Rethinking Conventional Wisdom in Machine Learning: From Generalization to Scaling

0

Sign in to get full access
Overview
- The paper "Rethinking Conventional Wisdom in Machine Learning: From Generalization to Scaling" challenges the traditional view of machine learning and proposes a new perspective.
- It explores two paradigms in machine learning: the generalization paradigm and the scaling paradigm.
- The paper suggests that the scaling paradigm better explains the observed performance of modern machine learning models, particularly large language models.
Plain English Explanation
The paper argues that the conventional understanding of machine learning, which focuses on generalization, is not sufficient to fully explain the remarkable performance of large-scale machine learning models, such as large language models. Instead, the authors propose a new perspective, called the "scaling paradigm," which better captures the observed behavior of these models.
In the traditional generalization paradigm, machine learning models are trained on a limited dataset and are expected to perform well on new, unseen data. The goal is to create models that can generalize from the training data to the broader distribution. However, the paper suggests that this paradigm falls short when it comes to the impressive capabilities of large language models, which often exhibit surprising performance even on tasks they were not explicitly trained for.
The scaling paradigm, on the other hand, focuses on how the performance of machine learning models improves as the models become larger and are trained on more data. The paper presents empirical evidence that the scaling behavior of modern machine learning models, particularly language models, follows predictable patterns that can be described by scaling laws. These scaling laws suggest that the performance of these models is not primarily determined by their ability to generalize, but rather by their ability to continue improving as they are scaled up in size and trained on more data.
Technical Explanation
The paper begins by contrasting the two dominant paradigms in machine learning: the generalization paradigm and the scaling paradigm. The generalization paradigm focuses on creating models that can perform well on new, unseen data by learning the underlying patterns in the training data. In contrast, the scaling paradigm emphasizes how the performance of machine learning models improves as they are scaled up in size and trained on more data.
The authors provide empirical evidence that the scaling paradigm better explains the observed behavior of modern machine learning models, particularly large language models. They present studies that demonstrate how the performance of these models follows predictable scaling laws, where the model's performance on various tasks increases as a power-law function of the model size and the amount of training data. This suggests that the key driver of these models' capabilities is not their ability to generalize, but rather their ability to continue improving through scaling.
The paper also discusses the implications of the scaling paradigm, including the potential for further performance gains through continued model scaling, the importance of computational resources and data availability in driving model performance, and the challenges of interpreting and understanding the behavior of these large-scale models.
Critical Analysis
The paper makes a compelling case for the scaling paradigm as a more appropriate framework for understanding the capabilities of modern machine learning models, particularly large language models. The authors provide strong empirical evidence to support their claims, and the insights they present have significant implications for the field of machine learning.
One potential limitation of the research is that it focuses primarily on language models, and it is unclear how well the scaling paradigm applies to other types of machine learning models, such as vision or reinforcement learning models. Additionally, the paper does not delve deeply into the underlying mechanisms that enable these scaling behaviors, which would be a valuable area for further research.
Another aspect that could be explored further is the potential downsides or challenges that may arise from the scaling paradigm, such as issues related to model interpretability, fairness, or the environmental impact of training large-scale models. While the paper acknowledges these concerns, a more in-depth discussion of the tradeoffs and potential mitigation strategies would be informative.
Overall, the paper's central argument and the evidence presented are thought-provoking and challenge the conventional wisdom in machine learning. This research encourages readers to think critically about the field and consider alternative perspectives that may better explain the remarkable capabilities of modern machine learning systems.
Conclusion
The paper "Rethinking Conventional Wisdom in Machine Learning: From Generalization to Scaling" presents a compelling case for a paradigm shift in how we understand and approach machine learning. The authors argue that the traditional generalization paradigm is insufficient to fully explain the performance of large-scale machine learning models, particularly large language models. Instead, they propose the scaling paradigm, which focuses on how model performance improves as models are scaled up in size and trained on more data.
The empirical evidence and insights presented in the paper have significant implications for the future of machine learning. They suggest that continued scaling of models may lead to further performance gains, and that the availability of computational resources and data will be crucial factors in driving model capabilities. At the same time, the scaling paradigm raises important questions about model interpretation, fairness, and environmental impact that will need to be addressed as the field evolves.
Overall, this research encourages the machine learning community to rethink its conventional wisdom and embrace new perspectives that may better capture the complex and rapidly evolving nature of modern machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Rethinking Conventional Wisdom in Machine Learning: From Generalization to Scaling
Lechao Xiao
The remarkable success of large language pretraining and the discovery of scaling laws signify a paradigm shift in machine learning. Notably, the primary objective has evolved from minimizing generalization error to reducing approximation error, and the most effective strategy has transitioned from regularization (in a broad sense) to scaling up models. This raises a critical question: Do the established principles that proved successful in the generalization-centric era remain valid in this new era of scaling? This paper examines several influential regularization-based principles that may no longer hold true in the scaling-centric, large language model (LLM) era. These principles include explicit L2 regularization and implicit regularization through small batch sizes and large learning rates. Additionally, we identify a new phenomenon termed ``scaling law crossover,'' where two scaling curves intersect at a certain scale, implying that methods effective at smaller scales may not generalize to larger ones. Together, these observations highlight two fundamental questions within this new paradigm: $bullet$ Guiding Principles for Scaling: If regularization is no longer the primary guiding principle for model design, what new principles are emerging to guide scaling? $bullet$ Model Comparison at Scale: How to reliably and effectively compare models at the scale where only a single experiment is feasible?
Read more9/24/2024
0
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
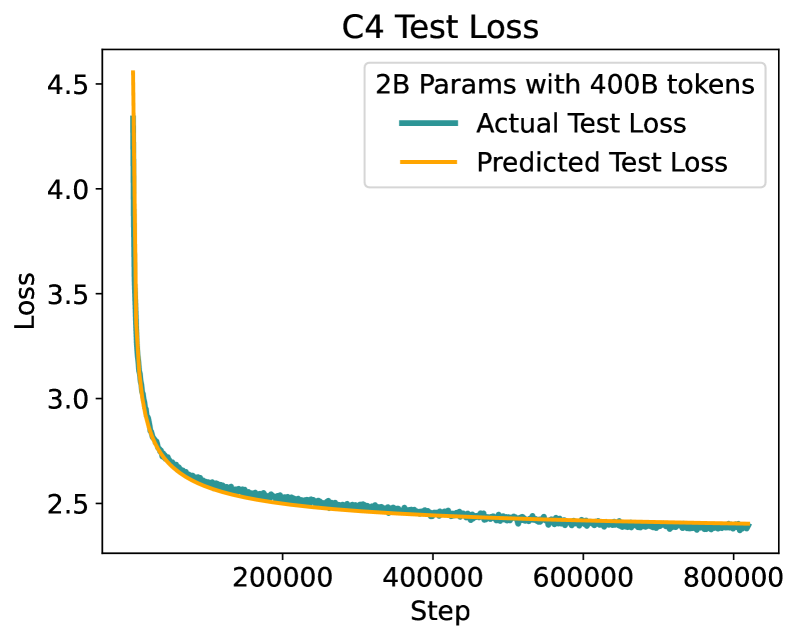
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
Read more4/8/2024
🔮
0
Scaling Laws Do Not Scale
Fernando Diaz, Michael Madaio
Recent work has advocated for training AI models on ever-larger datasets, arguing that as the size of a dataset increases, the performance of a model trained on that dataset will correspondingly increase (referred to as scaling laws). In this paper, we draw on literature from the social sciences and machine learning to critically interrogate these claims. We argue that this scaling law relationship depends on metrics used to measure performance that may not correspond with how different groups of people perceive the quality of models' output. As the size of datasets used to train large AI models grows and AI systems impact ever larger groups of people, the number of distinct communities represented in training or evaluation datasets grows. It is thus even more likely that communities represented in datasets may have values or preferences not reflected in (or at odds with) the metrics used to evaluate model performance in scaling laws. Different communities may also have values in tension with each other, leading to difficult, potentially irreconcilable choices about metrics used for model evaluations -- threatening the validity of claims that model performance is improving at scale. We end the paper with implications for AI development: that the motivation for scraping ever-larger datasets may be based on fundamentally flawed assumptions about model performance. That is, models may not, in fact, continue to improve as the datasets get larger -- at least not for all people or communities impacted by those models. We suggest opportunities for the field to rethink norms and values in AI development, resisting claims for universality of large models, fostering more local, small-scale designs, and other ways to resist the impetus towards scale in AI.
Read more7/30/2024
💬
0
Selecting Large Language Model to Fine-tune via Rectified Scaling Law
Haowei Lin, Baizhou Huang, Haotian Ye, Qinyu Chen, Zihao Wang, Sujian Li, Jianzhu Ma, Xiaojun Wan, James Zou, Yitao Liang
The ever-growing ecosystem of LLMs has posed a challenge in selecting the most appropriate pre-trained model to fine-tune amidst a sea of options. Given constrained resources, fine-tuning all models and making selections afterward is unrealistic. In this work, we formulate this resource-constrained selection task into predicting fine-tuning performance and illustrate its natural connection with Scaling Law. Unlike pre-training, we find that the fine-tuning scaling curve includes not just the well-known power phase but also the previously unobserved pre-power phase. We also explain why existing Scaling Law fails to capture this phase transition phenomenon both theoretically and empirically. To address this, we introduce the concept of pre-learned data size into our Rectified Scaling Law, which overcomes theoretical limitations and fits experimental results much better. By leveraging our law, we propose a novel LLM selection algorithm that selects the near-optimal model with hundreds of times less resource consumption, while other methods may provide negatively correlated selection. The project page is available at rectified-scaling-law.github.io.
Read more5/29/2024