RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation

0

Sign in to get full access
Overview
- The paper "RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation" explores a novel approach to improving the performance of Monte Carlo Tree Search (MCTS) algorithms for code generation tasks.
- The key idea is to incorporate a "rethinking" mechanism that allows the algorithm to identify and correct erroneous thoughts or decisions during the search process.
- This can lead to more efficient and effective code generation, with potential applications in areas like program synthesis and intelligent assistance for software development.
Plain English Explanation
The paper focuses on a technique called [object Object], which is a powerful algorithm used for decision-making in complex environments. MCTS is particularly useful for tasks like code generation, where the search space is vast and traditional methods may struggle.
However, the authors of this paper noticed that MCTS can sometimes make "erroneous thoughts" or incorrect decisions during the search process. To address this, they developed a new approach called RethinkMCTS, which allows the algorithm to identify and correct these mistakes as it explores the search space.
The key idea behind RethinkMCTS is to introduce a "rethinking" mechanism that can analyze the algorithm's current thoughts and decisions, and then make adjustments to improve the search process. This can lead to more accurate and efficient code generation, as the algorithm is able to learn from its mistakes and refine its approach over time.
The authors tested their RethinkMCTS approach on a variety of code generation tasks and found that it outperformed traditional MCTS algorithms, particularly in cases where the search space was complex or challenging. This suggests that the "rethinking" mechanism can be a valuable addition to MCTS-based systems, with potential applications in areas like program synthesis, intelligent code assistants, and other AI-powered software development tools.
Technical Explanation
The paper introduces a novel approach called RethinkMCTS, which extends the traditional [object Object] algorithm to better handle erroneous thoughts or decisions during the code generation process.
The core idea of RethinkMCTS is to incorporate a "rethinking" mechanism that allows the algorithm to analyze its current state and identify potential errors or suboptimal choices. This rethinking process involves several key steps:
- Thought Evaluation: The algorithm evaluates the quality of its current thoughts or decisions by considering factors such as the expected reward, the uncertainty of the outcome, and the overall coherence of the search path.
- Erroneous Thought Identification: Based on the thought evaluation, the algorithm identifies any thoughts or decisions that are considered erroneous or suboptimal.
- Thought Revision: The algorithm then revises the erroneous thoughts, either by modifying the current search path or by exploring alternative paths that may lead to better outcomes.
The authors hypothesize that this rethinking mechanism can help the MCTS algorithm overcome the limitations of traditional approaches, which may get stuck in suboptimal regions of the search space or make decisions that lead to poor code generation outcomes.
To evaluate the effectiveness of RethinkMCTS, the authors conducted experiments on a range of code generation tasks, comparing the performance of their approach against traditional MCTS and other state-of-the-art methods. The results showed that RethinkMCTS consistently outperformed the baseline algorithms, particularly in scenarios where the search space was complex or the optimal solution was difficult to find.
The authors attribute the success of RethinkMCTS to its ability to identify and correct erroneous thoughts during the search process, allowing the algorithm to explore more promising regions of the search space and generate higher-quality code. This suggests that the "rethinking" mechanism can be a valuable addition to MCTS-based systems, with potential applications in a variety of AI-powered software development tools and program synthesis tasks.
Critical Analysis
The RethinkMCTS approach presented in the paper addresses an important challenge in the field of code generation, where traditional MCTS algorithms can struggle to navigate the complex search space and overcome suboptimal decisions.
One of the key strengths of the RethinkMCTS approach is its ability to identify and correct erroneous thoughts or decisions during the search process. This "rethinking" mechanism allows the algorithm to learn from its mistakes and continuously improve its performance, which can be particularly valuable in domains where the optimal solution is not always clear or easy to find.
However, the paper also acknowledges several limitations and areas for further research:
- Computational Complexity: The addition of the rethinking mechanism may introduce additional computational overhead, which could impact the real-time performance of the algorithm, particularly in time-sensitive applications.
- Generalization: The authors note that the effectiveness of RethinkMCTS may depend on the specific characteristics of the code generation task and the underlying search space. Further research may be needed to understand the broader applicability of the approach and its ability to generalize to a wider range of problems.
- Interpretability: The paper does not provide a detailed explanation of how the rethinking mechanism works or how it identifies and corrects erroneous thoughts. Improving the interpretability of the approach could help developers and users better understand its inner workings and potential biases.
Additionally, while the paper presents promising results, it would be valuable to see further validation and testing of the RethinkMCTS approach, perhaps in collaboration with industry partners or on real-world code generation tasks. This could help to uncover additional challenges or limitations that were not addressed in the current study.
Overall, the RethinkMCTS approach represents an interesting and potentially impactful contribution to the field of code generation and AI-powered software development. The "rethinking" mechanism offers a novel way to address the limitations of traditional MCTS algorithms, and the authors have demonstrated its effectiveness through rigorous experimentation. However, further research and refinement may be needed to fully realize the potential of this approach and ensure its broader applicability and usability.
Conclusion
The paper "RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation" presents a new approach to improving the performance of MCTS algorithms for code generation tasks. The key innovation is the introduction of a "rethinking" mechanism that allows the algorithm to identify and correct erroneous thoughts or decisions during the search process.
The authors' experiments demonstrate that the RethinkMCTS approach outperforms traditional MCTS and other state-of-the-art methods, particularly in complex or challenging code generation scenarios. This suggests that the "rethinking" mechanism can be a valuable addition to MCTS-based systems, with potential applications in areas like program synthesis, intelligent code assistants, and other AI-powered software development tools.
While the paper acknowledges some limitations and areas for further research, the RethinkMCTS approach represents an important step forward in the ongoing efforts to develop more effective and reliable code generation algorithms. By incorporating a "rethinking" mechanism, the algorithm can learn from its mistakes and continuously refine its approach, leading to more efficient and accurate code generation outcomes.
As the field of AI-powered software development continues to evolve, research like this will play a crucial role in advancing the state of the art and unlocking new possibilities for how we create and interact with code. The insights and techniques presented in this paper could serve as a foundation for future innovations in this rapidly growing and increasingly important domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation
Qingyao Li, Wei Xia, Kounianhua Du, Xinyi Dai, Ruiming Tang, Yasheng Wang, Yong Yu, Weinan Zhang
LLM agents enhanced by tree search algorithms have yielded notable performances in code generation. However, current search algorithms in this domain suffer from low search quality due to several reasons: 1) Ineffective design of the search space for the high-reasoning demands of code generation tasks, 2) Inadequate integration of code feedback with the search algorithm, and 3) Poor handling of negative feedback during the search, leading to reduced search efficiency and quality. To address these challenges, we propose to search for the reasoning process of the code and use the detailed feedback of code execution to refine erroneous thoughts during the search. In this paper, we introduce RethinkMCTS, which employs the Monte Carlo Tree Search (MCTS) algorithm to conduct thought-level searches before generating code, thereby exploring a wider range of strategies. More importantly, we construct verbal feedback from fine-grained code execution feedback to refine erroneous thoughts during the search. This ensures that the search progresses along the correct reasoning paths, thus improving the overall search quality of the tree by leveraging execution feedback. Through extensive experiments, we demonstrate that RethinkMCTS outperforms previous search-based and feedback-based code generation baselines. On the HumanEval dataset, it improves the pass@1 of GPT-3.5-turbo from 70.12 to 89.02 and GPT-4o-mini from 87.20 to 94.51. It effectively conducts more thorough exploration through thought-level searches and enhances the search quality of the entire tree by incorporating rethink operation.
Read more9/17/2024

0
THOUGHTSCULPT: Reasoning with Intermediate Revision and Search
Yizhou Chi, Kevin Yang, Dan Klein
We present THOUGHTSCULPT, a general reasoning and search method for tasks with outputs that can be decomposed into components. THOUGHTSCULPT explores a search tree of potential solutions using Monte Carlo Tree Search (MCTS), building solutions one action at a time and evaluating according to any domain-specific heuristic, which in practice is often simply an LLM evaluator. Critically, our action space includes revision actions: THOUGHTSCULPT may choose to revise part of its previous output rather than continuing to build the rest of its output. Empirically, THOUGHTSCULPT outperforms state-of-the-art reasoning methods across three challenging tasks: Story Outline Improvement (up to +30% interestingness), Mini-Crosswords Solving (up to +16% word success rate), and Constrained Generation (up to +10% concept coverage).
Read more4/10/2024
🔎
0
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8%$ (+$5.9%$), $34.7%$ (+$5.8%$), and $76.4%$ (+$15.8%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
Read more6/19/2024
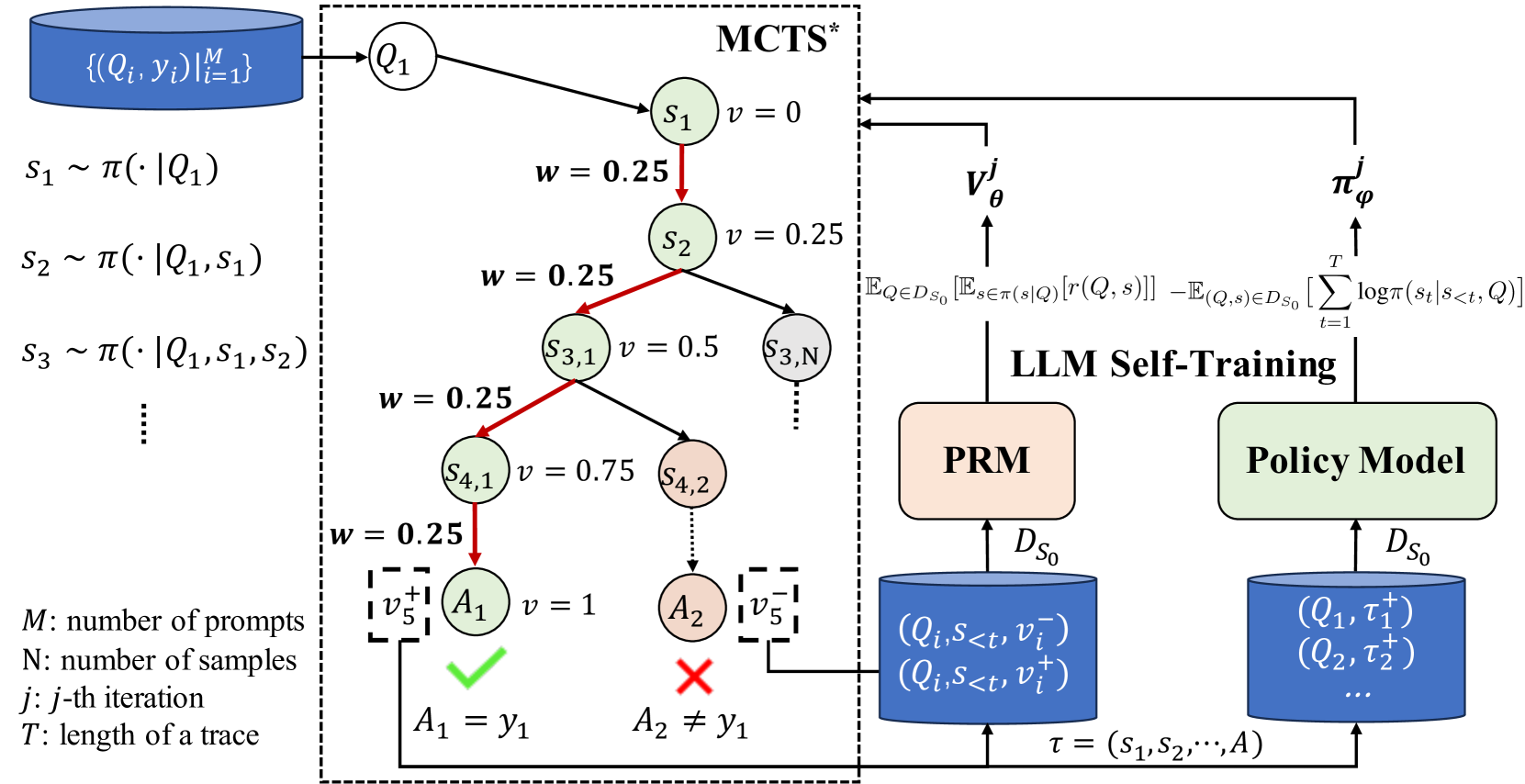
0
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, Jie Tang
Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^text{EM}$ and Self-Rewarding LM.
Read more9/4/2024