Beyond Benchmarking: A New Paradigm for Evaluation and Assessment of Large Language Models

0

Sign in to get full access
Overview
- The paper discusses limitations of the current benchmarking approach for evaluating large language models (LLMs) and proposes a new paradigm.
- It highlights issues such as the inability of benchmarks to capture real-world performance, the lack of generalizability, and the potential for gaming and overfitting.
- The paper suggests moving beyond narrow benchmarks to a more holistic assessment that considers model performance in diverse contexts and use cases.
Plain English Explanation
While benchmarking has been the dominant way to evaluate the capabilities of large language models, this paper argues that it has significant limitations. Benchmarks often fail to capture how these models would perform in actual real-world applications. They may also encourage model developers to optimize for the specific benchmark tasks rather than developing more generally capable systems.
The paper proposes a shift away from relying solely on benchmarks towards a more comprehensive evaluation approach. This could involve assessing model performance across a wider range of contexts and use cases, rather than focusing on a narrow set of predefined tasks. The goal would be to better understand the strengths, weaknesses, and limitations of these powerful language models in a more holistic way.
By moving beyond the current benchmarking paradigm, the authors hope to drive the development of LLMs that are not just good at specific benchmark tasks, but truly capable of adapting to and excelling in diverse real-world scenarios. This could lead to language models that are more robust, reliable, and beneficial in practical applications.
Technical Explanation
The paper begins by outlining several potential issues with the current benchmarking approach for evaluating large language models. First, it argues that benchmarks may fail to capture real-world performance, as the tasks and datasets used may not accurately reflect the complexities and requirements of actual applications.
Additionally, the authors suggest that benchmarks often lack generalizability, meaning that strong performance on one set of tasks does not necessarily translate to equally strong performance on different tasks or in new domains. This can lead to a false sense of model capabilities and limit our understanding of their true strengths and limitations.
The paper also discusses the potential for gaming and overfitting, where model developers may optimize their systems specifically for the benchmark tasks rather than developing more generally capable models. This can result in models that perform well on the benchmarks but struggle in real-world scenarios.
To address these issues, the paper proposes a shift towards a more holistic evaluation paradigm. This could involve assessing model performance across a diverse set of contexts and use cases, as explored in CityBench. The goal would be to better understand the capabilities and limitations of LLMs in a more comprehensive manner, rather than relying solely on narrow benchmark results.
Critical Analysis
The paper raises valid concerns about the limitations of the current benchmarking approach for evaluating large language models. The authors make a compelling case that benchmarks may not accurately reflect real-world performance and can incentivize model developers to optimize for specific tasks rather than building more generally capable systems.
However, the paper does not provide a clear and detailed alternative evaluation framework. While it suggests moving towards a more holistic assessment, it lacks specifics on how such an approach could be implemented in practice. Additionally, the paper does not address the inherent challenges of evaluating the complex and multifaceted capabilities of LLMs, which can make a comprehensive assessment a daunting task.
Debates and comprehensive benchmarks have been proposed as potential solutions to the limitations of traditional benchmarking, but the paper does not engage with or build upon these existing efforts.
Further research and discussion are needed to develop a robust and practical evaluation framework that can effectively capture the evolving capabilities of large language models, while addressing the concerns raised in this paper.
Conclusion
This paper makes a compelling case for moving beyond the current benchmarking paradigm in the evaluation and assessment of large language models. It highlights the limitations of narrow benchmark tasks in capturing real-world performance and the potential for gaming and overfitting.
The proposed shift towards a more holistic evaluation approach has the potential to provide a deeper understanding of the strengths, weaknesses, and limitations of these powerful language models. By assessing their performance across diverse contexts and use cases, researchers and developers can work towards building LLMs that are truly capable of adapting to and excelling in a wide range of real-world applications.
While the paper does not provide a detailed alternative framework, it lays the foundation for a much-needed discussion on improving the way we evaluate and understand the capabilities of large language models. Continued research and collaboration in this area can lead to the development of more robust, reliable, and beneficial language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Benchmarking: A New Paradigm for Evaluation and Assessment of Large Language Models
Jin Liu, Qingquan Li, Wenlong Du
In current benchmarks for evaluating large language models (LLMs), there are issues such as evaluation content restriction, untimely updates, and lack of optimization guidance. In this paper, we propose a new paradigm for the measurement of LLMs: Benchmarking-Evaluation-Assessment. Our paradigm shifts the location of LLM evaluation from the examination room to the hospital. Through conducting a physical examination on LLMs, it utilizes specific task-solving as the evaluation content, performs deep attribution of existing problems within LLMs, and provides recommendation for optimization.
Read more7/11/2024

0
Beyond Metrics: A Critical Analysis of the Variability in Large Language Model Evaluation Frameworks
Marco AF Pimentel, Cl'ement Christophe, Tathagata Raha, Prateek Munjal, Praveen K Kanithi, Shadab Khan
As large language models (LLMs) continue to evolve, the need for robust and standardized evaluation benchmarks becomes paramount. Evaluating the performance of these models is a complex challenge that requires careful consideration of various linguistic tasks, model architectures, and benchmarking methodologies. In recent years, various frameworks have emerged as noteworthy contributions to the field, offering comprehensive evaluation tests and benchmarks for assessing the capabilities of LLMs across diverse domains. This paper provides an exploration and critical analysis of some of these evaluation methodologies, shedding light on their strengths, limitations, and impact on advancing the state-of-the-art in natural language processing.
Read more8/1/2024

0
Evaluating the Performance of Large Language Models via Debates
Behrad Moniri, Hamed Hassani, Edgar Dobriban
Large Language Models (LLMs) are rapidly evolving and impacting various fields, necessitating the development of effective methods to evaluate and compare their performance. Most current approaches for performance evaluation are either based on fixed, domain-specific questions that lack the flexibility required in many real-world applications where tasks are not always from a single domain, or rely on human input, making them unscalable. We propose an automated benchmarking framework based on debates between LLMs, judged by another LLM. This method assesses not only domain knowledge, but also skills such as problem definition and inconsistency recognition. We evaluate the performance of various state-of-the-art LLMs using the debate framework and achieve rankings that align closely with popular rankings based on human input, eliminating the need for costly human crowdsourcing.
Read more6/18/2024
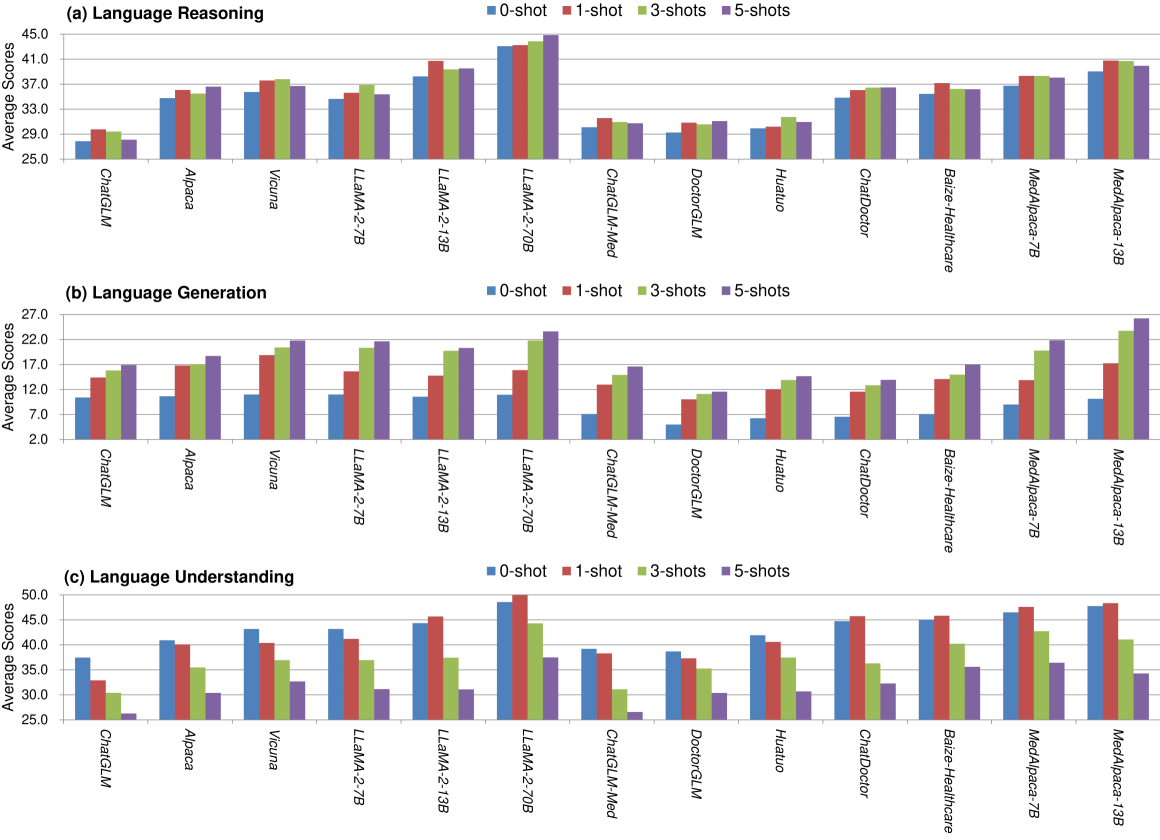
0
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Anshul Thakur, Lei Clifton, David A. Clifton
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
Read more6/27/2024