study, we introduce RepEval, the first metric leveraging the projection of LLM representations for evaluation. RepEval requires minimal sample pairs for training, and through simple prompt modifications, it can easily transition to various tasks. Results on ten datasets from three tasks demonstrate the high effectiveness of our method, which exhibits stronger correlations with human judgments compared to previous metrics, even outperforming GPT-4. Our work underscores the richness of information regarding text quality embedded within LLM representations, offering insights for the development of new metrics.
Read more5/1/2024
0
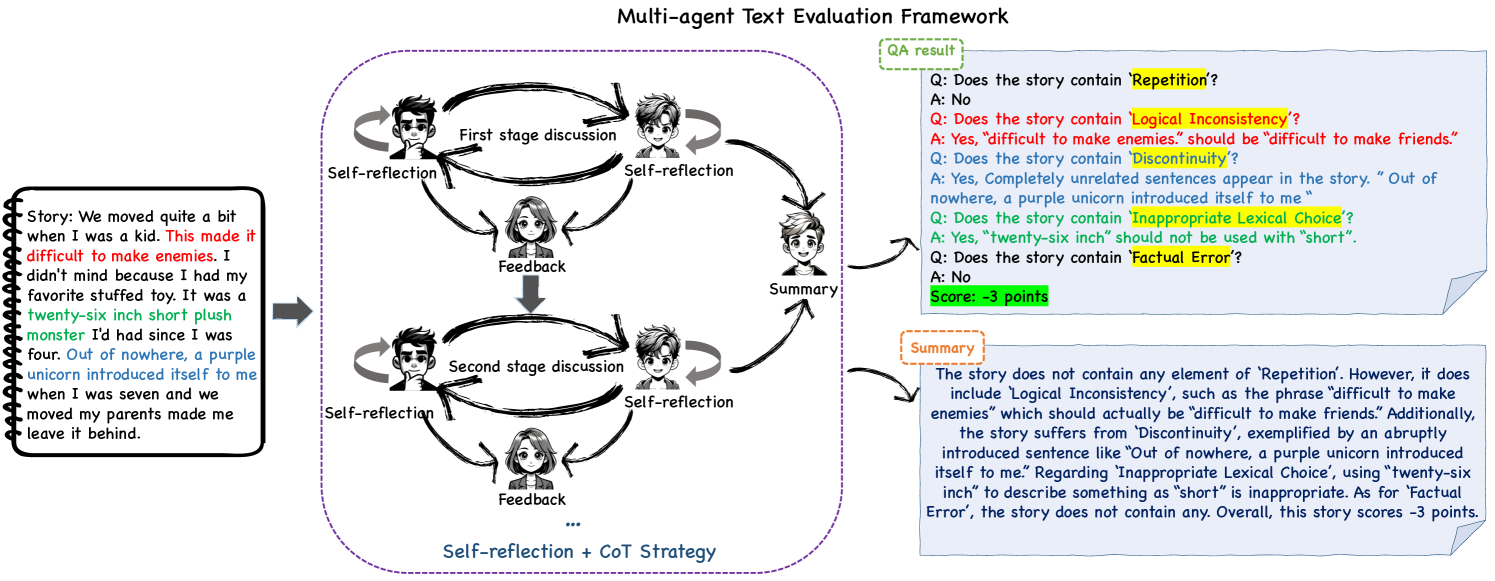
MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
Yu Li, Shenyu Zhang, Rui Wu, Xiutian Huang, Yongrui Chen, Wenhao Xu, Guilin Qi, Dehai Min
Recent advancements in generative Large Language Models(LLMs) have been remarkable, however, the quality of the text generated by these models often reveals persistent issues. Evaluating the quality of text generated by these models, especially in open-ended text, has consistently presented a significant challenge. Addressing this, recent work has explored the possibility of using LLMs as evaluators. While using a single LLM as an evaluation agent shows potential, it is filled with significant uncertainty and instability. To address these issues, we propose the MATEval: A Multi-Agent Text Evaluation framework where all agents are played by LLMs like GPT-4. The MATEval framework emulates human collaborative discussion methods, integrating multiple agents' interactions to evaluate open-ended text. Our framework incorporates self-reflection and Chain-of-Thought (CoT) strategies, along with feedback mechanisms, enhancing the depth and breadth of the evaluation process and guiding discussions towards consensus, while the framework generates comprehensive evaluation reports, including error localization, error types and scoring. Experimental results show that our framework outperforms existing open-ended text evaluation methods and achieves the highest correlation with human evaluation, which confirms the effectiveness and advancement of our framework in addressing the uncertainties and instabilities in evaluating LLMs-generated text. Furthermore, our framework significantly improves the efficiency of text evaluation and model iteration in industrial scenarios.
Read more4/16/2024

0
Large Language Models as Evaluators for Recommendation Explanations
Xiaoyu Zhang, Yishan Li, Jiayin Wang, Bowen Sun, Weizhi Ma, Peijie Sun, Min Zhang
The explainability of recommender systems has attracted significant attention in academia and industry. Many efforts have been made for explainable recommendations, yet evaluating the quality of the explanations remains a challenging and unresolved issue. In recent years, leveraging LLMs as evaluators presents a promising avenue in Natural Language Processing tasks (e.g., sentiment classification, information extraction), as they perform strong capabilities in instruction following and common-sense reasoning. However, evaluating recommendation explanatory texts is different from these NLG tasks, as its criteria are related to human perceptions and are usually subjective. In this paper, we investigate whether LLMs can serve as evaluators of recommendation explanations. To answer the question, we utilize real user feedback on explanations given from previous work and additionally collect third-party annotations and LLM evaluations. We design and apply a 3-level meta evaluation strategy to measure the correlation between evaluator labels and the ground truth provided by users. Our experiments reveal that LLMs, such as GPT4, can provide comparable evaluations with appropriate prompts and settings. We also provide further insights into combining human labels with the LLM evaluation process and utilizing ensembles of multiple heterogeneous LLM evaluators to enhance the accuracy and stability of evaluations. Our study verifies that utilizing LLMs as evaluators can be an accurate, reproducible and cost-effective solution for evaluating recommendation explanation texts. Our code is available at https://github.com/Xiaoyu-SZ/LLMasEvaluator.
Read more6/7/2024

0
METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
Read more4/3/2024