The Political Preferences of LLMs
2402.01789
0
0
➖
Abstract
I report here a comprehensive analysis about the political preferences embedded in Large Language Models (LLMs). Namely, I administer 11 political orientation tests, designed to identify the political preferences of the test taker, to 24 state-of-the-art conversational LLMs, both closed and open source. When probed with questions/statements with political connotations, most conversational LLMs tend to generate responses that are diagnosed by most political test instruments as manifesting preferences for left-of-center viewpoints. This does not appear to be the case for five additional base (i.e. foundation) models upon which LLMs optimized for conversation with humans are built. However, the weak performance of the base models at coherently answering the tests' questions makes this subset of results inconclusive. Finally, I demonstrate that LLMs can be steered towards specific locations in the political spectrum through Supervised Fine-Tuning (SFT) with only modest amounts of politically aligned data, suggesting SFT's potential to embed political orientation in LLMs. With LLMs beginning to partially displace traditional information sources like search engines and Wikipedia, the societal implications of political biases embedded in LLMs are substantial.
Create account to get full access
Overview
- The paper reports a comprehensive analysis of the political preferences embedded in Large Language Models (LLMs).
- The researchers administered 11 political orientation tests to 24 state-of-the-art conversational LLMs, both closed and open source.
- The results show that most conversational LLMs tend to generate responses that are diagnosed by the political tests as manifesting preferences for left-of-center viewpoints.
- The researchers also demonstrate that LLMs can be steered towards specific locations in the political spectrum through Supervised Fine-Tuning (SFT) with only modest amounts of politically aligned data.
Plain English Explanation
The researchers were interested in understanding the political leanings of large language models, which are AI systems that can generate human-like text. They took 24 of the latest and most advanced conversational language models, both open-source and closed-source, and tested them using 11 different political orientation assessments.
These political tests are designed to identify the political preferences of the person taking the test, such as whether they lean more towards liberal or conservative views. When the researchers asked the language models questions or statements with political undertones, the models tended to generate responses that the tests diagnosed as having a left-of-center political orientation.
Interestingly, the researchers found that this left-leaning bias was not as pronounced in the underlying base models that the conversational LLMs were built upon. However, these base models struggled to provide coherent responses to the political test questions, making it difficult to draw firm conclusions about their political leanings.
The researchers also showed that it is possible to steer the political orientation of LLMs by fine-tuning them on a relatively small amount of politically-aligned data. This means that the political biases embedded in LLMs can be adjusted to align with specific ideological viewpoints.
As LLMs begin to partially replace traditional information sources like search engines and Wikipedia, the researchers argue that the political biases in these models could have significant societal implications.
Technical Explanation
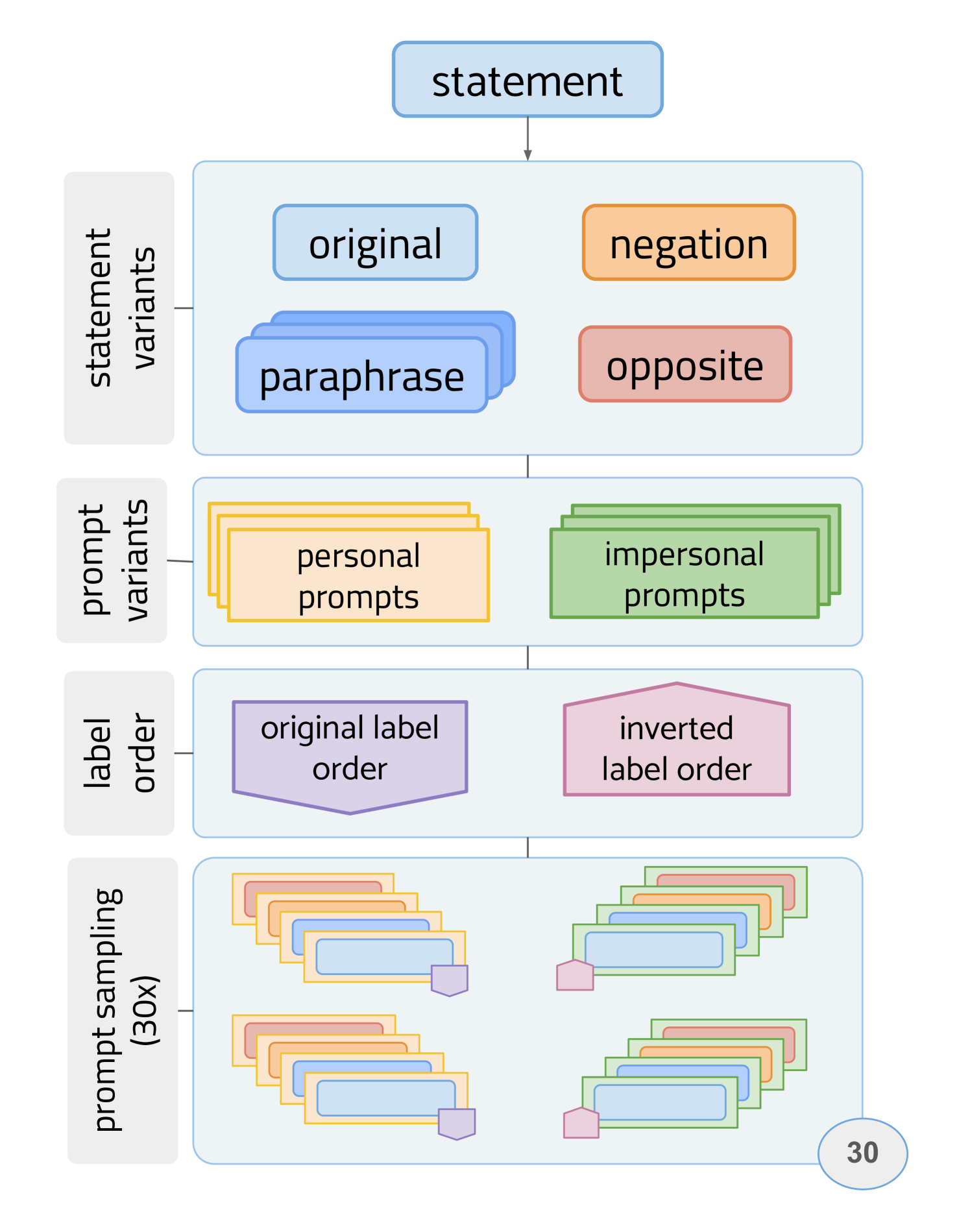
The researchers conducted a series of experiments to assess the political preferences embedded in a diverse set of 24 state-of-the-art conversational LLMs, including both closed-source and open-source models. They administered 11 different political orientation tests, which are designed to identify the political leanings of the test taker, to each of the language models.
The tests covered a range of political dimensions, such as economic, social, and foreign policy views. When the LLMs were prompted with questions or statements with political connotations, the researchers found that most of the conversational models tended to generate responses that were diagnosed by the political tests as manifesting preferences for left-of-center viewpoints.
To further investigate the source of this left-leaning bias, the researchers also tested 5 additional base (i.e., foundation) models upon which the conversational LLMs were built. While the results for the base models were more inconclusive due to their poor performance at coherently answering the political test questions, the researchers did not observe the same consistent left-leaning bias as in the case of the conversational LLMs.
Finally, the researchers demonstrated that the political orientation of LLMs can be steered through Supervised Fine-Tuning (SFT) with only modest amounts of politically aligned data. This suggests that the political biases embedded in LLMs can be adjusted to align with specific ideological viewpoints.
Critical Analysis
The paper provides a comprehensive and rigorous analysis of the political biases embedded in state-of-the-art conversational LLMs. The researchers' use of a diverse set of political orientation tests to assess the models' responses is a strength of the study, as it allows for a multifaceted evaluation of the political leanings.
However, the inconclusive results for the base models highlight the need for further research to fully understand the source of the left-leaning biases observed in the conversational LLMs. It is possible that the fine-tuning process used to optimize these models for conversational tasks may have inadvertently introduced political biases, but more work is needed to confirm this hypothesis.
Additionally, the researchers' demonstration of the ability to steer LLMs towards specific political orientations through SFT raises concerns about the potential for manipulation of these powerful AI systems. The societal implications of such political biases in LLMs, which are increasingly being used as information sources, warrant further scrutiny and discussion.
Conclusion
The paper presents a comprehensive analysis of the political biases embedded in state-of-the-art conversational LLMs. The results suggest that most of these models tend to generate responses aligned with left-of-center political viewpoints, a finding that the researchers attribute to the models' training process rather than inherent biases in the underlying base models.
Importantly, the researchers demonstrate that the political orientation of LLMs can be adjusted through Supervised Fine-Tuning, raising concerns about the potential for manipulation of these AI systems. As LLMs continue to partially displace traditional information sources, the societal implications of political biases in these models will be an important area of ongoing research and debate.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Beyond prompt brittleness: Evaluating the reliability and consistency of political worldviews in LLMs
Tanise Ceron, Neele Falk, Ana Bari'c, Dmitry Nikolaev, Sebastian Pad'o
0
0
Due to the widespread use of large language models (LLMs) in ubiquitous systems, we need to understand whether they embed a specific worldview and what these views reflect. Recent studies report that, prompted with political questionnaires, LLMs show left-liberal leanings (Feng et al., 2023; Motoki et al., 2024). However, it is as yet unclear whether these leanings are reliable (robust to prompt variations) and whether the leaning is consistent across policies and political leaning. We propose a series of tests which assess the reliability and consistency of LLMs' stances on political statements based on a dataset of voting-advice questionnaires collected from seven EU countries and annotated for policy domains. We study LLMs ranging in size from 7B to 70B parameters and find that their reliability increases with parameter count. Larger models show overall stronger alignment with left-leaning parties but differ among policy programs: They evince a (left-wing) positive stance towards environment protection, social welfare state and liberal society but also (right-wing) law and order, with no consistent preferences in foreign policy and migration.
6/5/2024
💬
Assessing Political Bias in Large Language Models
Luca Rettenberger, Markus Reischl, Mark Schutera
0
0
The assessment of bias within Large Language Models (LLMs) has emerged as a critical concern in the contemporary discourse surrounding Artificial Intelligence (AI) in the context of their potential impact on societal dynamics. Recognizing and considering political bias within LLM applications is especially important when closing in on the tipping point toward performative prediction. Then, being educated about potential effects and the societal behavior LLMs can drive at scale due to their interplay with human operators. In this way, the upcoming elections of the European Parliament will not remain unaffected by LLMs. We evaluate the political bias of the currently most popular open-source LLMs (instruct or assistant models) concerning political issues within the European Union (EU) from a German voter's perspective. To do so, we use the Wahl-O-Mat, a voting advice application used in Germany. From the voting advice of the Wahl-O-Mat we quantize the degree of alignment of LLMs with German political parties. We show that larger models, such as Llama3-70B, tend to align more closely with left-leaning political parties, while smaller models often remain neutral, particularly when prompted in English. The central finding is that LLMs are similarly biased, with low variances in the alignment concerning a specific party. Our findings underline the importance of rigorously assessing and making bias transparent in LLMs to safeguard the integrity and trustworthiness of applications that employ the capabilities of performative prediction and the invisible hand of machine learning prediction and language generation.
6/6/2024
💬
Large Language Models' Detection of Political Orientation in Newspapers
Alessio Buscemi, Daniele Proverbio
0
0
Democratic opinion-forming may be manipulated if newspapers' alignment to political or economical orientation is ambiguous. Various methods have been developed to better understand newspapers' positioning. Recently, the advent of Large Language Models (LLM), and particularly the pre-trained LLM chatbots like ChatGPT or Gemini, hold disruptive potential to assist researchers and citizens alike. However, little is know on whether LLM assessment is trustworthy: do single LLM agrees with experts' assessment, and do different LLMs answer consistently with one another? In this paper, we address specifically the second challenge. We compare how four widely employed LLMs rate the positioning of newspapers, and compare if their answers align with one another. We observe that this is not the case. Over a woldwide dataset, articles in newspapers are positioned strikingly differently by single LLMs, hinting to inconsistent training or excessive randomness in the algorithms. We thus raise a warning when deciding which tools to use, and we call for better training and algorithm development, to cover such significant gap in a highly sensitive matter for democracy and societies worldwide. We also call for community engagement in benchmark evaluation, through our open initiative navai.pro.
6/4/2024

Aligning Large Language Models with Diverse Political Viewpoints
Dominik Stammbach, Philine Widmer, Eunjung Cho, Caglar Gulcehre, Elliott Ash
0
0
Large language models such as ChatGPT often exhibit striking political biases. If users query them about political information, they might take a normative stance and reinforce such biases. To overcome this, we align LLMs with diverse political viewpoints from 100,000 comments written by candidates running for national parliament in Switzerland. Such aligned models are able to generate more accurate political viewpoints from Swiss parties compared to commercial models such as ChatGPT. We also propose a procedure to generate balanced overviews from multiple viewpoints using such models.
6/21/2024