Representation Learning of Tangled Key-Value Sequence Data for Early Classification

0
📊
Sign in to get full access
Overview
- Key-value sequence data is common in many real-world applications like e-commerce and networking
- Classifying these key-value sequences is important for tasks like user profiling and malicious application detection
- There is a need to classify sequences both accurately and quickly, but these goals can be conflicting
- The paper introduces a novel "tangled key-value sequence early classification" problem and proposes a method to address it
Plain English Explanation
Key-value data is information that comes in pairs, like a product ID paired with the quantity purchased. This kind of data is very common in many different areas, such as the sequences of products users buy on e-commerce sites or the network packets passed through routers. Being able to classify this key-value data is useful for things like understanding user behavior or detecting malicious software.
However, in many real-world situations, it's not enough to just classify the data accurately - you also need to do it quickly. For example, if you're trying to spot a potential cyber attack, you want to be able to identify it as soon as possible to respond fast. But achieving both high accuracy and early classification can be challenging, as they can sometimes work against each other.
This paper tackles a specific version of this problem, called "tangled key-value sequence early classification." Tangled means the key-value data can have multiple different "key" values mixed together, and the goal is to classify each individual key-value sequence accurately and as early as possible. To do this, the researchers developed a new method called KVEC that uses the relationships between the keys and values to learn a better way to represent the data and decide when to make the classification.
Technical Explanation
The KVEC method proposed in this paper aims to address the "tangled key-value sequence early classification" problem. It leverages both the relationships between items that share the same key ("inner-correlation") as well as the relationships between items with different keys ("inter-correlation") to learn a better representation of the sequence data.
Specifically, KVEC uses "key correlation" to model the inner-correlations and "value correlation" to model the inter-correlations. These are then used to create a more informative sequence representation. Additionally, KVEC employs a "time-aware halting policy" that decides when to stop processing the ongoing sequence and make the classification, based on the current sequence representation.
The paper evaluates KVEC on both real-world and synthetic datasets, and shows that it outperforms state-of-the-art baselines. KVEC improves classification accuracy by up to 17.5% under the same earliness constraint, and improves the harmonic mean of accuracy and earliness by up to 14%.
Critical Analysis
The paper provides a novel formulation of the "tangled key-value sequence early classification" problem and presents a promising solution in the form of the KVEC method. By leveraging both inner- and inter-correlations in the data, KVEC is able to learn more informative sequence representations that enable both accurate and early classification.
However, the paper does not extensively discuss the potential limitations or caveats of the KVEC method. For example, it's unclear how well KVEC would scale to very large or high-dimensional datasets, or how sensitive it might be to noisy or missing data. Additionally, the paper does not explore potential biases or fairness issues that could arise from the way KVEC processes and classifies the key-value sequences.
Further research could also investigate the generalizability of KVEC beyond the specific problem formulation presented here. For instance, the paper on Koala shows how techniques for processing sequential data can be applied to other domains like video understanding.
Overall, the KVEC method represents an interesting and potentially impactful contribution to the field of sequential data classification. However, a more thorough exploration of its limitations and broader applicability would help strengthen the paper's impact and ensure the responsible development of this line of research.
Conclusion
This paper introduces a novel "tangled key-value sequence early classification" problem and proposes a method called KVEC to address it. KVEC leverages both the inner-correlations and inter-correlations in the data to learn better sequence representations, which it then uses to classify the individual key-value sequences both accurately and quickly.
The results show KVEC outperforms state-of-the-art baselines, improving classification accuracy by up to 17.5% and the overall accuracy-earliness trade-off by up to 14%. This suggests KVEC could be a valuable tool for real-world applications that require fast and reliable classification of key-value sequence data, such as user profiling in e-commerce or malicious application detection in networking.
While the paper presents a promising new approach, further research is needed to fully understand the strengths, limitations, and broader applicability of the KVEC method. Expanding the evaluation, exploring potential biases, and investigating connections to other sequential data processing techniques could all help strengthen this line of research and ensure it has a positive impact on the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Representation Learning of Tangled Key-Value Sequence Data for Early Classification
Tao Duan, Junzhou Zhao, Shuo Zhang, Jing Tao, Pinghui Wang
Key-value sequence data has become ubiquitous and naturally appears in a variety of real-world applications, ranging from the user-product purchasing sequences in e-commerce, to network packet sequences forwarded by routers in networking. Classifying these key-value sequences is important in many scenarios such as user profiling and malicious applications identification. In many time-sensitive scenarios, besides the requirement of classifying a key-value sequence accurately, it is also desired to classify a key-value sequence early, in order to respond fast. However, these two goals are conflicting in nature, and it is challenging to achieve them simultaneously. In this work, we formulate a novel tangled key-value sequence early classification problem, where a tangled key-value sequence is a mixture of several concurrent key-value sequences with different keys. The goal is to classify each individual key-value sequence sharing a same key both accurately and early. To address this problem, we propose a novel method, i.e., Key-Value sequence Early Co-classification (KVEC), which leverages both inner- and inter-correlations of items in a tangled key-value sequence through key correlation and value correlation to learn a better sequence representation. Meanwhile, a time-aware halting policy decides when to stop the ongoing key-value sequence and classify it based on current sequence representation. Experiments on both real-world and synthetic datasets demonstrate that our method outperforms the state-of-the-art baselines significantly. KVEC improves the prediction accuracy by up to $4.7 - 17.5%$ under the same prediction earliness condition, and improves the harmonic mean of accuracy and earliness by up to $3.7 - 14.0%$.
Read more4/12/2024
0
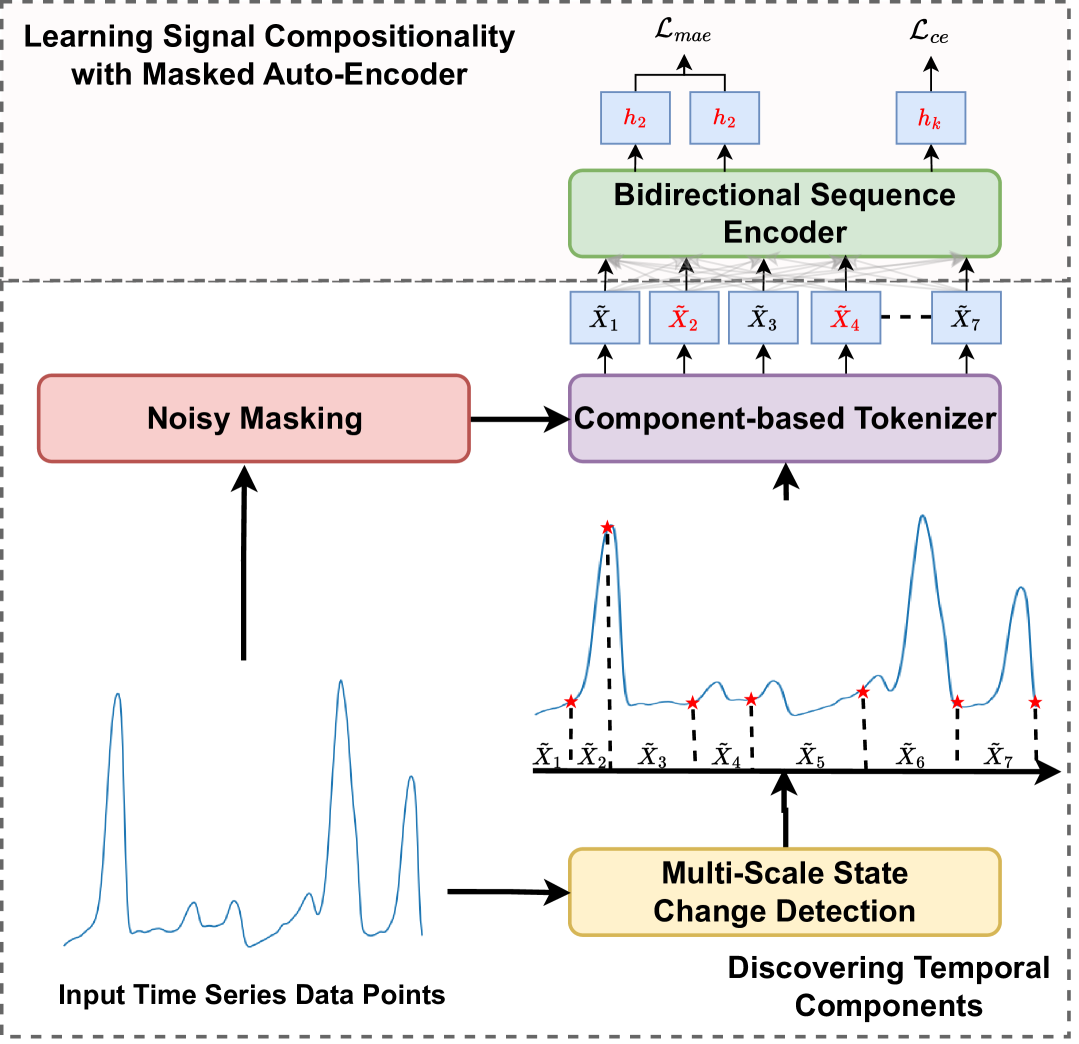
Capturing Temporal Components for Time Series Classification
Venkata Ragavendra Vavilthota, Ranjith Ramanathan, Sathyanarayanan N. Aakur
Analyzing sequential data is crucial in many domains, particularly due to the abundance of data collected from the Internet of Things paradigm. Time series classification, the task of categorizing sequential data, has gained prominence, with machine learning approaches demonstrating remarkable performance on public benchmark datasets. However, progress has primarily been in designing architectures for learning representations from raw data at fixed (or ideal) time scales, which can fail to generalize to longer sequences. This work introduces a textit{compositional representation learning} approach trained on statistically coherent components extracted from sequential data. Based on a multi-scale change space, an unsupervised approach is proposed to segment the sequential data into chunks with similar statistical properties. A sequence-based encoder model is trained in a multi-task setting to learn compositional representations from these temporal components for time series classification. We demonstrate its effectiveness through extensive experiments on publicly available time series classification benchmarks. Evaluating the coherence of segmented components shows its competitive performance on the unsupervised segmentation task.
Read more6/21/2024
0
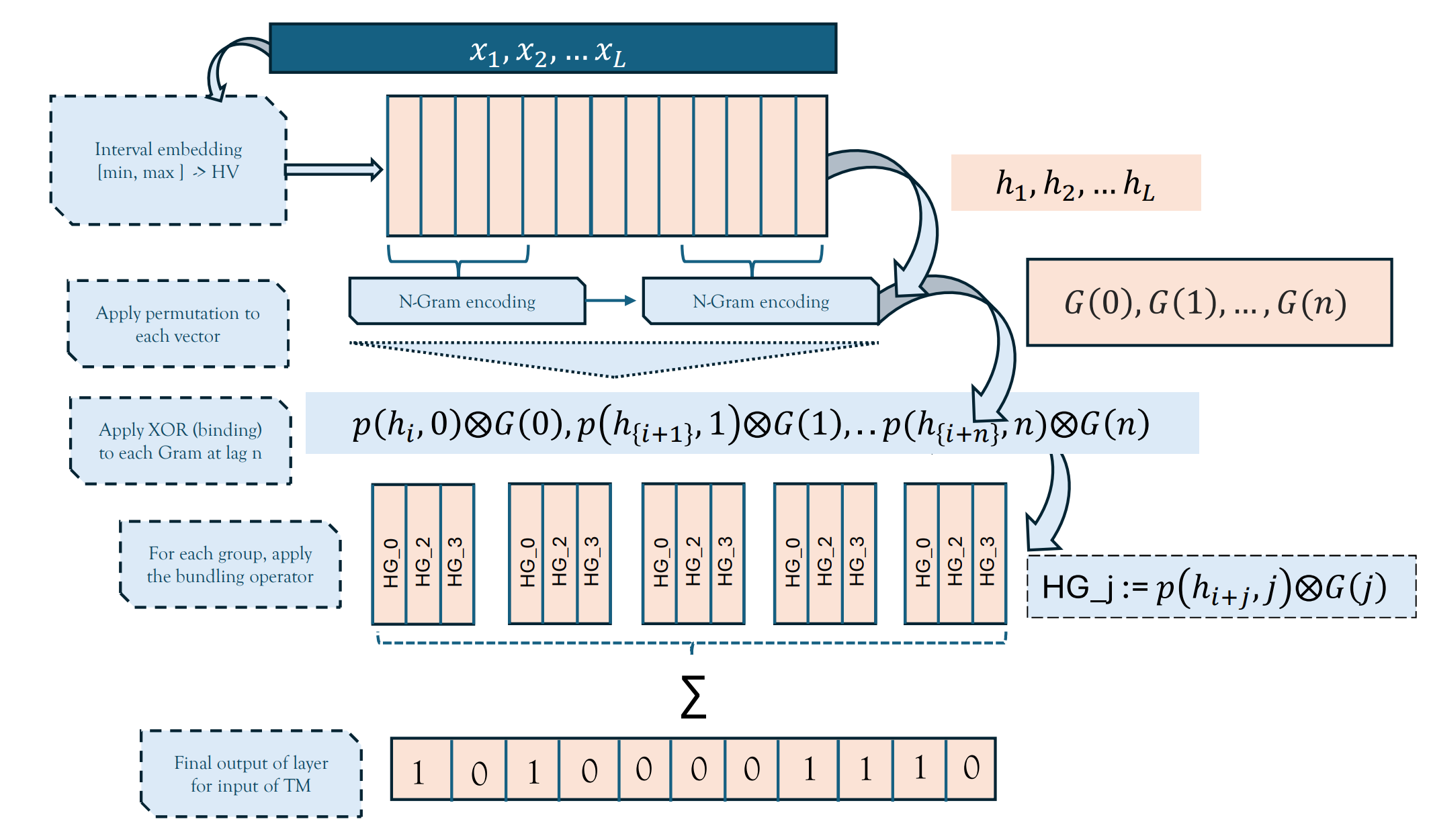
Hyperdimensional Vector Tsetlin Machines with Applications to Sequence Learning and Generation
Christian D. Blakely
We construct a two-layered model for learning and generating sequential data that is both computationally fast and competitive with vanilla Tsetlin machines, adding numerous advantages. Through the use of hyperdimensional vector computing (HVC) algebras and Tsetlin machine clause structures, we demonstrate that the combination of both inherits the generality of data encoding and decoding of HVC with the fast interpretable nature of Tsetlin machines to yield a powerful machine learning model. We apply the approach in two areas, namely in forecasting, generating new sequences, and classification. For the latter, we derive results for the entire UCR Time Series Archive and compare with the standard benchmarks to see how well the method competes in time series classification.
Read more8/30/2024

0
Nonlinear time-series embedding by monotone variational inequality
Jonathan Y. Zhou, Yao Xie
In the wild, we often encounter collections of sequential data such as electrocardiograms, motion capture, genomes, and natural language, and sequences may be multichannel or symbolic with nonlinear dynamics. We introduce a new method to learn low-dimensional representations of nonlinear time series without supervision and can have provable recovery guarantees. The learned representation can be used for downstream machine-learning tasks such as clustering and classification. The method is based on the assumption that the observed sequences arise from a common domain, but each sequence obeys its own autoregressive models that are related to each other through low-rank regularization. We cast the problem as a computationally efficient convex matrix parameter recovery problem using monotone Variational Inequality and encode the common domain assumption via low-rank constraint across the learned representations, which can learn the geometry for the entire domain as well as faithful representations for the dynamics of each individual sequence using the domain information in totality. We show the competitive performance of our method on real-world time-series data with the baselines and demonstrate its effectiveness for symbolic text modeling and RNA sequence clustering.
Read more6/12/2024