Revisiting Referring Expression Comprehension Evaluation in the Era of Large Multimodal Models

0

Sign in to get full access
Overview
• This paper revisits the evaluation of referring expression comprehension (REC) in the context of large multimodal models. • The authors argue that existing REC datasets and evaluation metrics may not adequately capture the capabilities of modern AI systems, and propose new approaches to better assess performance. • The paper covers related work, experimental design, and a critical analysis of the research, with potential implications for the field.
Plain English Explanation
The paper examines how we evaluate the ability of AI systems to understand referring expressions, which are phrases that identify specific objects or people in an image (e.g., "the girl in the blue hat"). As AI models have become more advanced, particularly those that can handle both text and visual information (known as "multimodal" models), the authors believe the current evaluation methods may not be capturing the full capabilities of these systems.
The paper reviews previous research on referring expression comprehension and discusses potential issues with existing datasets and metrics. It then proposes new approaches that the authors believe could provide a more comprehensive assessment of how well AI models can interpret and understand the meaning of referring expressions.
The key idea is to move beyond simply asking models to select the correct object from a set of options, and instead evaluate their ability to generate their own referring expressions or to reason about the broader context and relationships between objects in an image. This could give a better sense of how well the models truly comprehend the semantics and pragmatics of referring expressions.
Technical Explanation
The paper first reviews related work on referring expression comprehension (REC), highlighting the limitations of existing datasets and evaluation metrics. The authors argue that these approaches may not adequately capture the capabilities of modern, large-scale multimodal models, such as RELLA, RefuteBench, and Zero-Shot REC.
To address these issues, the authors propose several new evaluation approaches:
- Referring Expression Generation: Rather than just selecting the correct object, models could be asked to generate their own referring expressions for a given object.
- Relational Reasoning: Models could be evaluated on their ability to reason about the relationships between objects in an image and use that context to interpret referring expressions.
- Open-ended Evaluation: Instead of a forced-choice setting, models could be presented with an open-ended task, such as answering a broader question about an image that requires understanding the referring expressions.
The paper describes experiments designed to explore these new evaluation paradigms, including dataset creation and model architectures. The results suggest that these approaches can indeed provide a more nuanced and comprehensive assessment of REC capabilities compared to traditional methods.
Critical Analysis
The authors acknowledge several limitations and areas for further research. For example, the proposed evaluation approaches may be more resource-intensive and challenging to scale. Additionally, the paper does not fully address potential biases or shortcomings in the dataset creation process, which could still impact the validity of the results.
Another potential issue is the reliance on current large multimodal models, which may not fully capture the long-term evolution of REC capabilities as AI systems continue to advance. The authors encourage further research to explore the generalizability and robustness of these new evaluation methods as the field progresses.
Despite these caveats, the paper makes a compelling case for revisiting REC evaluation in the era of powerful multimodal AI models. The proposed approaches could lead to a better understanding of model capabilities and drive the development of more sophisticated and contextually-aware referring expression comprehension systems.
Conclusion
This paper argues that the evaluation of referring expression comprehension (REC) needs to evolve to keep pace with the advances in large multimodal AI models. The authors propose new evaluation methods, including referring expression generation, relational reasoning, and open-ended tasks, which they believe can provide a more comprehensive and nuanced assessment of model capabilities.
While the paper acknowledges potential limitations and areas for further research, it offers a valuable contribution to the field by encouraging the community to critically examine the suitability of existing REC evaluation approaches. Adopting these new methods could lead to the development of more robust and contextually-aware referring expression comprehension systems, with important implications for applications such as human-computer interaction, image retrieval, and scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revisiting Referring Expression Comprehension Evaluation in the Era of Large Multimodal Models
Jierun Chen, Fangyun Wei, Jinjing Zhao, Sizhe Song, Bohuai Wu, Zhuoxuan Peng, S. -H. Gary Chan, Hongyang Zhang
Referring expression comprehension (REC) involves localizing a target instance based on a textual description. Recent advancements in REC have been driven by large multimodal models (LMMs) like CogVLM, which achieved 92.44% accuracy on RefCOCO. However, this study questions whether existing benchmarks such as RefCOCO, RefCOCO+, and RefCOCOg, capture LMMs' comprehensive capabilities. We begin with a manual examination of these benchmarks, revealing high labeling error rates: 14% in RefCOCO, 24% in RefCOCO+, and 5% in RefCOCOg, which undermines the authenticity of evaluations. We address this by excluding problematic instances and reevaluating several LMMs capable of handling the REC task, showing significant accuracy improvements, thus highlighting the impact of benchmark noise. In response, we introduce Ref-L4, a comprehensive REC benchmark, specifically designed to evaluate modern REC models. Ref-L4 is distinguished by four key features: 1) a substantial sample size with 45,341 annotations; 2) a diverse range of object categories with 365 distinct types and varying instance scales from 30 to 3,767; 3) lengthy referring expressions averaging 24.2 words; and 4) an extensive vocabulary comprising 22,813 unique words. We evaluate a total of 24 large models on Ref-L4 and provide valuable insights. The cleaned versions of RefCOCO, RefCOCO+, and RefCOCOg, as well as our Ref-L4 benchmark and evaluation code, are available at https://github.com/JierunChen/Ref-L4.
Read more6/26/2024
0
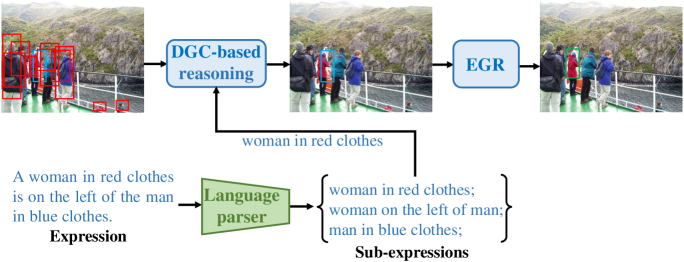
Make Graph-based Referring Expression Comprehension Great Again through Expression-guided Dynamic Gating and Regression
Jingcheng Ke, Dele Wang, Jun-Cheng Chen, I-Hong Jhuo, Chia-Wen Lin, Yen-Yu Lin
One common belief is that with complex models and pre-training on large-scale datasets, transformer-based methods for referring expression comprehension (REC) perform much better than existing graph-based methods. We observe that since most graph-based methods adopt an off-the-shelf detector to locate candidate objects (i.e., regions detected by the object detector), they face two challenges that result in subpar performance: (1) the presence of significant noise caused by numerous irrelevant objects during reasoning, and (2) inaccurate localization outcomes attributed to the provided detector. To address these issues, we introduce a plug-and-adapt module guided by sub-expressions, called dynamic gate constraint (DGC), which can adaptively disable irrelevant proposals and their connections in graphs during reasoning. We further introduce an expression-guided regression strategy (EGR) to refine location prediction. Extensive experimental results on the RefCOCO, RefCOCO+, RefCOCOg, Flickr30K, RefClef, and Ref-reasoning datasets demonstrate the effectiveness of the DGC module and the EGR strategy in consistently boosting the performances of various graph-based REC methods. Without any pretaining, the proposed graph-based method achieves better performance than the state-of-the-art (SOTA) transformer-based methods.
Read more9/6/2024

0
ScanFormer: Referring Expression Comprehension by Iteratively Scanning
Wei Su, Peihan Miao, Huanzhang Dou, Xi Li
Referring Expression Comprehension (REC) aims to localize the target objects specified by free-form natural language descriptions in images. While state-of-the-art methods achieve impressive performance, they perform a dense perception of images, which incorporates redundant visual regions unrelated to linguistic queries, leading to additional computational overhead. This inspires us to explore a question: can we eliminate linguistic-irrelevant redundant visual regions to improve the efficiency of the model? Existing relevant methods primarily focus on fundamental visual tasks, with limited exploration in vision-language fields. To address this, we propose a coarse-to-fine iterative perception framework, called ScanFormer. It can iteratively exploit the image scale pyramid to extract linguistic-relevant visual patches from top to bottom. In each iteration, irrelevant patches are discarded by our designed informativeness prediction. Furthermore, we propose a patch selection strategy for discarded patches to accelerate inference. Experiments on widely used datasets, namely RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame, verify the effectiveness of our method, which can strike a balance between accuracy and efficiency.
Read more6/27/2024

0
V-RECS, a Low-Cost LLM4VIS Recommender with Explanations, Captioning and Suggestions
Luca Podo, Marco Angelini, Paola Velardi
NL2VIS (natural language to visualization) is a promising and recent research area that involves interpreting natural language queries and translating them into visualizations that accurately represent the underlying data. As we navigate the era of big data, NL2VIS holds considerable application potential since it greatly facilitates data exploration by non-expert users. Following the increasingly widespread usage of generative AI in NL2VIS applications, in this paper we present V-RECS, the first LLM-based Visual Recommender augmented with explanations(E), captioning(C), and suggestions(S) for further data exploration. V-RECS' visualization narratives facilitate both response verification and data exploration by non-expert users. Furthermore, our proposed solution mitigates computational, controllability, and cost issues associated with using powerful LLMs by leveraging a methodology to effectively fine-tune small models. To generate insightful visualization narratives, we use Chain-of-Thoughts (CoT), a prompt engineering technique to help LLM identify and generate the logical steps to produce a correct answer. Since CoT is reported to perform poorly with small LLMs, we adopted a strategy in which a large LLM (GPT-4), acting as a Teacher, generates CoT-based instructions to fine-tune a small model, Llama-2-7B, which plays the role of a Student. Extensive experiments-based on a framework for the quantitative evaluation of AI-based visualizations and on manual assessment by a group of participants-show that V-RECS achieves performance scores comparable to GPT-4, at a much lower cost. The efficacy of the V-RECS teacher-student paradigm is also demonstrated by the fact that the un-tuned Llama fails to perform the task in the vast majority of test cases. We release V-RECS for the visualization community to assist visualization designers throughout the entire visualization generation process.
Read more8/1/2024