Under the Hood of Tabular Data Generation Models: the Strong Impact of Hyperparameter Tuning

0
📊
Sign in to get full access
Overview
- The paper investigates the impact of hyperparameter tuning, feature encoding, and architecture selection on the performance of five recent models for tabular data generation.
- The authors benchmark these models on 16 datasets and propose a reduced search space that achieves nearly equivalent performance at a significantly lower cost.
- The key findings include:
- Extensive dataset-specific tuning substantially improves the performance of most models compared to their original configurations.
- Diffusion-based models generally outperform other models on tabular data, but this advantage is not significant when the training process is restricted to the same GPU budget for all models.
Plain English Explanation
The research paper explores how fine-tuning the settings (known as "hyperparameters") of machine learning models, as well as the way the input data is represented (called "feature encoding"), and the model architecture can impact the performance of five recent models for generating tabular data. Tabular data is information organized in rows and columns, like a spreadsheet.
The researchers tested these models on 16 different datasets and found that spending more time carefully optimizing the hyperparameters for each dataset significantly improved the models' performance compared to their original, default settings. They also discovered that a specific type of model called "diffusion-based" models generally outperformed the other models on tabular data.
However, when the researchers restricted all the models to using the same amount of computing power (the same "GPU budget"), the advantage of the diffusion-based models was no longer as significant. This suggests that the other models can achieve similar performance to the diffusion-based models if they are given the opportunity to be tuned and optimized just as extensively.
To help make this tuning process faster and more efficient, the researchers also proposed a reduced search space for optimizing the hyperparameters of each model, which allowed them to achieve nearly the same level of performance as the full optimization, but at a much lower computational cost.
Technical Explanation
The paper presents an extensive benchmark of five recent model families for tabular data generation: variational autoencoders (VAEs), normalizing flows, generative adversarial networks (GANs), diffusion models, and decision tree-based models.
The authors evaluate the impact of dataset-specific hyperparameter tuning, feature encoding, and architectural choices on the performance of these models across 16 diverse tabular datasets. They find that extensive tuning substantially improves the performance of most models compared to their original configurations.
Notably, the authors demonstrate that diffusion-based models generally outperform other model families on tabular data generation tasks. However, this advantage is not significant when the training process is restricted to the same GPU budget for all models, suggesting that the other models can achieve similar performance if given the opportunity for extensive tuning.
To facilitate efficient hyperparameter optimization, the authors propose a reduced search space for each model that allows for quick optimization, achieving nearly equivalent performance at a significantly lower computational cost.
Critical Analysis
The paper provides a comprehensive and systematic evaluation of several prominent tabular data generation models, addressing an important practical need for a unified benchmark that considers the impact of hyperparameter optimization.
One potential limitation of the study is the focus on a relatively small number of model families (five), which may not capture the full diversity of approaches in the field. Additionally, the authors note that their findings are specific to the 16 datasets used in the benchmark, and the generalization to other datasets or real-world applications may require further investigation.
While the authors demonstrate the benefits of extensive dataset-specific tuning, the resources and expertise required for such optimization may not be readily available in all practical settings. The proposed reduced search space approach is a promising solution, but its effectiveness may depend on the specific models and datasets being considered.
Overall, the paper makes a valuable contribution by highlighting the importance of thorough hyperparameter optimization and providing insights into the comparative performance of different tabular data generation models. Readers are encouraged to think critically about the findings and consider the potential tradeoffs and limitations in the context of their own research or application needs.
Conclusion
This research paper presents a comprehensive benchmark of five recent model families for tabular data generation, focusing on the impact of dataset-specific hyperparameter tuning, feature encoding, and architectural choices.
The key findings include:
- Extensive tuning substantially improves the performance of most models compared to their original configurations.
- Diffusion-based models generally outperform other models on tabular data generation, but this advantage is not significant when the training process is restricted to the same GPU budget.
- The authors propose a reduced search space approach that achieves nearly equivalent performance at a significantly lower computational cost.
These insights have important implications for researchers and practitioners working on tabular data generation tasks, highlighting the need for thorough hyperparameter optimization and the potential benefits of diffusion-based models. The study also suggests areas for further research, such as exploring a wider range of model families and investigating the generalization of the findings to additional datasets and real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Under the Hood of Tabular Data Generation Models: the Strong Impact of Hyperparameter Tuning
G. Charbel N. Kindji (LACODAM), Lina Maria Rojas-Barahona (LACODAM), Elisa Fromont (LACODAM), Tanguy Urvoy
We investigate the impact of dataset-specific hyperparameter, feature encoding, and architecture tuning on five recent model families for tabular data generation through an extensive benchmark on 16 datasets. This study addresses the practical need for a unified evaluation of models that fully considers hyperparameter optimization. Additionally, we propose a reduced search space for each model that allows for quick optimization, achieving nearly equivalent performance at a significantly lower cost.Our benchmark demonstrates that, for most models, large-scale dataset-specific tuning substantially improves performance compared to the original configurations. Furthermore, we confirm that diffusion-based models generally outperform other models on tabular data. However, this advantage is not significant when the entire tuning and training process is restricted to the same GPU budget for all models.
Read more7/15/2024
👁️
0
A Comparative Study of Hyperparameter Tuning Methods
Subhasis Dasgupta, Jaydip Sen
The study emphasizes the challenge of finding the optimal trade-off between bias and variance, especially as hyperparameter optimization increases in complexity. Through empirical analysis, three hyperparameter tuning algorithms Tree-structured Parzen Estimator (TPE), Genetic Search, and Random Search are evaluated across regression and classification tasks. The results show that nonlinear models, with properly tuned hyperparameters, significantly outperform linear models. Interestingly, Random Search excelled in regression tasks, while TPE was more effective for classification tasks. This suggests that there is no one-size-fits-all solution, as different algorithms perform better depending on the task and model type. The findings underscore the importance of selecting the appropriate tuning method and highlight the computational challenges involved in optimizing machine learning models, particularly as search spaces expand.
Read more8/30/2024

0
A Data-Centric Perspective on Evaluating Machine Learning Models for Tabular Data
Andrej Tschalzev, Sascha Marton, Stefan Ludtke, Christian Bartelt, Heiner Stuckenschmidt
Tabular data is prevalent in real-world machine learning applications, and new models for supervised learning of tabular data are frequently proposed. Comparative studies assessing the performance of models typically consist of model-centric evaluation setups with overly standardized data preprocessing. This paper demonstrates that such model-centric evaluations are biased, as real-world modeling pipelines often require dataset-specific preprocessing and feature engineering. Therefore, we propose a data-centric evaluation framework. We select 10 relevant datasets from Kaggle competitions and implement expert-level preprocessing pipelines for each dataset. We conduct experiments with different preprocessing pipelines and hyperparameter optimization (HPO) regimes to quantify the impact of model selection, HPO, feature engineering, and test-time adaptation. Our main findings are: 1. After dataset-specific feature engineering, model rankings change considerably, performance differences decrease, and the importance of model selection reduces. 2. Recent models, despite their measurable progress, still significantly benefit from manual feature engineering. This holds true for both tree-based models and neural networks. 3. While tabular data is typically considered static, samples are often collected over time, and adapting to distribution shifts can be important even in supposedly static data. These insights suggest that research efforts should be directed toward a data-centric perspective, acknowledging that tabular data requires feature engineering and often exhibits temporal characteristics. Our framework is available under: https://github.com/atschalz/dc_tabeval.
Read more8/27/2024
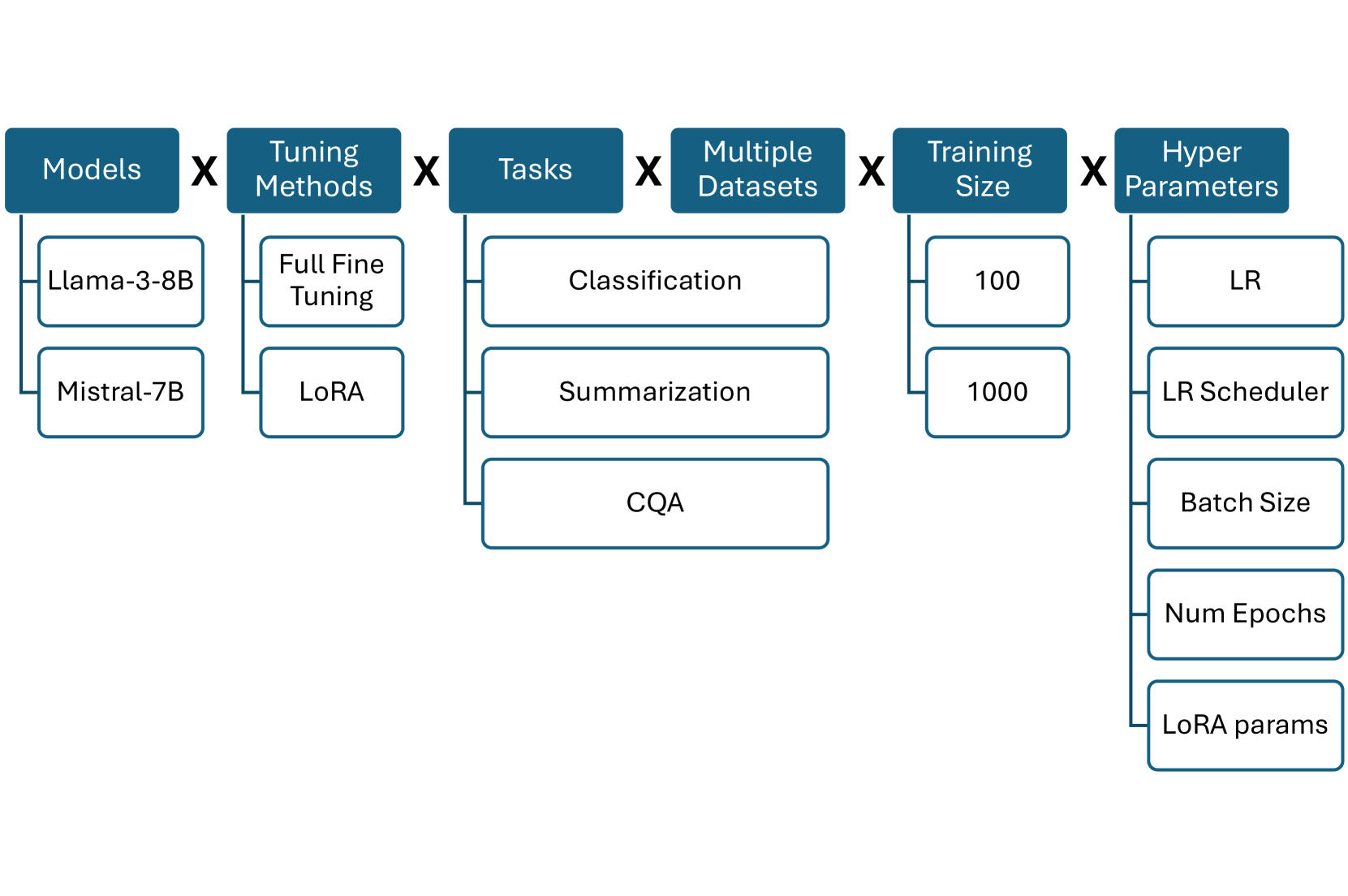
0
Stay Tuned: An Empirical Study of the Impact of Hyperparameters on LLM Tuning in Real-World Applications
Alon Halfon, Shai Gretz, Ofir Arviv, Artem Spector, Orith Toledo-Ronen, Yoav Katz, Liat Ein-Dor, Michal Shmueli-Scheuer, Noam Slonim
Fine-tuning Large Language Models (LLMs) is an effective method to enhance their performance on downstream tasks. However, choosing the appropriate setting of tuning hyperparameters (HPs) is a labor-intensive and computationally expensive process. Here, we provide recommended HP configurations for practical use-cases that represent a better starting point for practitioners, when considering two SOTA LLMs and two commonly used tuning methods. We describe Coverage-based Search (CBS), a process for ranking HP configurations based on an offline extensive grid search, such that the top ranked configurations collectively provide a practical robust recommendation for a wide range of datasets and domains. We focus our experiments on Llama-3-8B and Mistral-7B, as well as full fine-tuning and LoRa, conducting a total of > 10,000 tuning experiments. Our results suggest that, in general, Llama-3-8B and LoRA should be preferred, when possible. Moreover, we show that for both models and tuning methods, exploring only a few HP configurations, as recommended by our analysis, can provide excellent results in practice, making this work a valuable resource for practitioners.
Read more8/9/2024