THOUGHTSCULPT: Reasoning with Intermediate Revision and Search
2404.05966
0
0

Abstract
We present THOUGHTSCULPT, a general reasoning and search method for tasks with outputs that can be decomposed into components. THOUGHTSCULPT explores a search tree of potential solutions using Monte Carlo Tree Search (MCTS), building solutions one action at a time and evaluating according to any domain-specific heuristic, which in practice is often simply an LLM evaluator. Critically, our action space includes revision actions: THOUGHTSCULPT may choose to revise part of its previous output rather than continuing to build the rest of its output. Empirically, THOUGHTSCULPT outperforms state-of-the-art reasoning methods across three challenging tasks: Story Outline Improvement (up to +30% interestingness), Mini-Crosswords Solving (up to +16% word success rate), and Constrained Generation (up to +10% concept coverage).
Create account to get full access
Overview
- This paper presents a novel method called \methodname that aims to improve the reasoning capabilities of large language models through an iterative process of intermediate revision and search.
- \methodname employs a feedback-guided generation approach, where the model revises its initial output based on feedback from a reasoning module, and then iteratively searches for a better solution.
- The researchers demonstrate the effectiveness of \methodname on a range of reasoning tasks, including internal link solving math word problems, internal link playing the game of Werewolf, and internal link spatial reasoning.
Plain English Explanation
The paper introduces a new approach called \methodname that aims to help large language models (LLMs) become better at reasoning and problem-solving. The key idea is to have the model go through an iterative process of revising its initial output and searching for a better solution, guided by feedback from a specialized reasoning module.
Imagine you're trying to solve a complex math word problem. With \methodname, the model would first take a guess at the solution, then get feedback on how to improve it. It would then revise its answer and keep searching until it finds the best solution. This feedback-guided generation approach helps the model learn to reason more effectively, rather than just relying on its initial output.
The researchers show that \methodname can improve the performance of LLMs on a variety of reasoning tasks, from internal link solving math problems to internal link playing the game of Werewolf and internal link reasoning about spatial relationships. This suggests that the iterative revision and search process can help LLMs develop more robust reasoning capabilities.
Technical Explanation
The \methodname approach is centered around a feedback-guided generation process. The model first generates an initial output for a given reasoning task, which is then evaluated by a specialized reasoning module. Based on the feedback from this module, the model revises its output and continues to search for a better solution through an iterative process.
The reasoning module acts as a guide, providing the model with information about the strengths and weaknesses of its current solution. This allows the model to focus its search on more promising areas and gradually refine its reasoning abilities. The researchers demonstrate the effectiveness of \methodname on a range of tasks, including internal link solving math word problems, internal link playing the game of Werewolf, and internal link spatial reasoning.
The architecture of \methodname involves a language model, a reasoning module, and a search module. The language model generates the initial output, which is then evaluated by the reasoning module. Based on the feedback, the search module explores alternative solutions, and the process continues until a satisfactory result is found.
The researchers also explore the use of internal link soft prompting and internal link language model as compiler techniques to further enhance the reasoning capabilities of \methodname.
Critical Analysis
The \methodname approach represents an important step forward in improving the reasoning capabilities of large language models. By incorporating a feedback-guided revision and search process, the model can learn to reason more effectively, rather than relying solely on its initial output.
However, the paper does not address potential limitations or challenges that may arise when deploying \methodname in real-world scenarios. For example, the computational cost of the iterative revision and search process may be prohibitive for certain applications, and the performance of the reasoning module itself may be a critical factor in the overall effectiveness of the approach.
Additionally, the paper does not explore the generalizability of \methodname beyond the specific tasks presented. It would be valuable to understand how well the method can be applied to a wider range of reasoning problems, including those that may require more complex or nuanced reasoning.
Overall, the \methodname approach is a promising step forward, but further research is needed to fully understand its capabilities, limitations, and potential applications in the field of large language model reasoning.
Conclusion
The \methodname method presented in this paper represents a significant advancement in the field of large language model reasoning. By incorporating a feedback-guided revision and search process, the model can learn to reason more effectively, outperforming traditional language models on a range of tasks.
The potential implications of \methodname are wide-ranging, from enhancing the problem-solving capabilities of AI assistants to improving the accuracy and reliability of language-based decision support systems. As the field of large language models continues to evolve, techniques like \methodname will play an increasingly important role in unlocking the full potential of these powerful language models.
While the paper highlights the promising results of \methodname, further research is needed to fully understand its limitations and explore its broader applicability. Nevertheless, the approach represents an important step forward in the ongoing quest to develop AI systems that can reason and solve problems with the same level of sophistication as humans.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
0
0
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8%$ (+$5.9%$), $34.7%$ (+$5.8%$), and $76.4%$ (+$15.8%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
6/19/2024
🔍
Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models
Bilgehan Sel, Ahmad Al-Tawaha, Vanshaj Khattar, Ruoxi Jia, Ming Jin
0
0
Current literature, aiming to surpass the Chain-of-Thought approach, often resorts to external modi operandi involving halting, modifying, and then resuming the generation process to boost Large Language Models' (LLMs) reasoning capacities. Due to their myopic perspective, they escalate the number of query requests, leading to increased costs, memory, and computational overheads. Addressing this, we propose the Algorithm of Thoughts -- a novel strategy that propels LLMs through algorithmic reasoning pathways. By employing algorithmic examples fully in-context, this overarching view of the whole process exploits the innate recurrence dynamics of LLMs, expanding their idea exploration with merely one or a few queries. Our technique outperforms earlier single-query methods and even more recent multi-query strategies that employ an extensive tree search algorithms while using significantly fewer tokens. Intriguingly, our results suggest that instructing an LLM using an algorithm can lead to performance surpassing that of the algorithm itself, hinting at LLM's inherent ability to weave its intuition into optimized searches. We probe into the underpinnings of our method's efficacy and its nuances in application. The code and related content can be found in: https://algorithm-of-thoughts.github.io.
6/4/2024
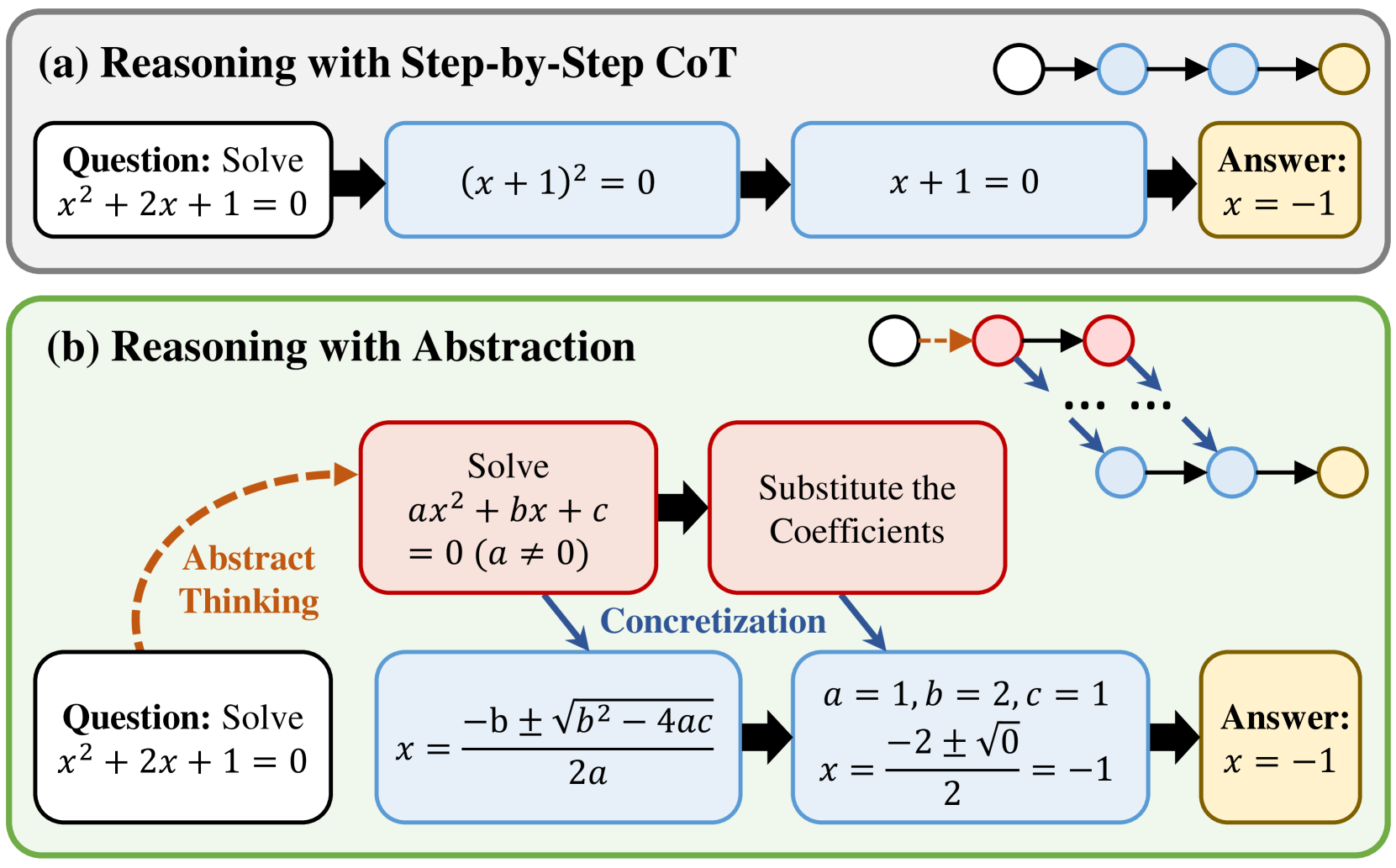
Abstraction-of-Thought Makes Language Models Better Reasoners
Ruixin Hong, Hongming Zhang, Xiaoman Pan, Dong Yu, Changshui Zhang
0
0
Abstract reasoning, the ability to reason from the abstract essence of a problem, serves as a key to generalization in human reasoning. However, eliciting language models to perform reasoning with abstraction remains unexplored. This paper seeks to bridge this gap by introducing a novel structured reasoning format called Abstraction-of-Thought (AoT). The uniqueness of AoT lies in its explicit requirement for varying levels of abstraction within the reasoning process. This approach could elicit language models to first contemplate on the abstract level before incorporating concrete details, which is overlooked by the prevailing step-by-step Chain-of-Thought (CoT) method. To align models with the AoT format, we present AoT Collection, a generic finetuning dataset consisting of 348k high-quality samples with AoT reasoning processes, collected via an automated and scalable pipeline. We finetune a wide range of language models with AoT Collection and conduct extensive evaluations on 23 unseen tasks from the challenging benchmark Big-Bench Hard. Experimental results indicate that models aligned to AoT reasoning format substantially outperform those aligned to CoT in many reasoning tasks.
6/19/2024

Efficient Monte Carlo Tree Search via On-the-Fly State-Conditioned Action Abstraction
Yunhyeok Kwak, Inwoo Hwang, Dooyoung Kim, Sanghack Lee, Byoung-Tak Zhang
0
0
Monte Carlo Tree Search (MCTS) has showcased its efficacy across a broad spectrum of decision-making problems. However, its performance often degrades under vast combinatorial action space, especially where an action is composed of multiple sub-actions. In this work, we propose an action abstraction based on the compositional structure between a state and sub-actions for improving the efficiency of MCTS under a factored action space. Our method learns a latent dynamics model with an auxiliary network that captures sub-actions relevant to the transition on the current state, which we call state-conditioned action abstraction. Notably, it infers such compositional relationships from high-dimensional observations without the known environment model. During the tree traversal, our method constructs the state-conditioned action abstraction for each node on-the-fly, reducing the search space by discarding the exploration of redundant sub-actions. Experimental results demonstrate the superior sample efficiency of our method compared to vanilla MuZero, which suffers from expansive action space.
6/4/2024