Beyond prompt brittleness: Evaluating the reliability and consistency of political worldviews in LLMs
2402.17649
0
0
Abstract
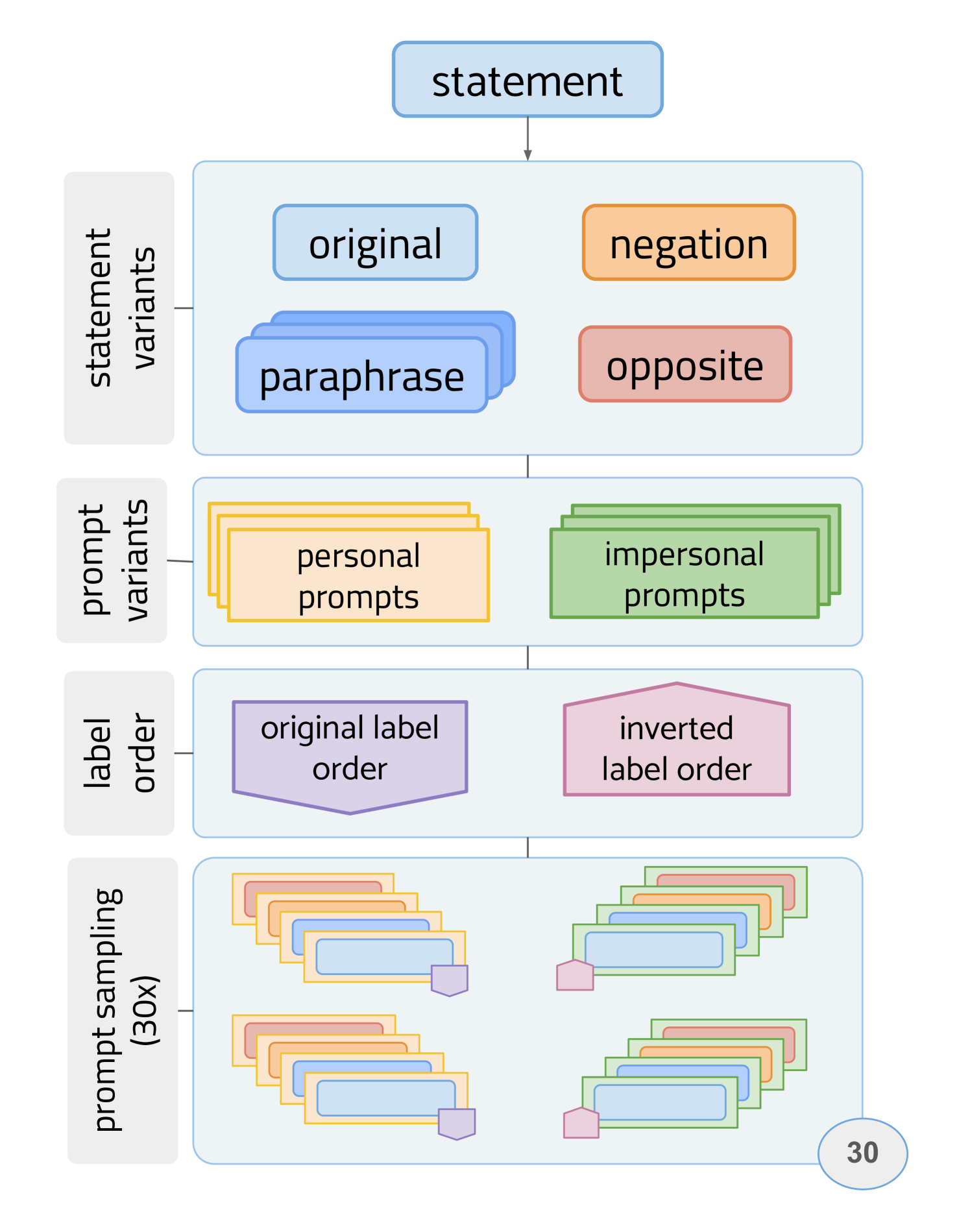
Due to the widespread use of large language models (LLMs) in ubiquitous systems, we need to understand whether they embed a specific worldview and what these views reflect. Recent studies report that, prompted with political questionnaires, LLMs show left-liberal leanings (Feng et al., 2023; Motoki et al., 2024). However, it is as yet unclear whether these leanings are reliable (robust to prompt variations) and whether the leaning is consistent across policies and political leaning. We propose a series of tests which assess the reliability and consistency of LLMs' stances on political statements based on a dataset of voting-advice questionnaires collected from seven EU countries and annotated for policy domains. We study LLMs ranging in size from 7B to 70B parameters and find that their reliability increases with parameter count. Larger models show overall stronger alignment with left-leaning parties but differ among policy programs: They evince a (left-wing) positive stance towards environment protection, social welfare state and liberal society but also (right-wing) law and order, with no consistent preferences in foreign policy and migration.
Create account to get full access
Overview
- This paper investigates the reliability and consistency of political worldviews expressed by large language models (LLMs).
- The researchers aimed to evaluate how stable and coherent the political opinions generated by LLMs are, going beyond just measuring biases.
- They conducted a series of experiments to assess the political views expressed by LLMs across different prompts and contexts.
Plain English Explanation
The researchers behind this paper wanted to better understand how reliable and consistent the political opinions generated by large language models (LLMs) really are. LLMs are AI systems trained on massive amounts of text data that can be used to generate human-like responses.
Past research has mostly focused on detecting political biases in LLMs, but this paper takes a deeper dive. The researchers ran experiments to see how stable and coherent the political views expressed by LLMs are across different prompts and contexts. In other words, they wanted to see if an LLM would give consistently similar political opinions, or if its views would be all over the place.
By evaluating the reliability and consistency of political worldviews in LLMs, the researchers hope to shed light on how well these AI systems can really engage with complex political topics. This could have important implications for how we use and interpret the outputs of LLMs, especially when it comes to sensitive areas like politics.
Technical Explanation
The paper begins by reviewing relevant prior research on assessing political biases and worldviews in large language models and detecting political orientation in text.
The core of the paper is a series of experiments the researchers conducted to evaluate the reliability and consistency of political worldviews expressed by LLMs. They used prompts designed to elicit political opinions on a range of issues from multiple LLM models. The responses were then analyzed for coherence, stability, and consistency across prompts.
The results suggest that while LLMs can generate politically-charged text, their political opinions often lack reliability and consistency. The models tended to express divergent or even contradictory views depending on the prompt. The researchers also found that the political worldviews exhibited by LLMs were often overly simplistic or failed to capture nuance.
Overall, the findings indicate that we should be cautious about relying too heavily on the political opinions generated by current LLM systems. The researchers recommend further work to improve the reliability and sophistication of political reasoning in these AI models.
Critical Analysis
The paper provides a valuable contribution by delving deeper into an important but under-studied aspect of LLMs - the reliability and consistency of the political worldviews they express. Prior work has often focused on more surface-level detection of political biases, but this research gets at a more fundamental issue.
That said, the experiments conducted were relatively narrow in scope, focused mainly on prompts related to a limited set of political topics. It would be worth exploring how LLM political worldviews hold up across a broader range of prompts and political issues. The researchers also note that their analysis relied heavily on human judgment, which could introduce biases.
Additionally, the paper does not delve too deeply into why LLMs struggle to maintain coherent and consistent political opinions. More investigation is needed into the underlying factors, such as the nature of the training data, model architecture, or the inherent challenges of encoding complex political reasoning into language models.
Overall, this is an important step forward in critically examining the capabilities and limitations of LLMs when it comes to engaging with nuanced political topics. But there is still much work to be done to fully understand and address the issues raised in this paper.
Conclusion
This research paper takes a valuable look at an underexplored aspect of large language models - their ability to consistently and reliably express political worldviews.
The key finding is that while LLMs can generate politically-charged text, their political opinions often lack coherence and stability across different prompts and contexts. This raises concerns about relying too heavily on the political views generated by these AI systems, given their tendency toward oversimplification and contradiction.
Moving forward, the authors suggest the need for further research to improve the reliability and sophistication of political reasoning in LLMs. Addressing these limitations could have significant implications for how we develop and employ these powerful language models, especially when it comes to sensitive domains like politics and policymaking.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
The Political Preferences of LLMs
David Rozado
0
0
I report here a comprehensive analysis about the political preferences embedded in Large Language Models (LLMs). Namely, I administer 11 political orientation tests, designed to identify the political preferences of the test taker, to 24 state-of-the-art conversational LLMs, both closed and open source. When probed with questions/statements with political connotations, most conversational LLMs tend to generate responses that are diagnosed by most political test instruments as manifesting preferences for left-of-center viewpoints. This does not appear to be the case for five additional base (i.e. foundation) models upon which LLMs optimized for conversation with humans are built. However, the weak performance of the base models at coherently answering the tests' questions makes this subset of results inconclusive. Finally, I demonstrate that LLMs can be steered towards specific locations in the political spectrum through Supervised Fine-Tuning (SFT) with only modest amounts of politically aligned data, suggesting SFT's potential to embed political orientation in LLMs. With LLMs beginning to partially displace traditional information sources like search engines and Wikipedia, the societal implications of political biases embedded in LLMs are substantial.
6/4/2024
💬
Assessing Political Bias in Large Language Models
Luca Rettenberger, Markus Reischl, Mark Schutera
0
0
The assessment of bias within Large Language Models (LLMs) has emerged as a critical concern in the contemporary discourse surrounding Artificial Intelligence (AI) in the context of their potential impact on societal dynamics. Recognizing and considering political bias within LLM applications is especially important when closing in on the tipping point toward performative prediction. Then, being educated about potential effects and the societal behavior LLMs can drive at scale due to their interplay with human operators. In this way, the upcoming elections of the European Parliament will not remain unaffected by LLMs. We evaluate the political bias of the currently most popular open-source LLMs (instruct or assistant models) concerning political issues within the European Union (EU) from a German voter's perspective. To do so, we use the Wahl-O-Mat, a voting advice application used in Germany. From the voting advice of the Wahl-O-Mat we quantize the degree of alignment of LLMs with German political parties. We show that larger models, such as Llama3-70B, tend to align more closely with left-leaning political parties, while smaller models often remain neutral, particularly when prompted in English. The central finding is that LLMs are similarly biased, with low variances in the alignment concerning a specific party. Our findings underline the importance of rigorously assessing and making bias transparent in LLMs to safeguard the integrity and trustworthiness of applications that employ the capabilities of performative prediction and the invisible hand of machine learning prediction and language generation.
6/6/2024

New!Revealing Fine-Grained Values and Opinions in Large Language Models
Dustin Wright, Arnav Arora, Nadav Borenstein, Srishti Yadav, Serge Belongie, Isabelle Augenstein
0
0
Uncovering latent values and opinions in large language models (LLMs) can help identify biases and mitigate potential harm. Recently, this has been approached by presenting LLMs with survey questions and quantifying their stances towards morally and politically charged statements. However, the stances generated by LLMs can vary greatly depending on how they are prompted, and there are many ways to argue for or against a given position. In this work, we propose to address this by analysing a large and robust dataset of 156k LLM responses to the 62 propositions of the Political Compass Test (PCT) generated by 6 LLMs using 420 prompt variations. We perform coarse-grained analysis of their generated stances and fine-grained analysis of the plain text justifications for those stances. For fine-grained analysis, we propose to identify tropes in the responses: semantically similar phrases that are recurrent and consistent across different prompts, revealing patterns in the text that a given LLM is prone to produce. We find that demographic features added to prompts significantly affect outcomes on the PCT, reflecting bias, as well as disparities between the results of tests when eliciting closed-form vs. open domain responses. Additionally, patterns in the plain text rationales via tropes show that similar justifications are repeatedly generated across models and prompts even with disparate stances.
6/28/2024

Aligning Large Language Models with Diverse Political Viewpoints
Dominik Stammbach, Philine Widmer, Eunjung Cho, Caglar Gulcehre, Elliott Ash
0
0
Large language models such as ChatGPT often exhibit striking political biases. If users query them about political information, they might take a normative stance and reinforce such biases. To overcome this, we align LLMs with diverse political viewpoints from 100,000 comments written by candidates running for national parliament in Switzerland. Such aligned models are able to generate more accurate political viewpoints from Swiss parties compared to commercial models such as ChatGPT. We also propose a procedure to generate balanced overviews from multiple viewpoints using such models.
6/21/2024