Revealing the Parametric Knowledge of Language Models: A Unified Framework for Attribution Methods

0
Sign in to get full access
Overview
- This paper introduces a unified framework for attribution methods, which aim to reveal the parametric knowledge of language models.
- Attribution methods can help understand how language models make decisions and what knowledge they have stored in their parameters.
- The proposed framework encompasses various existing attribution methods, providing a comprehensive approach to studying language model internals.
Plain English Explanation
Language models are powerful AI systems that can generate human-like text. However, it's often difficult to understand how these models work under the hood and what specific knowledge they have learned from their training data. This paper introduces a unified framework for attribution methods, which are techniques that can "peek inside" a language model and reveal the parametric knowledge it has acquired.
The key idea is that by applying different attribution methods to a language model, researchers can gain insights into the model's decision-making process and the information it has stored in its parameters. For example, an attribution method might highlight the specific words or phrases in an input that most influenced the model's output. This can help us understand what the model has learned about language and how it applies that knowledge.
The paper proposes a unified framework that encompasses a variety of existing attribution methods. This allows researchers to compare and combine different approaches, providing a more comprehensive understanding of a language model's inner workings. By revealing the parametric knowledge of language models, this research can ultimately lead to better-informed model development and more transparent AI systems.
Technical Explanation
The paper introduces a unified framework for attribution methods, which aim to reveal the parametric knowledge of language models. The framework encompasses various existing attribution approaches, including gradient-based methods, concept activation vectors, and attention-based methods.
The authors first provide a formal definition of attribution methods and discuss their properties, such as faithfulness, stability, and compositional explanations. They then present a unifying mathematical formulation that captures the essence of different attribution techniques.
The framework is evaluated on several language understanding tasks, including sentiment analysis, question answering, and natural language inference. The authors demonstrate that the proposed unified approach can effectively reveal the parametric knowledge of language models, providing insights into their decision-making processes and the information they have learned.
Critical Analysis
The paper offers a comprehensive and unified view of attribution methods for language models, which is a valuable contribution to the field of model interpretability. By encompassing a range of existing techniques, the proposed framework provides a more holistic understanding of language model internals.
However, the paper does not address some potential limitations of attribution methods. For example, the faithful representation of complex model decisions remains a challenge, and the interpretation of attribution results can be subjective. Additionally, the paper does not discuss the computational overhead or scalability of the proposed framework, which may be important considerations for practical applications.
Further research could explore the robustness of attribution methods to model architecture changes or investigate the application of the unified framework to other types of language models, such as large-scale transformers. Engaging in critical discussions around the limitations and potential biases of attribution techniques will also be crucial for advancing the responsible development of interpretable AI systems.
Conclusion
This paper presents a unified framework for attribution methods, which can reveal the parametric knowledge of language models. By encompassing a variety of existing techniques, the framework provides a comprehensive approach to understanding the inner workings of language models and the specific knowledge they have acquired.
The research has the potential to significantly advance the field of model interpretability, enabling more transparent and accountable AI systems. By uncovering how large language models work, this work can inform the development of better-designed and more trustworthy language models, with important implications for a wide range of applications in natural language processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revealing the Parametric Knowledge of Language Models: A Unified Framework for Attribution Methods
Haeun Yu, Pepa Atanasova, Isabelle Augenstein
Language Models (LMs) acquire parametric knowledge from their training process, embedding it within their weights. The increasing scalability of LMs, however, poses significant challenges for understanding a model's inner workings and further for updating or correcting this embedded knowledge without the significant cost of retraining. This underscores the importance of unveiling exactly what knowledge is stored and its association with specific model components. Instance Attribution (IA) and Neuron Attribution (NA) offer insights into this training-acquired knowledge, though they have not been compared systematically. Our study introduces a novel evaluation framework to quantify and compare the knowledge revealed by IA and NA. To align the results of the methods we introduce the attribution method NA-Instances to apply NA for retrieving influential training instances, and IA-Neurons to discover important neurons of influential instances discovered by IA. We further propose a comprehensive list of faithfulness tests to evaluate the comprehensiveness and sufficiency of the explanations provided by both methods. Through extensive experiments and analysis, we demonstrate that NA generally reveals more diverse and comprehensive information regarding the LM's parametric knowledge compared to IA. Nevertheless, IA provides unique and valuable insights into the LM's parametric knowledge, which are not revealed by NA. Our findings further suggest the potential of a synergistic approach of combining the diverse findings of IA and NA for a more holistic understanding of an LM's parametric knowledge.
Read more4/30/2024

0
Analyzing Key Neurons in Large Language Models
Lihu Chen, Adam Dejl, Francesca Toni
Large Language Models (LLMs) possess vast amounts of knowledge within their parameters, prompting research into methods for locating and editing this knowledge. Previous work has largely focused on locating entity-related (often single-token) facts in smaller models. However, several key questions remain unanswered: (1) How can we effectively locate query-relevant neurons in contemporary autoregressive LLMs, such as Llama and Mistral? (2) How can we address the challenge of long-form text generation? (3) Are there localized knowledge regions in LLMs? In this study, we introduce Query-Relevant Neuron Cluster Attribution (QRNCA), a novel architecture-agnostic framework capable of identifying query-relevant neurons in LLMs. QRNCA allows for the examination of long-form answers beyond triplet facts by employing the proxy task of multi-choice question answering. To evaluate the effectiveness of our detected neurons, we build two multi-choice QA datasets spanning diverse domains and languages. Empirical evaluations demonstrate that our method outperforms baseline methods significantly. Further, analysis of neuron distributions reveals the presence of visible localized regions, particularly within different domains. Finally, we show potential applications of our detected neurons in knowledge editing and neuron-based prediction.
Read more8/21/2024
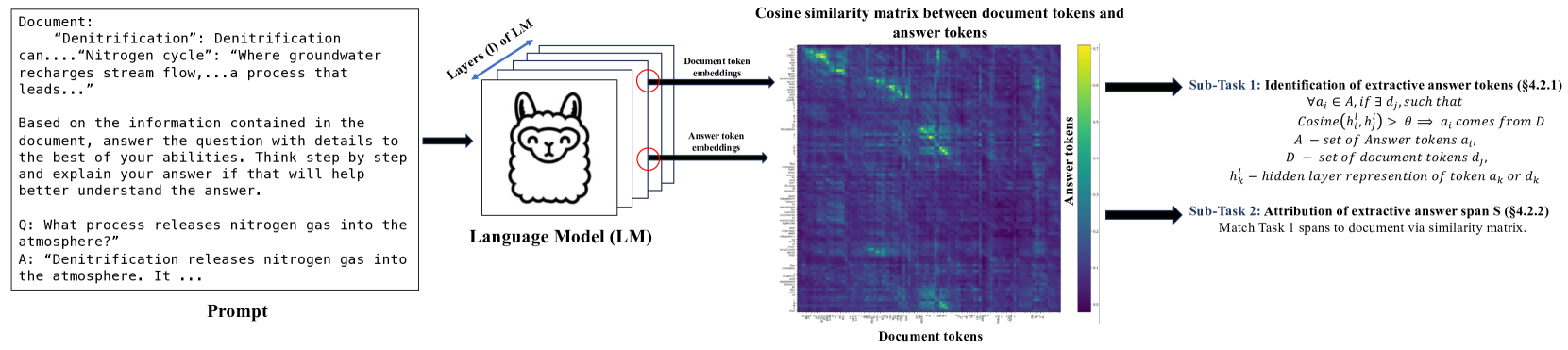
0
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
Anirudh Phukan, Shwetha Somasundaram, Apoorv Saxena, Koustava Goswami, Balaji Vasan Srinivasan
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with glue text generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
Read more5/29/2024

0
Towards Verifiable Generation: A Benchmark for Knowledge-aware Language Model Attribution
Xinze Li, Yixin Cao, Liangming Pan, Yubo Ma, Aixin Sun
Although achieving great success, Large Language Models (LLMs) usually suffer from unreliable hallucinations. Although language attribution can be a potential solution, there are no suitable benchmarks and evaluation metrics to attribute LLMs to structured knowledge. In this paper, we define a new task of Knowledge-aware Language Model Attribution (KaLMA) that improves upon three core concerns with conventional attributed LMs. First, we extend attribution source from unstructured texts to Knowledge Graph (KG), whose rich structures benefit both the attribution performance and working scenarios. Second, we propose a new ``Conscious Incompetence setting considering the incomplete knowledge repository, where the model identifies the need for supporting knowledge beyond the provided KG. Third, we propose a comprehensive automatic evaluation metric encompassing text quality, citation quality, and text citation alignment. To implement the above innovations, we build a dataset in biography domain BioKaLMA via evolutionary question generation strategy, to control the question complexity and necessary knowledge to the answer. For evaluation, we develop a baseline solution and demonstrate the room for improvement in LLMs' citation generation, emphasizing the importance of incorporating the Conscious Incompetence setting, and the critical role of retrieval accuracy.
Read more5/24/2024