Rethinking of Encoder-based Warm-start Methods in Hyperparameter Optimization

0

Sign in to get full access
Overview
- This paper explores encoder-based warm-start methods for hyperparameter optimization, which aim to speed up the optimization process by leveraging prior knowledge.
- The authors rethink the role of encoder-based methods and propose a new approach that focuses on learning effective representations of the hyperparameter space.
- The paper presents experiments comparing different encoder-based methods and offers insights into their strengths and limitations.
Plain English Explanation
Hyperparameter optimization is the process of finding the best set of parameters for a machine learning model. This can be a time-consuming task, as it often involves trying many different combinations of parameters. Encoder-based warm-start methods aim to speed up this process by using prior knowledge to guide the search.
The authors of this paper take a closer look at these encoder-based methods and question some of the assumptions behind them. They propose a new approach that focuses on learning effective representations of the hyperparameter space, rather than just using the encoders to initialize the optimization process.
Through experiments, the authors provide insights into the strengths and limitations of different encoder-based methods. This can help researchers and practitioners make more informed choices when selecting and using these techniques in their own work.
Technical Explanation
The paper presents a rethinking of encoder-based warm-start methods for hyperparameter optimization. Encoder-based methods aim to leverage prior knowledge about the hyperparameter space by learning a mapping from hyperparameters to a lower-dimensional representation, which can then be used to guide the optimization process.
The authors first examine the representations learned by these encoder-based methods and find that they do not always capture the most relevant information for the optimization task. They then propose a new approach that focuses on learning effective representations of the hyperparameter space, which can be used to guide the optimization process more effectively.
The paper includes experiments comparing different encoder-based methods, as well as the authors' proposed approach. The results provide insights into the strengths and limitations of each method, and suggest that the proposed approach can outperform existing encoder-based methods in certain scenarios.
Critical Analysis
The paper raises important questions about the role of encoder-based warm-start methods in hyperparameter optimization. While these methods have shown promise in previous work, the authors' analysis suggests that the representations learned by the encoders may not always be well-suited for the optimization task.
One potential limitation of the paper is that the experiments are focused on a limited set of benchmark problems and optimization algorithms. It would be valuable to see how the proposed approach performs on a wider range of tasks and optimization methods, as well as in real-world applications.
Additionally, the paper does not delve too deeply into the reasons why the learned representations may not be optimal for the optimization task. Further investigation into the factors that influence the quality of the representations could provide valuable insights for improving encoder-based methods.
Overall, the paper makes a compelling case for rethinking the role of encoder-based methods in hyperparameter optimization and offers a promising new approach for learning effective representations of the hyperparameter space.
Conclusion
This paper presents a critical examination of encoder-based warm-start methods for hyperparameter optimization. The authors propose a new approach that focuses on learning effective representations of the hyperparameter space, rather than simply using the encoders to initialize the optimization process.
The experimental results suggest that this new approach can outperform existing encoder-based methods in certain scenarios, providing valuable insights for researchers and practitioners working on hyperparameter optimization. The paper also raises important questions about the role of encoders in this context, which could inspire further research into more effective ways of leveraging prior knowledge to accelerate the optimization process.
Overall, this work contributes to the ongoing efforts to improve the efficiency and effectiveness of hyperparameter optimization, with potential implications for a wide range of machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking of Encoder-based Warm-start Methods in Hyperparameter Optimization
Dawid P{l}udowski, Antoni Zajko, Anna Kozak, Katarzyna Wo'znica
Effectively representing heterogeneous tabular datasets for meta-learning purposes remains an open problem. Previous approaches rely on predefined meta-features, for example, statistical measures or landmarkers. The emergence of dataset encoders opens new possibilities for the extraction of meta-features because they do not involve any handmade design. Moreover, they are proven to generate dataset representations with desired spatial properties. In this research, we evaluate an encoder-based approach to one of the most established meta-tasks - warm-starting of the Bayesian Hyperparameter Optimization. To broaden our analysis we introduce a new approach for representation learning on tabular data based on [Tomoharu Iwata and Atsutoshi Kumagai. Meta-learning from Tasks with Heterogeneous Attribute Spaces. In Advances in Neural Information Processing Systems, 2020]. The validation on over 100 datasets from UCI and an independent metaMIMIC set of datasets highlights the nuanced challenges in representation learning. We show that general representations may not suffice for some meta-tasks where requirements are not explicitly considered during extraction.
Read more8/19/2024
📊
0
Under the Hood of Tabular Data Generation Models: the Strong Impact of Hyperparameter Tuning
G. Charbel N. Kindji (LACODAM), Lina Maria Rojas-Barahona (LACODAM), Elisa Fromont (LACODAM), Tanguy Urvoy
We investigate the impact of dataset-specific hyperparameter, feature encoding, and architecture tuning on five recent model families for tabular data generation through an extensive benchmark on 16 datasets. This study addresses the practical need for a unified evaluation of models that fully considers hyperparameter optimization. Additionally, we propose a reduced search space for each model that allows for quick optimization, achieving nearly equivalent performance at a significantly lower cost.Our benchmark demonstrates that, for most models, large-scale dataset-specific tuning substantially improves performance compared to the original configurations. Furthermore, we confirm that diffusion-based models generally outperform other models on tabular data. However, this advantage is not significant when the entire tuning and training process is restricted to the same GPU budget for all models.
Read more7/15/2024

0
Deep Feature Embedding for Tabular Data
Yuqian Wu, Hengyi Luo, Raymond S. T. Lee
Tabular data learning has extensive applications in deep learning but its existing embedding techniques are limited in numerical and categorical features such as the inability to capture complex relationships and engineering. This paper proposes a novel deep embedding framework with leverages lightweight deep neural networks to generate effective feature embeddings for tabular data in machine learning research. For numerical features, a two-step feature expansion and deep transformation technique is used to capture copious semantic information. For categorical features, a unique identification vector for each entity is referred by a compact lookup table with a parameterized deep embedding function to uniform the embedding size dimensions, and transformed into a embedding vector using deep neural network. Experiments are conducted on real-world datasets for performance evaluation.
Read more9/2/2024
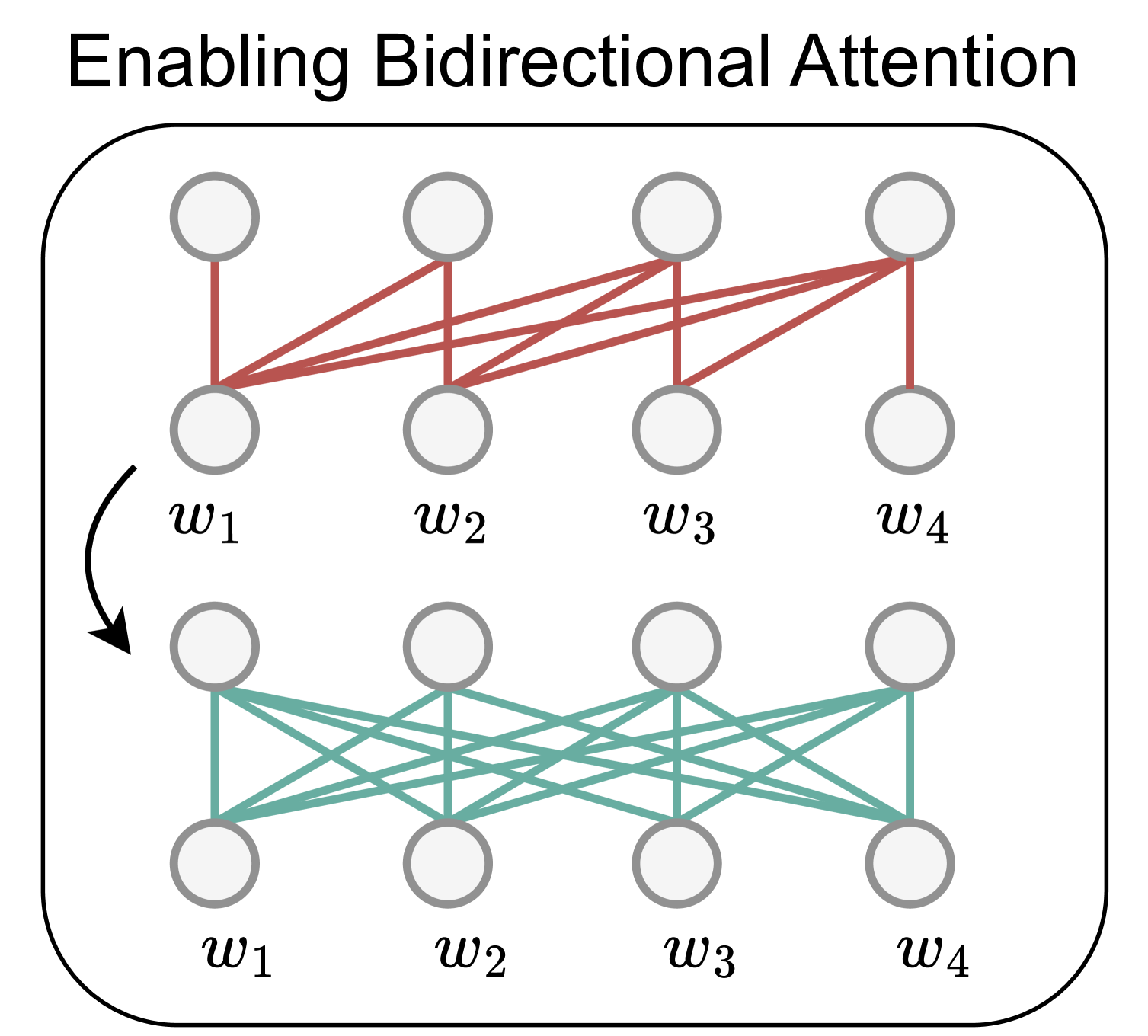
20
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, Siva Reddy
Large decoder-only language models (LLMs) are the state-of-the-art models on most of today's NLP tasks and benchmarks. Yet, the community is only slowly adopting these models for text embedding tasks, which require rich contextualized representations. In this work, we introduce LLM2Vec, a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder. LLM2Vec consists of three simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. We demonstrate the effectiveness of LLM2Vec by applying it to 4 popular LLMs ranging from 1.3B to 8B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB). Moreover, when combining LLM2Vec with supervised contrastive learning, we achieve state-of-the-art performance on MTEB among models that train only on publicly available data (as of May 24, 2024). Our strong empirical results and extensive analysis demonstrate that LLMs can be effectively transformed into universal text encoders in a parameter-efficient manner without the need for expensive adaptation or synthetic GPT-4 generated data.
Read more8/23/2024