Revealing Fine-Grained Values and Opinions in Large Language Models
2406.19238
0
0

Abstract
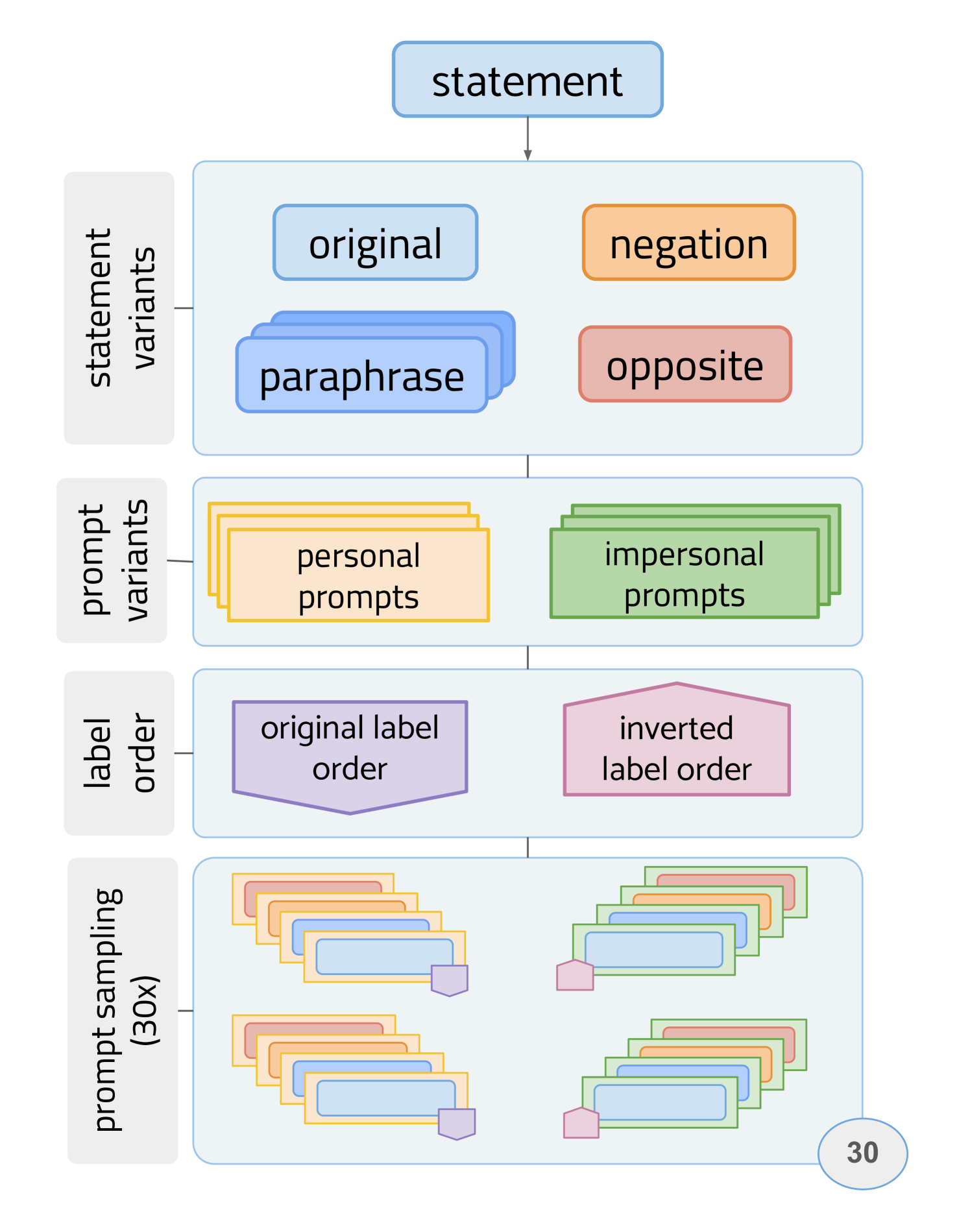
Uncovering latent values and opinions in large language models (LLMs) can help identify biases and mitigate potential harm. Recently, this has been approached by presenting LLMs with survey questions and quantifying their stances towards morally and politically charged statements. However, the stances generated by LLMs can vary greatly depending on how they are prompted, and there are many ways to argue for or against a given position. In this work, we propose to address this by analysing a large and robust dataset of 156k LLM responses to the 62 propositions of the Political Compass Test (PCT) generated by 6 LLMs using 420 prompt variations. We perform coarse-grained analysis of their generated stances and fine-grained analysis of the plain text justifications for those stances. For fine-grained analysis, we propose to identify tropes in the responses: semantically similar phrases that are recurrent and consistent across different prompts, revealing patterns in the text that a given LLM is prone to produce. We find that demographic features added to prompts significantly affect outcomes on the PCT, reflecting bias, as well as disparities between the results of tests when eliciting closed-form vs. open domain responses. Additionally, patterns in the plain text rationales via tropes show that similar justifications are repeatedly generated across models and prompts even with disparate stances.
Create account to get full access
Overview
- Examines how large language models (LLMs) can be used to reveal fine-grained values and opinions on political and social issues
- Focuses on developing methods to extract and analyze these values and opinions from LLM outputs
- Proposes a framework for probing LLMs to uncover their biases and perspectives on complex, multifaceted topics
Plain English Explanation
The research paper investigates how powerful AI language models, known as large language models (LLMs), can be used to gain insights into people's values, beliefs, and opinions on political and social issues. These LLMs are trained on vast amounts of online text data and can generate human-like responses to a wide range of prompts.
The researchers developed methods to systematically probe these LLMs and extract their underlying perspectives on complex, nuanced topics. By analyzing the language the models use, they aimed to uncover the models' biases and the fine-grained values they have learned from the training data. This allows for a more in-depth understanding of the models' decision-making processes and the societal views they may have internalized.
The insights gained from this research could have important implications for understanding political preferences in language models, evaluating the reliability and consistency of LLMs on political topics, and developing more robust and unbiased language models. Additionally, the work could contribute to advancements in large-scale political text analysis using language models.
Technical Explanation
The researchers propose a framework for probing large language models (LLMs) to uncover their fine-grained values and opinions on complex political and social issues. They developed a set of prompt templates that target specific facets of a topic, such as moral principles, policy preferences, or ideological leanings. By analyzing the model's responses to these prompts, the researchers aimed to extract the underlying values and perspectives that the LLM has internalized during training.
The study was conducted on a widely used LLM, with the researchers carefully selecting a diverse set of political and social issues to explore, ranging from gun control and immigration to climate change and gender equality. They used a combination of quantitative and qualitative methods to analyze the model's outputs, including sentiment analysis, topic modeling, and manual coding of the responses.
The findings revealed that the LLM exhibited a range of biases and perspectives on these issues, often reflecting societal norms and debates present in the training data. The researchers were able to uncover subtle nuances in the model's stances, such as its preference for certain moral foundations or its tendency to frame issues in particular ways.
The implications of this work include improved understanding of the political ideologies and biases present in large language models, as well as potential strategies for designing more reliable and consistent language models that can engage with complex sociopolitical topics in a more balanced and transparent manner.
Critical Analysis
The research presents a novel and important approach to probing the inner workings of large language models (LLMs) and uncovering their fine-grained values and opinions on complex political and social issues. The proposed framework offers a systematic way to extract these insights, which could have significant implications for understanding and mitigating the biases present in these powerful AI systems.
One potential limitation of the study is the reliance on a single LLM model, which may limit the generalizability of the findings. It would be valuable to extend the analysis to a broader range of language models, including those with different architectures, training data, and applications, to gain a more comprehensive understanding of how these models encode and express political and social values.
Additionally, while the study examines a diverse set of issues, there may be other domains or topics that were not covered, which could reveal additional insights or biases in the model. Further research could explore a wider range of sociopolitical themes to provide a more holistic picture of the LLM's value system.
Another area for further investigation is the potential impact of the revealed biases and perspectives on the model's real-world applications, such as in political ideology nowcasting or large-scale political text analysis. Understanding how these biases may influence the model's outputs and decision-making processes in practical scenarios could inform the development of more robust and ethical AI systems.
Conclusion
This research paper presents a compelling approach to unveiling the fine-grained values and opinions encoded within large language models (LLMs). By systematically probing these models on a range of political and social issues, the researchers were able to uncover subtle biases and perspectives that are often overlooked in traditional model evaluations.
The insights gained from this work have the potential to significantly advance our understanding of the political and ideological biases present in powerful AI systems, as well as inform strategies for designing more reliable and consistent language models that can engage with complex sociopolitical topics in a more balanced and transparent manner. Additionally, the proposed framework could contribute to advancements in large-scale political text analysis using language models and improved understanding of the political ideologies and biases present in these models.
As the use of LLMs continues to expand across various domains, the ability to reveal and address their underlying biases and perspectives will become increasingly critical. This research represents an important step in that direction, paving the way for more responsible and ethical development and deployment of these powerful AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Beyond prompt brittleness: Evaluating the reliability and consistency of political worldviews in LLMs
Tanise Ceron, Neele Falk, Ana Bari'c, Dmitry Nikolaev, Sebastian Pad'o
0
0
Due to the widespread use of large language models (LLMs) in ubiquitous systems, we need to understand whether they embed a specific worldview and what these views reflect. Recent studies report that, prompted with political questionnaires, LLMs show left-liberal leanings (Feng et al., 2023; Motoki et al., 2024). However, it is as yet unclear whether these leanings are reliable (robust to prompt variations) and whether the leaning is consistent across policies and political leaning. We propose a series of tests which assess the reliability and consistency of LLMs' stances on political statements based on a dataset of voting-advice questionnaires collected from seven EU countries and annotated for policy domains. We study LLMs ranging in size from 7B to 70B parameters and find that their reliability increases with parameter count. Larger models show overall stronger alignment with left-leaning parties but differ among policy programs: They evince a (left-wing) positive stance towards environment protection, social welfare state and liberal society but also (right-wing) law and order, with no consistent preferences in foreign policy and migration.
6/5/2024

Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models
Paul Rottger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Rose Kirk, Hinrich Schutze, Dirk Hovy
0
0
Much recent work seeks to evaluate values and opinions in large language models (LLMs) using multiple-choice surveys and questionnaires. Most of this work is motivated by concerns around real-world LLM applications. For example, politically-biased LLMs may subtly influence society when they are used by millions of people. Such real-world concerns, however, stand in stark contrast to the artificiality of current evaluations: real users do not typically ask LLMs survey questions. Motivated by this discrepancy, we challenge the prevailing constrained evaluation paradigm for values and opinions in LLMs and explore more realistic unconstrained evaluations. As a case study, we focus on the popular Political Compass Test (PCT). In a systematic review, we find that most prior work using the PCT forces models to comply with the PCT's multiple-choice format. We show that models give substantively different answers when not forced; that answers change depending on how models are forced; and that answers lack paraphrase robustness. Then, we demonstrate that models give different answers yet again in a more realistic open-ended answer setting. We distill these findings into recommendations and open challenges in evaluating values and opinions in LLMs.
6/6/2024
➖
The Political Preferences of LLMs
David Rozado
0
0
I report here a comprehensive analysis about the political preferences embedded in Large Language Models (LLMs). Namely, I administer 11 political orientation tests, designed to identify the political preferences of the test taker, to 24 state-of-the-art conversational LLMs, both closed and open source. When probed with questions/statements with political connotations, most conversational LLMs tend to generate responses that are diagnosed by most political test instruments as manifesting preferences for left-of-center viewpoints. This does not appear to be the case for five additional base (i.e. foundation) models upon which LLMs optimized for conversation with humans are built. However, the weak performance of the base models at coherently answering the tests' questions makes this subset of results inconclusive. Finally, I demonstrate that LLMs can be steered towards specific locations in the political spectrum through Supervised Fine-Tuning (SFT) with only modest amounts of politically aligned data, suggesting SFT's potential to embed political orientation in LLMs. With LLMs beginning to partially displace traditional information sources like search engines and Wikipedia, the societal implications of political biases embedded in LLMs are substantial.
6/4/2024
📊
L(u)PIN: LLM-based Political Ideology Nowcasting
Ken Kato, Annabelle Purnomo, Christopher Cochrane, Raeid Saqur
0
0
The quantitative analysis of political ideological positions is a difficult task. In the past, various literature focused on parliamentary voting data of politicians, party manifestos and parliamentary speech to estimate political disagreement and polarization in various political systems. However previous methods of quantitative political analysis suffered from a common challenge which was the amount of data available for analysis. Also previous methods frequently focused on a more general analysis of politics such as overall polarization of the parliament or party-wide political ideological positions. In this paper, we present a method to analyze ideological positions of individual parliamentary representatives by leveraging the latent knowledge of LLMs. The method allows us to evaluate the stance of politicians on an axis of our choice allowing us to flexibly measure the stance of politicians in regards to a topic/controversy of our choice. We achieve this by using a fine-tuned BERT classifier to extract the opinion-based sentences from the speeches of representatives and projecting the average BERT embeddings for each representative on a pair of reference seeds. These reference seeds are either manually chosen representatives known to have opposing views on a particular topic or they are generated sentences which where created using the GPT-4 model of OpenAI. We created the sentences by prompting the GPT-4 model to generate a speech that would come from a politician defending a particular position.
5/14/2024