Vision language models are blind

2

Sign in to get full access
Overview
- The paper investigates the limitations of current vision language models (VLMs) in understanding and reasoning about geometric primitives like lines, circles, and triangles.
- It highlights the need for VLMs to have a stronger grasp of fundamental geometric concepts to be truly "seeing" in the way humans do.
- The paper proposes a new benchmark, GeoMRC, to assess VLMs' abilities to understand and reason about geometric primitives and their relationships.
Plain English Explanation
Vision language models (VLMs) are a type of artificial intelligence that can understand and generate language while also processing visual information. These models have become increasingly powerful in recent years, with the ability to perform tasks like image captioning, visual question answering, and multi-modal reasoning.
However, this paper argues that current VLMs are still "blind" in many ways. They may be able to identify objects, scenes, and people in images, but they lack a deep understanding of fundamental geometric concepts like lines, circles, and triangles. This is a significant limitation, as humans use their intuitive grasp of geometry to make sense of the world around them.
To address this issue, the researchers propose a new benchmark called GeoMRC, which tests VLMs' ability to reason about geometric primitives and their relationships. This benchmark presents a series of visual tasks, such as identifying the properties of shapes or describing how shapes are arranged in an image.
By evaluating VLMs on this new benchmark, the researchers hope to shed light on the limitations of existing models and inspire the development of more "seeing" AI systems that can truly understand the geometry of the world, just as humans do.
Technical Explanation
The paper starts by highlighting the impressive capabilities of current vision language models, which can perform a wide range of multimodal tasks. However, the authors argue that these models still lack a fundamental understanding of geometric primitives and their relationships.
To assess this limitation, the researchers introduce a new benchmark called GeoMRC (Geometric Modeling and Reasoning Challenge). GeoMRC presents VLMs with a series of tasks that require reasoning about the properties and relationships of geometric shapes, such as lines, circles, and triangles.
The paper describes the design and implementation of the GeoMRC benchmark, including the dataset creation process and the various task types. These tasks include identifying the properties of shapes, describing how shapes are arranged, and answering questions about the geometric relationships between elements in an image.
The authors then evaluate several state-of-the-art VLMs on the GeoMRC benchmark, including CLIP and BLIP. The results show that while these models perform well on traditional visual understanding tasks, they struggle significantly on the geometric reasoning tasks in GeoMRC.
The paper discusses potential reasons for this performance gap, such as the models' reliance on learned associations rather than a deeper understanding of geometric principles. The authors also suggest ways to address this limitation, such as incorporating geometric reasoning capabilities into the training and architecture of future VLMs.
Critical Analysis
The paper makes a compelling case that current VLMs are "blind" to fundamental geometric concepts, which is a significant limitation in their ability to truly understand the visual world in the way humans do.
The introduction of the GeoMRC benchmark is a valuable contribution, as it provides a standardized way to assess VLMs' geometric reasoning capabilities. This could help drive progress in the field and inspire the development of more sophisticated models that can better grasp the geometric structure of the world.
However, the paper does not explore the potential reasons for this geometric "blindness" in depth. It would be interesting to see the authors delve deeper into the architectural choices, training data, and learning algorithms that may be contributing to this limitation.
Additionally, the paper does not discuss the potential real-world implications of VLMs' geometric reasoning deficits. It would be valuable to explore how these limitations could impact the performance of VLMs in practical applications, such as autonomous navigation, computer-aided design, or scientific visualization.
Overall, this paper highlights an important issue in the field of vision language modeling and provides a useful benchmark for addressing it. Further research in this area could lead to significant advancements in the development of truly "seeing" AI systems.
Conclusion
This paper argues that current vision language models (VLMs) are "blind" to fundamental geometric concepts, such as the properties and relationships of lines, circles, and triangles. To address this limitation, the researchers introduce a new benchmark called GeoMRC, which tests VLMs' ability to reason about geometric primitives.
The results of the benchmark evaluations show that state-of-the-art VLMs struggle significantly on the geometric reasoning tasks, suggesting that these models lack a deep understanding of the geometric structure of the visual world.
By highlighting this issue and providing a standardized way to assess it, the paper lays the groundwork for the development of more sophisticated VLMs that can truly "see" the world in the way humans do. Addressing the geometric reasoning deficits of current models could lead to significant advancements in fields like autonomous navigation, computer-aided design, and scientific visualization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
2
Vision language models are blind
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, Anh Totti Nguyen
While large language models with vision capabilities (VLMs), e.g., GPT-4o and Gemini 1.5 Pro, are powering various image-text applications and scoring high on many vision-understanding benchmarks, we find that they are surprisingly still struggling with low-level vision tasks that are easy to humans. Specifically, on BlindTest, our suite of 7 very simple tasks such as identifying (a) whether two circles overlap; (b) whether two lines intersect; (c) which letter is being circled in a word; and (d) counting circles in an Olympic-like logo, four state-of-the-art VLMs are only 58.57% accurate on average. Claude 3.5 Sonnet performs the best at 74.94% accuracy, but this is still far from the human expected accuracy of 100%. Across different image resolutions and line widths, VLMs consistently struggle with tasks that require precise spatial information and recognizing geometric primitives that overlap or are close together. Code and data are available at: https://vlmsareblind.github.io
Read more7/29/2024
0
Response Wide Shut: Surprising Observations in Basic Vision Language Model Capabilities
Shivam Chandhok, Wan-Cyuan Fan, Leonid Sigal
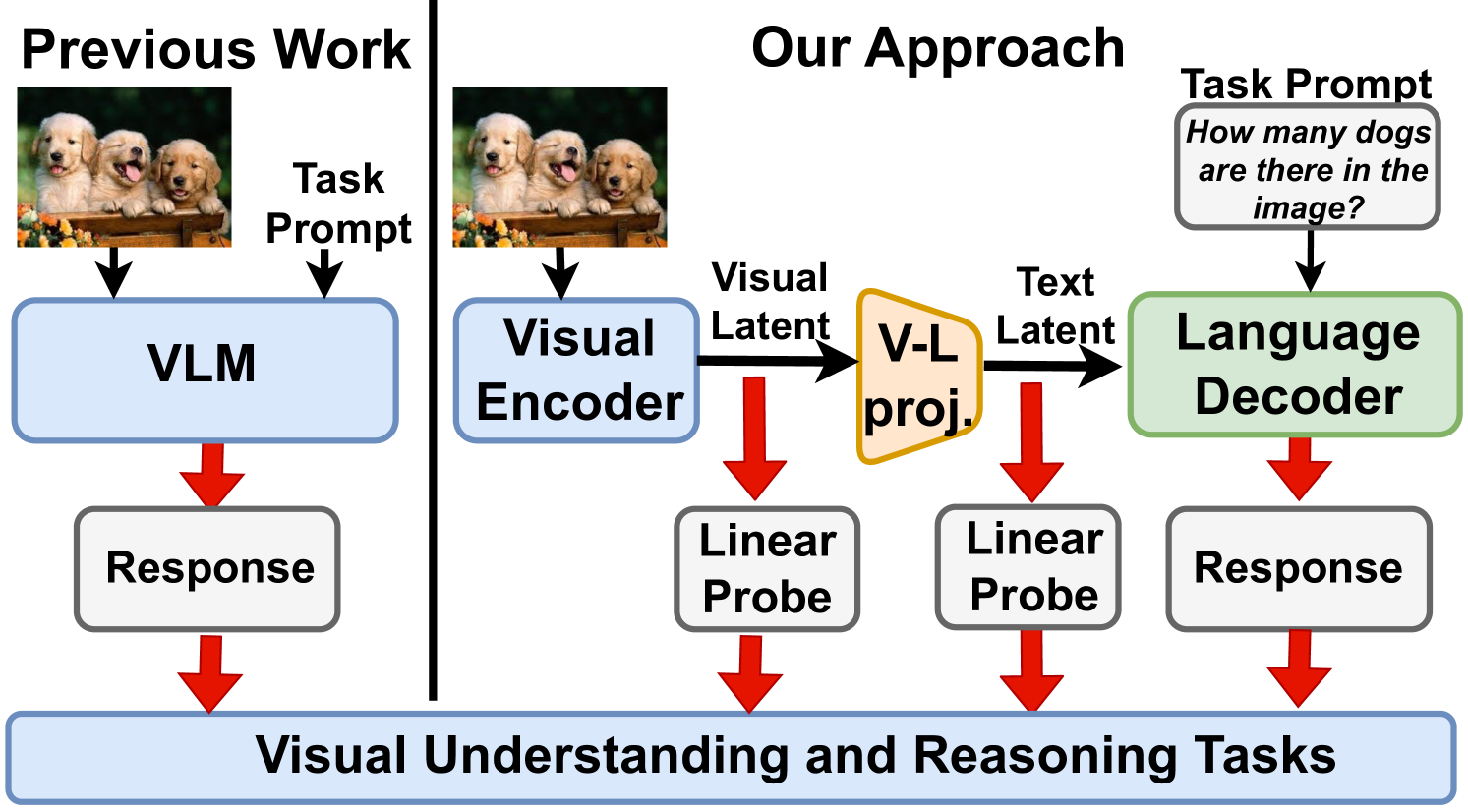
Vision-Language Models (VLMs) have emerged as general purpose tools for addressing a variety of complex computer vision problems. Such models have been shown to be highly capable, but, at the same time, also lacking some basic visual understanding skills. In this paper, we set out to understand the limitations of SoTA VLMs on fundamental visual tasks: object classification, understanding spatial arrangement, and ability to delineate individual object instances (through counting), by constructing a series of tests that probe which components of design, specifically, maybe lacking. Importantly, we go significantly beyond the current benchmarks, that simply measure final performance of VLM, by also comparing and contrasting it to performance of probes trained directly on features obtained from visual encoder (image embeddings), as well as intermediate vision-language projection used to bridge image-encoder and LLM-decoder ouput in many SoTA models (e.g., LLaVA, BLIP, InstructBLIP). In doing so, we uncover nascent shortcomings in VLMs response and make a number of important observations which could help train and develop more effective VLM models in future.
Read more8/14/2024

0
Vision-Language Models under Cultural and Inclusive Considerations
Antonia Karamolegkou, Phillip Rust, Yong Cao, Ruixiang Cui, Anders S{o}gaard, Daniel Hershcovich
Large vision-language models (VLMs) can assist visually impaired people by describing images from their daily lives. Current evaluation datasets may not reflect diverse cultural user backgrounds or the situational context of this use case. To address this problem, we create a survey to determine caption preferences and propose a culture-centric evaluation benchmark by filtering VizWiz, an existing dataset with images taken by people who are blind. We then evaluate several VLMs, investigating their reliability as visual assistants in a culturally diverse setting. While our results for state-of-the-art models are promising, we identify challenges such as hallucination and misalignment of automatic evaluation metrics with human judgment. We make our survey, data, code, and model outputs publicly available.
Read more7/9/2024

0
IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models
Haz Sameen Shahgir, Khondker Salman Sayeed, Abhik Bhattacharjee, Wasi Uddin Ahmad, Yue Dong, Rifat Shahriyar
The advent of Vision Language Models (VLM) has allowed researchers to investigate the visual understanding of a neural network using natural language. Beyond object classification and detection, VLMs are capable of visual comprehension and common-sense reasoning. This naturally led to the question: How do VLMs respond when the image itself is inherently unreasonable? To this end, we present IllusionVQA: a diverse dataset of challenging optical illusions and hard-to-interpret scenes to test the capability of VLMs in two distinct multiple-choice VQA tasks - comprehension and soft localization. GPT4V, the best performing VLM, achieves 62.99% accuracy (4-shot) on the comprehension task and 49.7% on the localization task (4-shot and Chain-of-Thought). Human evaluation reveals that humans achieve 91.03% and 100% accuracy in comprehension and localization. We discover that In-Context Learning (ICL) and Chain-of-Thought reasoning substantially degrade the performance of Gemini-Pro in the localization task. Tangentially, we discover a potential weakness in the ICL capabilities of VLMs: they fail to locate optical illusions even when the correct answer is in the context window as a few-shot example.
Read more8/12/2024