Retrieval Augmented Structured Generation: Business Document Information Extraction As Tool Use

0

Sign in to get full access
Overview
- The paper proposes a novel approach called "Retrieval Augmented Structured Generation" for business document information extraction.
- It aims to address the challenges of key information extraction, line item recognition, and table detection in business documents.
- The approach leverages large language models and retrieval-based techniques to enhance the performance of structured generation tasks.
Plain English Explanation
Retrieval Augmented Generation Based Relation Extraction is a technique that can help computers better understand and extract important information from business documents. Business documents, like invoices or contracts, often contain crucial details like line items, tables, and key details that are important for companies to track and analyze.
However, automatically extracting this information can be challenging, as business documents can be complex and vary a lot in their structure and formatting. This paper proposes a new approach that combines large language models, which are AI systems trained on vast amounts of text data, with retrieval-based techniques.
The key idea is to have the language model not just generate the extracted information, but to also search through a database of similar documents to find relevant information that can help it make better predictions. This "retrieval augmented" approach allows the system to leverage past experience and knowledge to improve its understanding and extraction of important details from new business documents.
By combining powerful language models with retrieval-based techniques, this approach aims to be more accurate and robust at extracting crucial information from complex business documents, compared to previous methods. This could be very useful for automating many business processes that currently require a lot of manual effort.
Technical Explanation
The paper introduces a "Retrieval Augmented Structured Generation" (RASG) approach for business document information extraction. RASG builds upon the insights from LLMs Know What They Need: Leveraging Missing Knowledge for Zero-Shot Task Generalization and Empowering Large Language Models to Set Up and Solve NLP Tasks, which showed that large language models (LLMs) can leverage retrieval to complement their knowledge and improve performance on downstream tasks.
The key components of RASG include:
-
Retrieval Module: This module retrieves the most relevant documents from a database given the input business document. The retrieved documents can provide useful context and supplementary information to aid the extraction task.
-
Generation Module: This module takes the input document and the retrieved relevant documents and generates the structured output, such as extracted line items, tables, and key information.
The authors also introduce a novel BIDER technique to efficiently bridge the knowledge gap between the language model and the retrieval module, further enhancing the performance of the RASG approach.
The paper evaluates RASG on several business document information extraction tasks, including line item recognition, table detection, and key information extraction. The results show that the retrieval-augmented approach outperforms strong baseline models, demonstrating the benefits of leveraging retrieved relevant documents to improve structured generation performance.
Critical Analysis
The paper presents a well-designed and promising approach for business document information extraction. The key strength of the work is the integration of retrieval-based techniques with large language models, which allows the system to leverage broader context and knowledge beyond what is contained in the input document alone.
However, the paper also acknowledges some limitations and areas for further research. For example, the retrieval module relies on a pre-existing database of documents, which may not always be available in practical scenarios. The authors suggest exploring "open-set" retrieval techniques to address this limitation.
Additionally, the paper focuses on specific business document extraction tasks, and it would be interesting to see how the RASG approach could be generalized to handle a wider range of document types and extraction tasks. Improving Medical Reasoning Through Retrieval & Self-Reflection explored similar ideas in the context of medical text, which could provide useful insights.
Overall, the Retrieval Augmented Structured Generation approach represents an important step forward in the field of document information extraction. By seamlessly integrating retrieval and generation techniques, the authors have demonstrated the potential to significantly improve the accuracy and robustness of extracting crucial information from complex business documents.
Conclusion
The "Retrieval Augmented Structured Generation" paper proposes an innovative approach to address the challenges of business document information extraction, such as key information extraction, line item recognition, and table detection. By leveraging large language models and retrieval-based techniques, the RASG system can leverage broader context and knowledge to generate more accurate and structured outputs.
The results presented in the paper are promising and demonstrate the benefits of the retrieval-augmented approach. While the current implementation has some limitations, the underlying ideas could have far-reaching implications for automating and streamlining various business processes that rely on extracting information from complex documents.
As the field of document understanding continues to evolve, techniques like RASG that blend language models, retrieval, and structured generation could become increasingly important for unlocking the full potential of AI-powered document processing and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Retrieval Augmented Structured Generation: Business Document Information Extraction As Tool Use
Franz Louis Cesista, Rui Aguiar, Jason Kim, Paolo Acilo
Business Document Information Extraction (BDIE) is the problem of transforming a blob of unstructured information (raw text, scanned documents, etc.) into a structured format that downstream systems can parse and use. It has two main tasks: Key-Information Extraction (KIE) and Line Items Recognition (LIR). In this paper, we argue that BDIE is best modeled as a Tool Use problem, where the tools are these downstream systems. We then present Retrieval Augmented Structured Generation (RASG), a novel general framework for BDIE that achieves state of the art (SOTA) results on both KIE and LIR tasks on BDIE benchmarks. The contributions of this paper are threefold: (1) We show, with ablation benchmarks, that Large Language Models (LLMs) with RASG are already competitive with or surpasses current SOTA Large Multimodal Models (LMMs) without RASG on BDIE benchmarks. (2) We propose a new metric class for Line Items Recognition, General Line Items Recognition Metric (GLIRM), that is more aligned with practical BDIE use cases compared to existing metrics, such as ANLS*, DocILE, and GriTS. (3) We provide a heuristic algorithm for backcalculating bounding boxes of predicted line items and tables without the need for vision encoders. Finally, we claim that, while LMMs might sometimes offer marginal performance benefits, LLMs + RASG is oftentimes superior given real-world applications and constraints of BDIE.
Read more5/31/2024

0
Retrieval-Augmented Generation-based Relation Extraction
Sefika Efeoglu, Adrian Paschke
Information Extraction (IE) is a transformative process that converts unstructured text data into a structured format by employing entity and relation extraction (RE) methodologies. The identification of the relation between a pair of entities plays a crucial role within this framework. Despite the existence of various techniques for relation extraction, their efficacy heavily relies on access to labeled data and substantial computational resources. In addressing these challenges, Large Language Models (LLMs) emerge as promising solutions; however, they might return hallucinating responses due to their own training data. To overcome these limitations, Retrieved-Augmented Generation-based Relation Extraction (RAG4RE) in this work is proposed, offering a pathway to enhance the performance of relation extraction tasks. This work evaluated the effectiveness of our RAG4RE approach utilizing different LLMs. Through the utilization of established benchmarks, such as TACRED, TACREV, Re-TACRED, and SemEval RE datasets, our aim is to comprehensively evaluate the efficacy of our RAG4RE approach. In particularly, we leverage prominent LLMs including Flan T5, Llama2, and Mistral in our investigation. The results of our study demonstrate that our RAG4RE approach surpasses performance of traditional RE approaches based solely on LLMs, particularly evident in the TACRED dataset and its variations. Furthermore, our approach exhibits remarkable performance compared to previous RE methodologies across both TACRED and TACREV datasets, underscoring its efficacy and potential for advancing RE tasks in natural language processing.
Read more4/23/2024
0
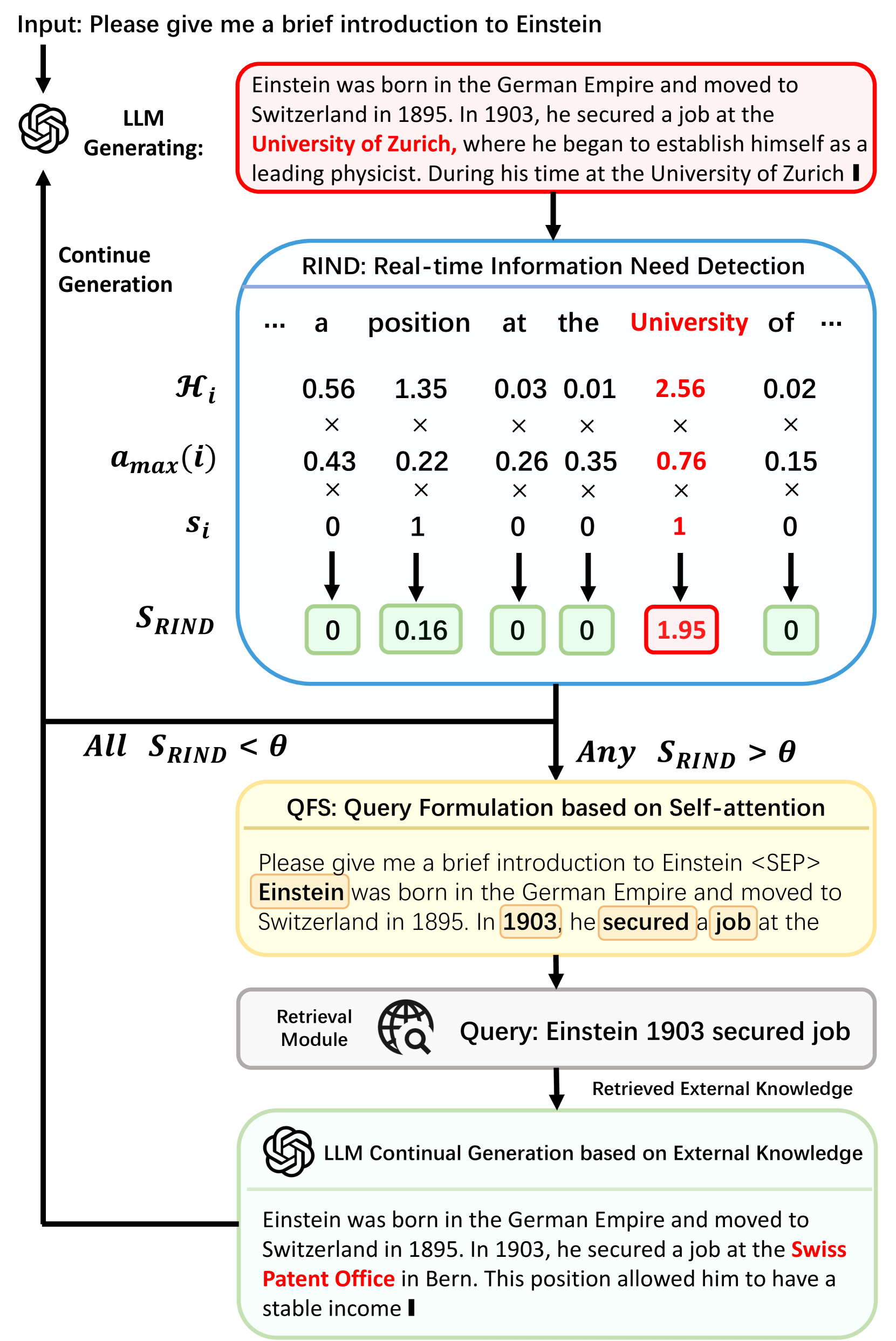
DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, Yiqun Liu
Dynamic retrieval augmented generation (RAG) paradigm actively decides when and what to retrieve during the text generation process of Large Language Models (LLMs). There are two key elements of this paradigm: identifying the optimal moment to activate the retrieval module (deciding when to retrieve) and crafting the appropriate query once retrieval is triggered (determining what to retrieve). However, current dynamic RAG methods fall short in both aspects. Firstly, the strategies for deciding when to retrieve often rely on static rules. Moreover, the strategies for deciding what to retrieve typically limit themselves to the LLM's most recent sentence or the last few tokens, while the LLM's real-time information needs may span across the entire context. To overcome these limitations, we introduce a new framework, DRAGIN, i.e., Dynamic Retrieval Augmented Generation based on the real-time Information Needs of LLMs. Our framework is specifically designed to make decisions on when and what to retrieve based on the LLM's real-time information needs during the text generation process. We evaluate DRAGIN along with existing methods comprehensively over 4 knowledge-intensive generation datasets. Experimental results show that DRAGIN achieves superior performance on all tasks, demonstrating the effectiveness of our method. We have open-sourced all the code, data, and models in GitHub: https://github.com/oneal2000/DRAGIN/tree/main
Read more6/7/2024
0
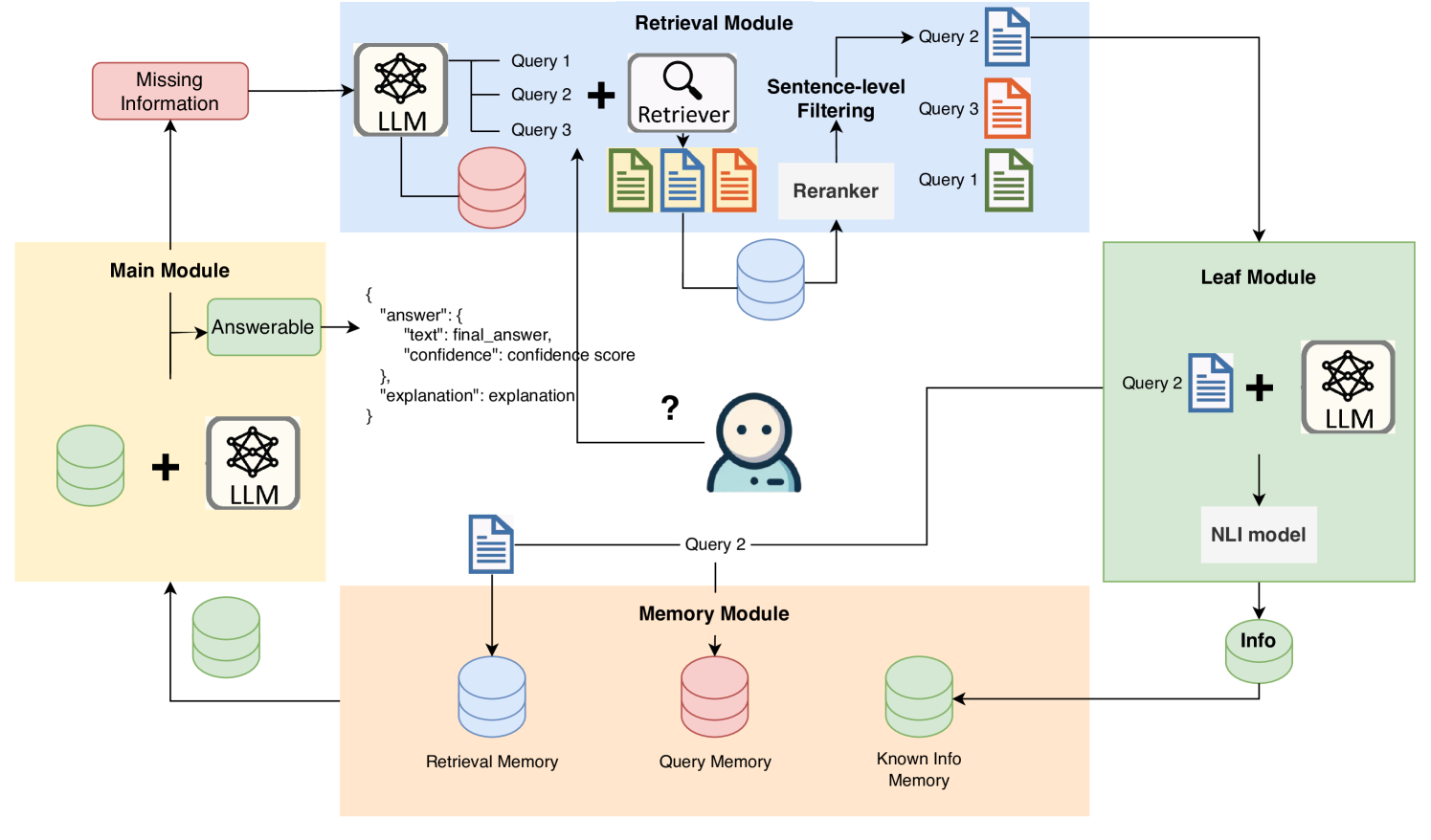
LLMs Know What They Need: Leveraging a Missing Information Guided Framework to Empower Retrieval-Augmented Generation
Keheng Wang, Feiyu Duan, Peiguang Li, Sirui Wang, Xunliang Cai
Retrieval-Augmented Generation (RAG) demonstrates great value in alleviating outdated knowledge or hallucination by supplying LLMs with updated and relevant knowledge. However, there are still several difficulties for RAG in understanding complex multi-hop query and retrieving relevant documents, which require LLMs to perform reasoning and retrieve step by step. Inspired by human's reasoning process in which they gradually search for the required information, it is natural to ask whether the LLMs could notice the missing information in each reasoning step. In this work, we first experimentally verified the ability of LLMs to extract information as well as to know the missing. Based on the above discovery, we propose a Missing Information Guided Retrieve-Extraction-Solving paradigm (MIGRES), where we leverage the identification of missing information to generate a targeted query that steers the subsequent knowledge retrieval. Besides, we design a sentence-level re-ranking filtering approach to filter the irrelevant content out from document, along with the information extraction capability of LLMs to extract useful information from cleaned-up documents, which in turn to bolster the overall efficacy of RAG. Extensive experiments conducted on multiple public datasets reveal the superiority of the proposed MIGRES method, and analytical experiments demonstrate the effectiveness of our proposed modules.
Read more4/23/2024