Rethinking Processing Distortions: Disentangling the Impact of Speech Enhancement Errors on Speech Recognition Performance
2404.14860
0
0
⚙️
Abstract
It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with a single-channel speech enhancement (SE) front-end. This is generally attributed to the processing distortions caused by the nonlinear processing of single-channel SE front-ends. However, the causes of such degraded ASR performance have not been fully investigated. How to design single-channel SE front-ends in a way that significantly improves ASR performance remains an open research question. In this study, we investigate a signal-level numerical metric that can explain the cause of degradation in ASR performance. To this end, we propose a novel analysis scheme based on the orthogonal projection-based decomposition of SE errors. This scheme manually modifies the ratio of the decomposed interference, noise, and artifact errors, and it enables us to directly evaluate the impact of each error type on ASR performance. Our analysis reveals the particularly detrimental effect of artifact errors on ASR performance compared to the other types of errors. This provides us with a more principled definition of processing distortions that cause the ASR performance degradation. Then, we study two practical approaches for reducing the impact of artifact errors. First, we prove that the simple observation adding (OA) post-processing (i.e., interpolating the enhanced and observed signals) can monotonically improve the signal-to-artifact ratio. Second, we propose a novel training objective, called artifact-boosted signal-to-distortion ratio (AB-SDR), which forces the model to estimate the enhanced signals with fewer artifact errors. Through experiments, we confirm that both the OA and AB-SDR approaches are effective in decreasing artifact errors caused by single-channel SE front-ends, allowing them to significantly improve ASR performance.
Create account to get full access
Overview
- The paper investigates the impact of different types of errors in single-channel speech enhancement (SE) front-ends on the performance of automatic speech recognition (ASR) systems.
- It proposes a novel analysis scheme based on orthogonal projection-based decomposition of SE errors to quantify the effect of interference, noise, and artifact errors on ASR performance.
- The analysis reveals that artifact errors have a particularly detrimental effect on ASR performance.
- The paper then explores two practical approaches to reduce the impact of artifact errors: observation adding (OA) post-processing and artifact-boosted signal-to-distortion ratio (AB-SDR) training objective.
Plain English Explanation
Automatic speech recognition (ASR) systems, which convert spoken language into text, often struggle to perform well in noisy environments. This is typically due to the distortions introduced by the speech enhancement (SE) front-end, which is responsible for cleaning up the audio signal before it reaches the ASR system.
However, the exact reasons for this performance degradation have not been fully understood. This paper aims to shed light on the issue by breaking down the different types of errors that can occur in the SE process and analyzing their individual impact on ASR performance.
The researchers developed a novel analysis technique that allows them to isolate and measure the effects of interference (unwanted sounds), noise, and artifact errors (distortions introduced by the SE algorithm itself). Their analysis revealed that artifact errors are particularly problematic for ASR, more so than the other error types.
Armed with this insight, the researchers explored two practical approaches to address the artifact error problem. The first involves a simple post-processing step that blends the enhanced audio with the original noisy signal, which helps to reduce artifact errors. The second approach involves modifying the training objective of the SE algorithm to explicitly minimize artifact errors, a technique they call artifact-boosted signal-to-distortion ratio (AB-SDR).
Through experiments, the researchers demonstrated that both of these methods were effective in improving ASR performance by mitigating the impact of artifact errors in the SE front-end.
Technical Explanation
The paper starts by noting the challenge of improving ASR performance in noisy conditions using a single-channel SE front-end. This is attributed to the processing distortions caused by the nonlinear processing of single-channel SE algorithms, but the exact causes have not been fully investigated.
To address this, the researchers propose a novel analysis scheme based on orthogonal projection-based decomposition of SE errors. This scheme manually modifies the ratio of interference, noise, and artifact errors, allowing the researchers to directly evaluate the impact of each error type on ASR performance.
The analysis reveals that artifact errors have a particularly detrimental effect on ASR performance compared to the other error types. This provides a more principled definition of the "processing distortions" that cause ASR performance degradation.
The paper then explores two practical approaches to reduce the impact of artifact errors. First, the researchers prove that a simple observation adding (OA) post-processing technique, which interpolates the enhanced and observed signals, can monotonically improve the signal-to-artifact ratio.
Second, the researchers propose a novel training objective called artifact-boosted signal-to-distortion ratio (AB-SDR), which forces the SE model to estimate enhanced signals with fewer artifact errors.
Through experiments, the paper confirms that both the OA and AB-SDR approaches are effective in decreasing artifact errors caused by single-channel SE front-ends, allowing them to significantly improve ASR performance.
Critical Analysis
The paper provides a thoughtful and systematic analysis of the impact of different types of errors in single-channel SE on ASR performance. The proposed orthogonal projection-based decomposition scheme is a novel and insightful approach to isolating and quantifying the effects of interference, noise, and artifact errors.
One potential limitation of the study is that it focuses solely on single-channel SE, which may not fully capture the challenges of more complex multi-channel scenarios. Additionally, the paper does not explore the potential trade-offs between reducing artifact errors and preserving other important signal characteristics.
Further research could investigate the generalizability of the findings to different SE algorithms, ASR models, and real-world noisy environments. Exploring the underlying causes of artifact errors and developing more advanced techniques to mitigate them could also be fruitful avenues for future work.
Conclusion
This paper provides a valuable contribution to the understanding of the relationship between single-channel speech enhancement and automatic speech recognition performance. By revealing the particularly detrimental impact of artifact errors, the study offers important insights that can guide the development of more effective SE algorithms and ASR systems, especially in challenging noisy conditions.
The proposed approaches of observation adding post-processing and artifact-boosted training objectives demonstrate practical solutions to this problem, paving the way for improved real-world deployment of ASR technology. Overall, this research represents an important step forward in addressing a longstanding challenge in the field of speech processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Flexible Multichannel Speech Enhancement for Noise-Robust Frontend
Ante Juki'c, Jagadeesh Balam, Boris Ginsburg
0
0
This paper proposes a flexible multichannel speech enhancement system with the main goal of improving robustness of automatic speech recognition (ASR) in noisy conditions. The proposed system combines a flexible neural mask estimator applicable to different channel counts and configurations and a multichannel filter with automatic reference selection. A transform-attend-concatenate layer is proposed to handle cross-channel information in the mask estimator, which is shown to be effective for arbitrary microphone configurations. The presented evaluation demonstrates the effectiveness of the flexible system for several seen and unseen compact array geometries, matching the performance of fixed configuration-specific systems. Furthermore, a significantly improved ASR performance is observed for configurations with randomly-placed microphones.
6/10/2024
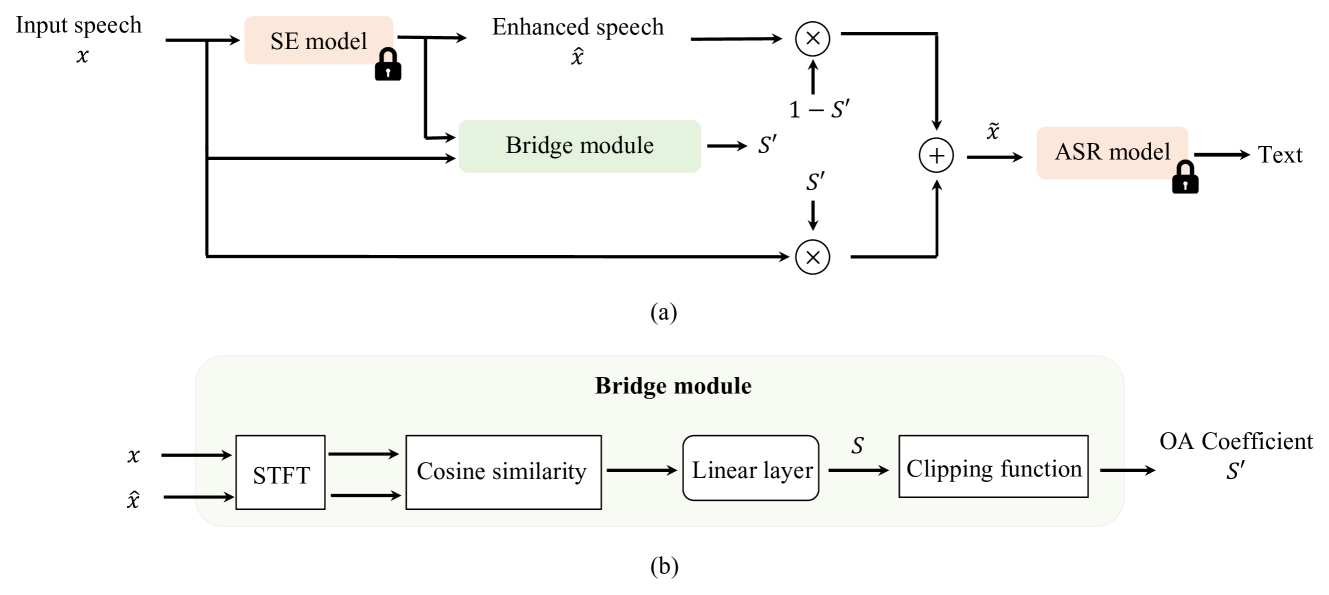
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
0
0
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
6/19/2024
📈
Exploring the Potential of Data-Driven Spatial Audio Enhancement Using a Single-Channel Model
Arthur N. dos Santos, Bruno S. Masiero, T'ulio C. L. Mateus
0
0
One key aspect differentiating data-driven single- and multi-channel speech enhancement and dereverberation methods is that both the problem formulation and complexity of the solutions are considerably more challenging in the latter case. Additionally, with limited computational resources, it is cumbersome to train models that require the management of larger datasets or those with more complex designs. In this scenario, an unverified hypothesis that single-channel methods can be adapted to multi-channel scenarios simply by processing each channel independently holds significant implications, boosting compatibility between sound scene capture and system input-output formats, while also allowing modern research to focus on other challenging aspects, such as full-bandwidth audio enhancement, competitive noise suppression, and unsupervised learning. This study verifies this hypothesis by comparing the enhancement promoted by a basic single-channel speech enhancement and dereverberation model with two other multi-channel models tailored to separate clean speech from noisy 3D mixes. A direction of arrival estimation model was used to objectively evaluate its capacity to preserve spatial information by comparing the output signals with ground-truth coordinate values. Consequently, a trade-off arises between preserving spatial information with a more straightforward single-channel solution at the cost of obtaining lower gains in intelligibility scores.
4/24/2024
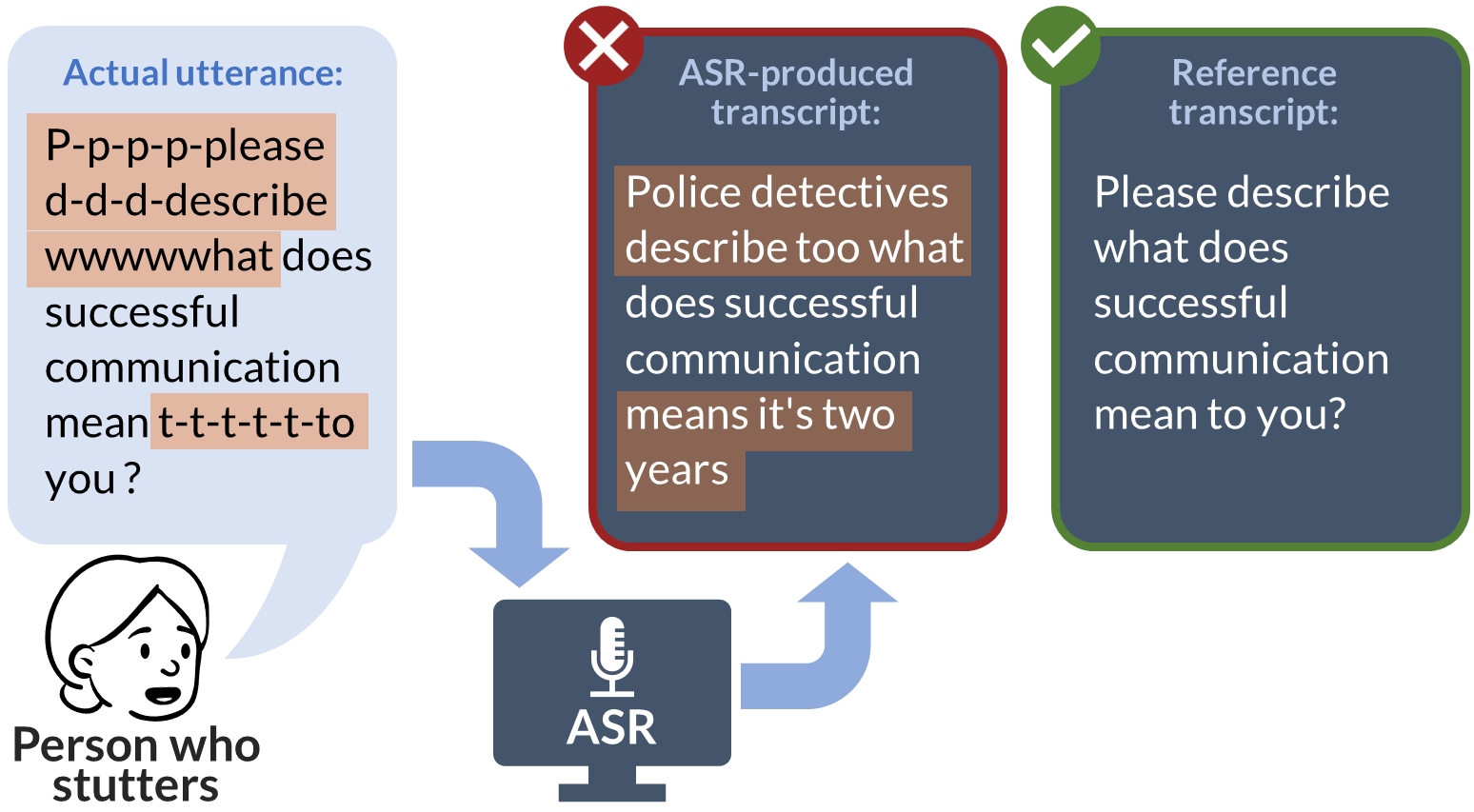
Lost in Transcription: Identifying and Quantifying the Accuracy Biases of Automatic Speech Recognition Systems Against Disfluent Speech
Dena Mujtaba, Nihar R. Mahapatra, Megan Arney, J. Scott Yaruss, Hope Gerlach-Houck, Caryn Herring, Jia Bin
0
0
Automatic speech recognition (ASR) systems, increasingly prevalent in education, healthcare, employment, and mobile technology, face significant challenges in inclusivity, particularly for the 80 million-strong global community of people who stutter. These systems often fail to accurately interpret speech patterns deviating from typical fluency, leading to critical usability issues and misinterpretations. This study evaluates six leading ASRs, analyzing their performance on both a real-world dataset of speech samples from individuals who stutter and a synthetic dataset derived from the widely-used LibriSpeech benchmark. The synthetic dataset, uniquely designed to incorporate various stuttering events, enables an in-depth analysis of each ASR's handling of disfluent speech. Our comprehensive assessment includes metrics such as word error rate (WER), character error rate (CER), and semantic accuracy of the transcripts. The results reveal a consistent and statistically significant accuracy bias across all ASRs against disfluent speech, manifesting in significant syntactical and semantic inaccuracies in transcriptions. These findings highlight a critical gap in current ASR technologies, underscoring the need for effective bias mitigation strategies. Addressing this bias is imperative not only to improve the technology's usability for people who stutter but also to ensure their equitable and inclusive participation in the rapidly evolving digital landscape.
5/13/2024